DeepDB:Learn From Data,not from Queries!
ABSTRACT
DBMS典型学习方法的弊端:手机数据集的成本过高;工作方向或数据库发生改变时,必须重新收集数据。--------------解决:提出了一种新的数据驱动方式,直接支持工作负载和数据库的变化。
1.INTRODUCTION
深度神经网络应用于DBMS,其中DNN已经被用于替换现有的DBMS组件,如学习的成本模型,学习的查询优化器模型,学习的索引或学习的调度和查询处理方案。
学习DBMS组件的主要方法:在给定的数据库中运行一组具有代表性的查询(query)来捕获组件的行为,并使用捕获的结果来训练模型。这种方法需要执行足够的查询来手机训练数据,并且这种训练数据的收集并非一次性的工作,而是要动态的重复,否则模型的精确度将下降。
本文贡献:提出一个纯数据驱动的模型,而不是在某一工作环境下学习模型。该模型捕捉数据的概率分布,跨属性相关性及单个属性的数据分布。该模型支持直接更新,对于数据库的一些修改可直接被模型吸收而不需要重新训练。并且由于该模型直接捕获数据的信息,因此它可以应用于多种不同的任务,如查询,参数估计等一些非固定的任务,如DBMS机器学习推理等。与主流观点不同,该模型的方法由于许多先进的基于工作负载的驱动方法。归纳如下:
- 提出了一类新的数据库深度概率模型:关系和积网络(RSPNs),它能够捕捉数据库的重要特征。
- 为了支持不同的任务,我们设计了一种概率查询编译方法,将输入的数据库查询转换为RSPN的概率和期望。
- 我们在一个称为DeepDB的原型DBMS体系结构中实现了我们的数据驱动方法,并用现有的已学习和未学习的方法对其进行了评估。
2.OVERVIEW AND APPLICATIONS
如下图,DeepDB主要思想是离线学习数据表示特征,并不是用模型取代原始数据,相反,DeepDB中的一个模型增强了一个类似于索引的数据库,以加快查询速度并提供额外的查询功能,同时仍然可以在原始数据库上运行标准的SQL查询。
为了最优地捕获DeepDB中关系数据的相关特征,我们开发了一种新的模型,称为关系和积网络(RSPNs)。简而言之,RSPN是一类深度概率模型,它捕获数据库中所有属性的联合概率分布,然后可以在运行时使用它们来为不同的用户任务提供答案。
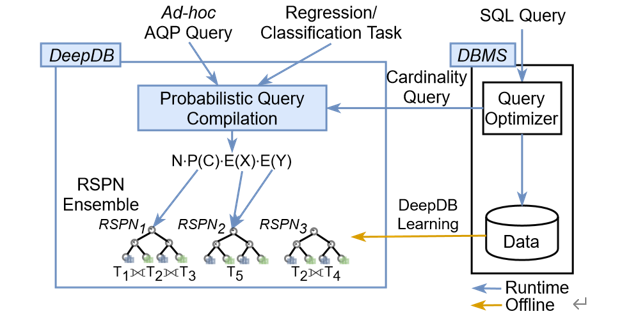
Ad-hoc Query:即席查询---------是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表。即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询是由用户自定义查询条件的。在这里表示用户自定义合法的查询语句
AQP:近似查询处理
Regression/Classification Task:回归/分类任务
Probabilistic Query Compilation:概率查询组件
RSPN:深度概率模型
DeepDB支持的应用:基数估计,近似查询处理
3.LEARNING A DEEP DATA MODEL
3.1Sum Product Networks(和积网络)
和积网络(SPNs)学习数据集中变量的联合概率分布,可以非常有效的计算任意条件的概率,在基数估计和AQP中我们可以使用到这些概率。
为了简单起见,我们将我们的注意力限制在树-SPN上,即以和结点和积结点作为内部结点和叶子的树。直观地说,求和节点将总体(即数据集的行)拆分为簇,乘积节点将总体的自变量(即数据集的列)拆分为簇。叶节点表示单个属性。
如下图c中对应的客户表的变量区域和年龄学习SPN。中顶部的sum节点将数据分成两组:左边的组包含30%的人口,由年龄较大的欧洲客户(对应于表的第一行)主导,右边的组包含70%的人口,拥有年轻的亚洲客户(对应于表的最后几行)。在这两个组中,区域和年龄是独立的,因此每个组由一个产品节点分开。叶节点决定了每个群体的变量、区域和年龄的概率分布。
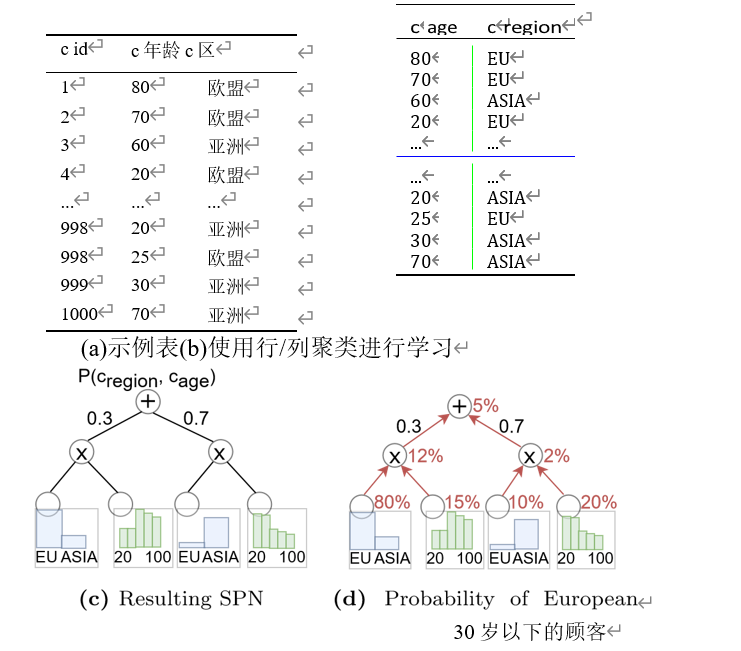
学习SPNs是通过递归地将数据拆分到不同的行簇(引入一个和节点)或独立列簇(引入一个积节点)中来实现的。对于行的聚类,可以使用KMeans之类的标准算法,也可以根据随机超平面拆分数据。为了不对底层分布做出强有力的假设,随机依赖系数(RDC)被用于测试不同列的独立性。此外,一旦集群中的行数低于阈值nmin,所有列之间就会假设独立。
有了SPN,就可以计算任意列上条件的概率。直观地说,条件首先在每一个相关的叶子上进行评估。然后,对SPN进行自下而上的评估。例如,在上图d中,为了估计有多少客户来自欧洲且年龄小于30岁,我们计算相应的蓝色区域叶节点中欧洲客户的概率(80%和10%)和绿色年龄叶节点中客户年龄小于30岁的概率(15%和20%)。然后在上面的乘积节点级将这些概率相乘,分别得到12%和2%的概率。最后,在根层(和节点),我们必须考虑簇的权重,这导致12%·0.3+2%·0.7=5%。乘以表中的行数,我们得到50个小于30岁的欧洲客户的近似值。
3.2 Relational Sum-Product Networks
SPN的一个重要问题是它们只能捕获单个表的数据,但它们也缺乏DeepDB所需的其他重要特性。为了缓解这些问题,文中引入了RSPN。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号