决策树知识总结
决策树笔记整理
算法原理
决策树是一种简单但是被广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。它有两个有点:(1)决策树模型可读性好,具有描述性,有助于人工分析;(2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
构建决策树的基本步骤
1.开始,将所有记录堪称一个节点 2.遍历记录的每种分割方式,找到最好的分割点 3.分割成两个节点N1和N2 4.对N1和N2继续执行2-3步,直到每个节点够纯
分割点的判断标准
如果一个分割点可以将当前所有的酒分为两类,使得每一类都很纯,即同一类的记录较多就是一个好的分割点。一般找分割后纯度增益最大分割点。
量化纯度
以上讲到,决策树的分支是根据纯度大小来构建的,下面介绍三中纯度的计算方法。如果一个问题的总记录被分为n类,第i类所占总数比例大小为:P(i) = 第i类记录数目/总记录数。
Gini不纯度
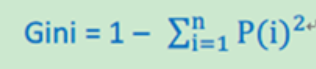
熵
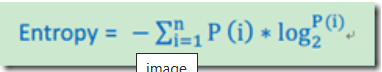
错误率
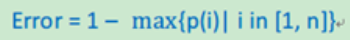
停止条件
决策树构建过程是一个递归过程,比较常见的停止条件是每个节点只有一种类型记录,但往往会导致节点过多,导致过拟合问题。比较好的方法是节点中的记录数低于某个阈值就停止分割,将该节点下最多类型的记录当做当前节点的分类。
过拟合问题
采用上面算法生成的决策树在事件中往往会导致过滤拟合。也就是该决策树对训练数据可以得到很低的错误率,但是运用到测试数据上却得到非常高的错误率。过渡拟合的原因有以下几点:
(1)噪音数据:训练数据中存在噪音数据,决策树的某些节点有噪音数据作为分割标准,导致决策树无法代表真实数据。
(2)缺少代表性数据:训练数据没有包含所有具有代表性的数据,导致某一类数据无法很好的匹配,这一点可以通过观察混淆矩阵(Confusion Matrix)分析得出。
(3)多重比较(Mulitple Comparition):举个列子,股票分析师预测股票涨或跌。假设分析师都是靠随机猜测,也就是他们正确的概率是0.5。每一个人预测10次,那么预测正确的次数在8次或8次以上的概率为 image,只有5%左右,比较低。但是如果50个分析师,每个人预测10次,选择至少一个人得到8次或以上的人作为代表,那么概率为 image,概率十分大,随着分析师人数的增加,概率无限接近1。但是,选出来的分析师其实是打酱油的,他对未来的预测不能做任何保证。上面这个例子就是多重比较。这一情况和决策树选取分割点类似,需要在每个变量的每一个值中选取一个作为分割的代表,所以选出一个噪音分割标准的概率是很大的。
优化方法
剪枝
决策树过渡拟合往往是因为太过“茂盛”,也就是节点过多,所以需要裁剪(Prune Tree)枝叶。裁剪枝叶的策略对决策树正确率的影响很大。主要有两种裁剪策略。
预剪枝
在构建决策树的过程时,提前停止。那么,会将切分节点的条件设置的很苛刻,导致决策树很短小。结果就是决策树无法达到最优。实践证明这中策略无法得到较好的结果。
后剪枝
决策树构建好后,然后才开始裁剪。采用两种方法:1)用单一叶节点代替整个子树,叶节点的分类采用子树中最主要的分类;2)将一个字数完全替代另外一颗子树。后置裁剪有个问题就是计算效率,有些节点计算后就被裁剪了,导致有点浪费。
随机森林
是用训练数据随机的计算出许多决策树,形成了一个森林。然后用这个森林对未知数据进行预测,选取投票最多的分类。实践证明,此算法的错误率得到了经一步的降低。这种方法背后的原理可以用“三个臭皮匠定一个诸葛亮”这句谚语来概括。一颗树预测正确的概率可能不高,但是集体预测正确的概率却很高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号