Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads 论文解读(VLDB 2021)
Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads 论文解读(VLDB 2021)
- 本篇博客是对发表在2021 VLDB上的# Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads的解读,原文链接为Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads (acm.org)
- 本文介绍了一种不受查询负载倾斜和数据相关性影响的基于学习的索引结构。
- 特点:
- 介绍了传统的多维索引结构(K-D树)、最近提出的基于学习的多维索引(FLOOD)和本文提出的多维索引结构(Tsunami)。
- 本文提出的索引结构可以基于数据和查询负载对索引结构进行调整,使之更加适用于当前的查询负载(传统的索引值是基于数据进行索引的构建)。
- 解决了目前基于学习的索引对于倾斜的查询负载和数据相关性强情景下的实效问题。
过滤表达式与索引
基于谓词过滤是任何现代数据库最基本的操作之一,加速过滤器表达式的执行可以显著提高数据库查询优化器的效率。过去常用的提高过滤效率的方法包括:聚集索引、多维索引及二级索引(选择度较高时)。但这些传统索引方法都难以调节,而且表现极不稳定。后续会
基于学习的多维索引方法(FLOOD,后文介绍)可以根据数据集和工作负载自动优化索引结构。但是对查询倾斜和数据相关度高的数据效果不是很乐观。
传统多维索引
k-d树
-
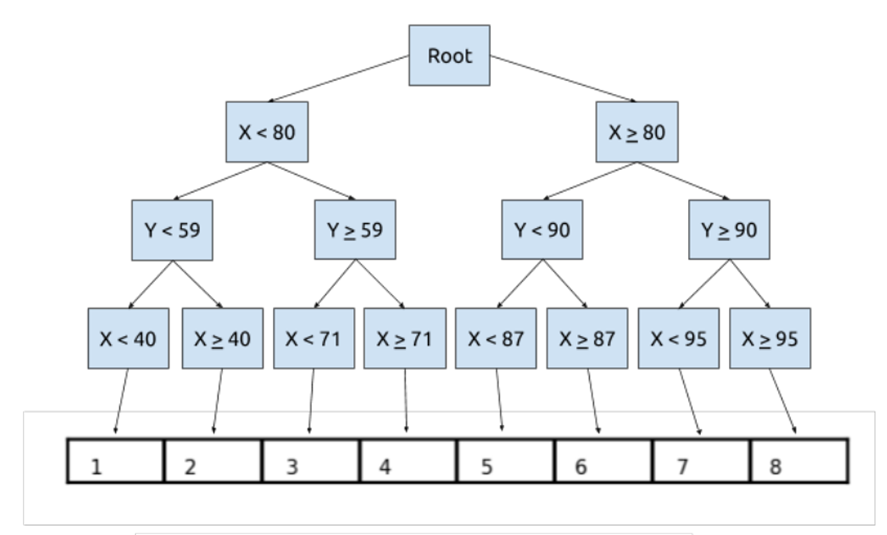
一种二叉空间分割树。在每个节点上基于不同维度的中值划分,直到每个叶子节点的点数少于一页的存储范围。每个叶子节点区域的点个数大致相等 如下图
-
k-d树缺点:只基于数据进行构建,没有考虑查询负载,有可能划分的大部分索引点都不会有查询经过造成大量空间的浪费。
二级索引
- 二级索引:叶子节点中存储主键值,每次查找数据时,根据索引找到叶子节点中的主键值,根据主键值再到聚簇索引中得到完整的一行记录。
- 缺点:占据空间过大。适用于选择度比较大的属性,否则空间代价过大且无用。
传统多维索引缺点:
- 索引结构难以调整,需要在创建索引时仔细选择需要用到的维度以及索引的顺序,每当数据或工作负载发生变化就要重新维护索引。
- 没有一种索引模式可以概况所有情况的索引。
基于学习的索引
FLOOD
-
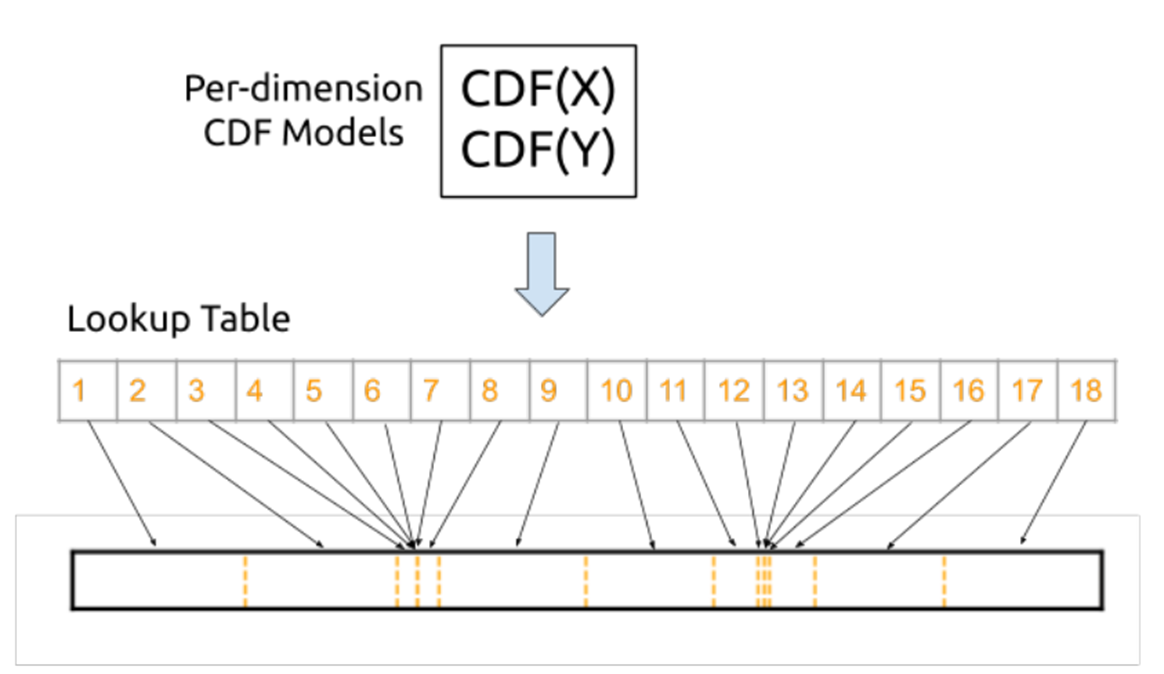
workflow:输入一个n维数据->CDF->divide into n partitions->n dimension grid->storage
-
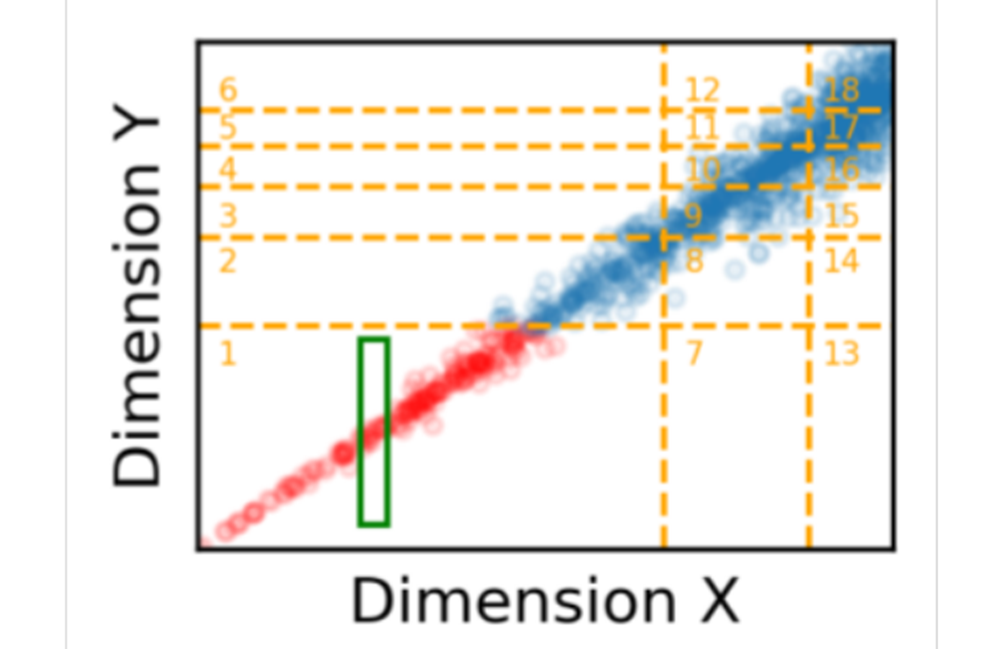
CDF:概率密度函数;根据CDF将每个维度分割成等量的k个部分(k是学习来的);n维数据,每个维度分成\(k_i\)个部分,互相交叉形成包括\(\prod_{k_i}\)个单元格的网格,每个单元格中包括满足各个属性范围的数据点。每个网格中的数据点都是连续存储的。
-
FLOOD优点:
- 可以根据查询负载动态的调整网格大小
- CDF模型对存储空间的消耗远远小于树形结构
-
FLOOD不足:
- FLOOD只参考平均查询频率来调整网格大小,当查询负载倾斜或查询不一致时,效率会大大降低。
- 当数据相关密切时,会导致各个单元格中的数据量差异较大,会降低索引的性能和存储空间使用率。
TSUNAMI
Tsunami的提出主要是为了解决FLOOD中对倾斜查询负载和处理相关数据时的效率下降问题。
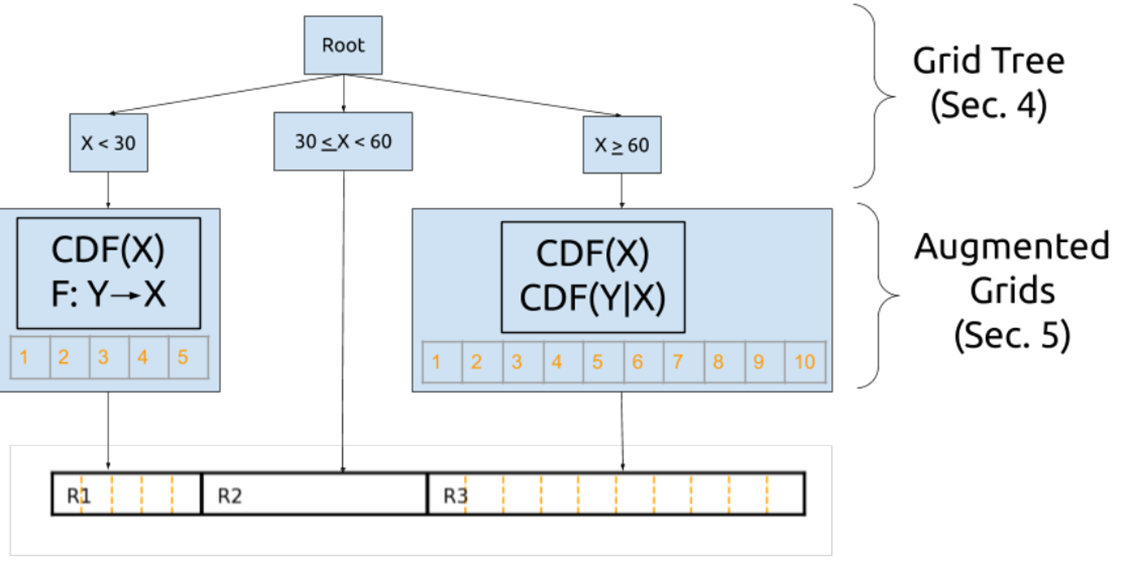
- 针对FLOOD对倾斜负载查询的不稳定性,Tsunami采用网格树的模式进行解决。
- 当查询特征在数据空间的不同部分有所不同,查询工作负载就会发生倾斜。解决方案:利用网格树将一个维度按查询分成多个不重合的部分
- 针对FLOOD对相关数据的不稳定性,Tsunami采用了增强网格进行解决。
- 基本想法与FLOOD基本一致。不同的是划分网格的依据。
(1)将当前属性视为独立属性,根据CDF(x)均匀分割
(2)如果X,Y存在单调映射,可以利用Y的过滤结果代替X的过滤结果
(3)用CDF(x|y)做均匀分割
(#^.^#)
(#^.^#)
(#^.^#)
(#^.^#)
(#^.^#)
(#^.^#)
(#^.^#)
(#^.^#)
(#^.^#)
觉得有帮助的话给笔者点个赞吧!O(∩_∩)O
- 基本想法与FLOOD基本一致。不同的是划分网格的依据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号