Python实现一个简单三层神经网络的搭建并测试
python实现一个简单三层神经网络的搭建(有代码)
废话不多说了,直接步入正题,一个完整的神经网络一般由三层构成:输入层,隐藏层(可以有多层)和输出层。本文所构建的神经网络隐藏层只有一层。一个神经网络主要由三部分构成(代码结构上):初始化,训练,和预测。首先我们先来初始化这个神经网络吧!
1.初始化
- 我们所要初始化的内容包括:神经网络每层上的神经元个数(这个是根据实际问题输入输出而得到的,我们将它设置为一个可自定义量)。
- 不同层间数据互相传送的权重值。
- 激活函数(模拟自然界的神经元,刺激信号需要达到一定的程度才能激活神经元)
下面上代码:
def __init__(self, input_nodes_num, hidden_nodes_num, output_nodes_num, lr): # 初始化神经元个数,可以直接修改 self.input_nodes = input_nodes_num self.hidden_nodes = hidden_nodes_num self.output_nodes = output_nodes_num self.learning_rate = lr # 初始化权重值,利用正态分布函数进行随机初始化,均值为0,方差为神经元个数开方 self.w_input_hidden = numpy.random.normal(0.0, pow(self.hidden_nodes, -0.5), (self.hidden_nodes, self.input_nodes)) self.w_hidden_output = numpy.random.normal(0.0, pow(self.output_nodes, -0.5), (self.output_nodes, self.hidden_nodes)) # 初始化激活函数,激活函数选用Sigmoid函数,更加平滑,接近自然界的神经元行为模式 # lambda定义了一个匿名函数 self.activation_function = lambda x: scipy.special.expit(x) pass
下面我们来解释一下上述代码段中的一些编程知识。首先是__init__()它是一个类的构造函数,在构建一个类的对象时会调用此函数,所以我们将神经网络初始化相关代码放到这个函数里。
self.w_input_hidden = numpy.random.normal(0.0, pow(self.hidden_nodes, -0.5),
(self.hidden_nodes, self.input_nodes))
这句代码使用了numpy库中的random.normal()函数,为输入层和隐藏层之间的数据传递初始化了权重值,这个函数会根据正态分布随机生成一个
self.hidden_nodes*self.input_nodes的矩阵(hidden_nodes和input_nodes表示隐藏层和输入层神经元的个数)。
self.activation_function = lambda x: scipy.special.expit(x)
这句代码使用lambda定义了一个匿名函数,将它赋值给激活函数,函数为sigmoid函数,是一条平滑的曲线,比较接近自然界神经元对于刺激信号的反应方式。
2.预测
按照正常顺序,初始化完成后应该进行训练,但由于训练较为复杂,且预测较为简单容易实现,我们先完成这一部分的代码。预测环节需要我们将输入信息进行处理,加权求和后传输给隐藏层神经元,经过激活函数并再次加权求和后,传输给输出层经过输出层神经元的处理得到最终的结果。代码片段如下:
def query(self, inputs_list): # 转置将行向量转成列向量,将每组数据更好的分隔开来,方便后续矩阵点乘操作 inputs = np.array(inputs_list, ndmin=2).T # 加权求和后经过sigmoid函数得到隐藏层输出 hidden_inputs = np.dot(self.w_input_hidden, inputs) hidden_outputs = self.activation_function(hidden_inputs) # 加权求和后经过sigmoid函数得到最终输出 final_inputs = np.dot(self.w_hidden_output, hidden_outputs) final_outputs = self.activation_function(final_inputs) # 得到输出数据列 return final_outputs
这段代码没有什么好说的,比较简单,只需按照笔者上述的步骤做即可。有什么不懂的可以看注释或者留下评论。
3.训练
神经网络的训练问题较为复杂,涉及到神经网络的正向和反向传播,微积分的链式法则,矩阵运算,偏微分求导和梯度下降算法的一些知识,都是机器学习的一些基础知识,在这里就不做过多的赘述,过几天我会新发一篇详细讲一下。下面来了解一下训练代码段的主要任务:
- 训练和预测一样都要首先读入一些输入并预测输出,不同的是,训练阶段我们是从训练数据集中获取数据,我们知道正确的输出是什么,而预测阶段我们只知道输入而输出需要通过我们训练的模型预测出来。首先训练阶段读入输入并按照当前的模型对其进行预测。
- 基于训练预测结果和标注好的实际结果的误差更新各个层之间的权值。
下面来贴代码:
def train(self, inputs_list, targets_list): # 将训练集和测试集中的数据转化为列向量 inputs = np.array(inputs_list, ndmin=2).T targets = np.array(targets_list, ndmin=2).T # 隐藏层的输入为训练集与权重值的点乘,输出为激活函数的输出 hidden_inputs = np.dot(self.w_input_hidden, inputs) hidden_outputs = self.activation_function(hidden_inputs) # 输出层的输入为隐藏层的输出,输出为最终结果 final_inputs = np.dot(self.w_hidden_output, hidden_outputs) final_outputs = self.activation_function(final_inputs) # 损失函数 output_errors = targets - final_outputs # 隐藏层的误差为权值矩阵的转置与输出误差的点乘 hidden_errors = np.dot(self.w_hidden_output.T, output_errors) # 对权值进行更新 self.w_hidden_output += self.learning_rate * np.dot((output_errors * final_outputs * (1.0 - final_outputs)), np.transpose(hidden_outputs)) self.w_input_hidden += self.learning_rate * np.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)), np.transpose(inputs))
上述代码段可能对于一些刚接触机器学习或深度学习的同学来说可能有点不知所云或产生一种好复杂的感觉,但是这只是对反向传播算法,链式法则和偏导的综合应用。我会在另一篇随笔中讲述我的心得(可能讲得不好),感兴趣的可以看一下。
4.测试
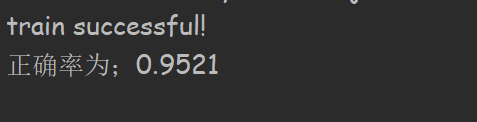
三层神经网络构建完成,我用mnist训练集和测试集对其进行了测试,代码及结果如下:
# 初始化各层神经元个数,期中输入神经元个数取决于读入的因变量,而输出神经元个数取决于分类的可能性个数 input_nodes = 784 hidden_nodes = 100 output_nodes = 10 # 学习率,每次调整步幅大小 learning_rate = 0.2 n = NeuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate) # 获取训练集信息 training_data_file = open('data/mnist_train.csv', 'r') training_data_list = training_data_file.readlines() training_data_file.close() for record in training_data_list: all_values = record.split(',') inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01 targets = numpy.zeros(output_nodes) + 0.01 targets[int(all_values[0])] = 0.99 n.train(inputs, targets) pass print('train successful!') test_file = open('data/mnist_test.csv', 'r') test_list = test_file.readlines() test_file.close() m = np.size(test_list) j = 0.0 for record in test_list: test_values = record.split(',') np.asfarray(test_values) results = n.query(np.asfarray(test_values[1:])) if results[int(test_values[0])] == max(results): j += 1 pass print("正确率为;" + str(j/m))
觉得此篇文章有用的给笔者留个点赞吖\(^o^)/~
有什么不懂的或者代码资源评论区留言\(^o^)/~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号