从零开始的机器学习(一)
从零开始的机器学习(一)
笔者理解的机器学习
对于一些正常的可执行程序来说,它们的执行都是遵照着一种非常规范的行为模式,如程序员在编写程序时的顺序语句、循环判别或者是较为复杂的一些特定算法的设计,种类各样但归根结底,计算机都是在有条不紊的执行我们输给计算机的在一些特定规则下的特定指令。而打破这种行为模式,只给计算机一些模糊的概念、特征,即机器学习中所说的训练集,让机器自己去构造所谓的行为模式,而不是提前明确,这种机器行为模式我们便称为机器学习。这些模式模糊到即便是编写某个机器学习的程序员,都不知道机器是如何运行而得到其目标结果的。
机器学习类别
监督学习:训练集中明确告知了所谓的正确答案,即训练数据存在所谓的属性或是标签。
无监督学习:无属性或是标签概念,仅有一个数据集,由机器自动判别相关的类别,例如:组织大型计算机群,社交网络(仅仅给出每个人及他们的联系对象),市场分割(仅仅给出不同人的消费水平),和天文数据的分析等。
强化学习:强调如何基于环境行动来取得最大的效益。
单变量线性回归
假设函数:hθ=θ0 +θ1x (线性回归方程)
| Training Set |
| Learning Algorithm |
x→h→y
笔者理解,机器学习实际就是选择合适的模型并根据我们能找到嗷的训练集进行训练,得到最优参数的过程。
线性回归中有一组训练集,即一组x、y元组对。我们需要得到θ0、θ1 所表示的直线尽可能的与数据集拟合,即输入x时得到的y值与直线最接近,即![]() 我们想得到一组θ值使这个式子得到最小。在机器学习中我们将模型得出的结果与实际值的差称为损失函数,而上述式子称为代价函数,又称平方误差函数。
我们想得到一组θ值使这个式子得到最小。在机器学习中我们将模型得出的结果与实际值的差称为损失函数,而上述式子称为代价函数,又称平方误差函数。
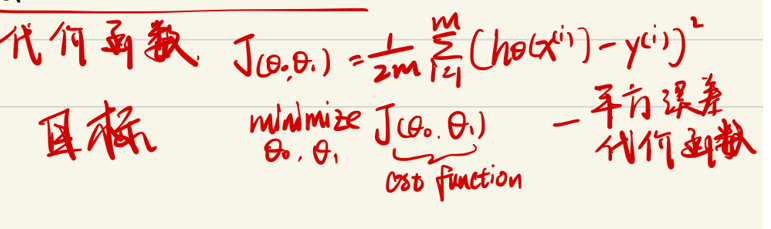
梯度下降算法
梯度是微积分的相关知识,笔者这里简单来说,一个函数的梯度方向是其最速上升方向,因此梯度对于求解函数最优化问题十分重要,我们可以沿着函数梯度的正或负方向不断趋近某个极大或极小值点。梯度下降基本流程如下:



θj的推导公式中α代表每次沿梯度方向探索的步长,在机器学习中称为学习率(Learning Rate)。
多元线性回归梯度下降算法


特征缩放
如果一个机器学习问题有多个特征值,那么确保不同特征值的取值在相似的范围内,这样梯度下降算法就能更快的收敛。这句话不难理解如果一个机器问题某一个特征值取值在(0,1),而另一个特征值取值在(0,100000),那么若将它画出来我们会得到一个过于狭长的图形,这样如果我们不断的横向调节参数,它就会在某些不重要的地方来回跳跃,大大延长了算法收敛的时间。
遇到这种情况,我们可以适当将某些较大的特征值除一些系数,将其缩小范围至和其他的特征值范围相似。通常我们将特征值的取值范围约束在(-1,1),除了缩放某些较大的特征值外,我们还可以对特征值进行均值归一化,即将每种特征值xi用(xi-μ)/s 来代替,即: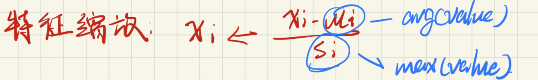
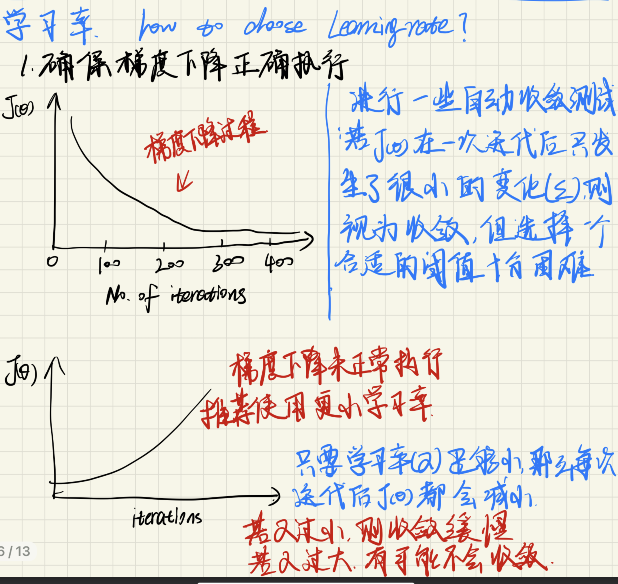
学习率(偷个懒\(^o^)/~)
正规方程
对于多变量线性回归问题,除了梯度下降的算法求解外,我们还可以用一种解析解法直接求解θ的最优值即正规方程,使用正规方程就没有收敛问题,因此无需进行学习率和特征缩放的选择操作等问题。如下图介绍: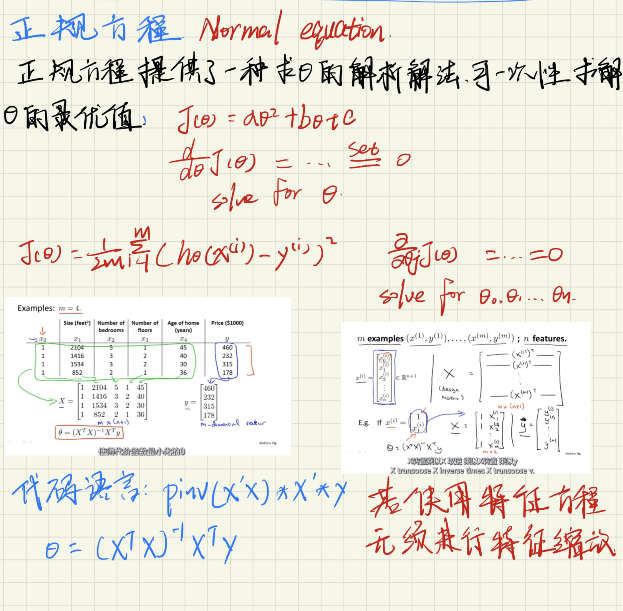
路过给笔者点个赞吧\(^o^)/~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号