万字长文带你深入Redis底层数据结构
Redis数据库的数据结构
Redis 的键值对中的 key 就是字符串对象,而 value 就是指Redis的数据类型,可以是String,也可以是List、Hash、Set、 Zset 的数据类型。
其实是Redis 底层使用了一个全局哈希表保存所有键值对,哈希表的最大好处就是 O(1) 的时间复杂度快速查找到键值对。哈希表其实就是一个数组,数组中的元素叫做哈希桶。

- redisDb 结构,表示 Redis 数据库的结构,结构体里存放了指向了 dict 结构的指针;//默认有16个数据库
- dict 结构,结构体里存放了 2 个哈希表,正常情况下都是用
哈希表1,哈希表2只有在 rehash 的时候才用; - ditctht 结构,表示哈希表的结构,结构里存放了哈希表数组,数组中的每个元素都是指向一个哈希表节点结构(dictEntry)的指针;
- dictEntry 结构,表示哈希表节点的结构,结构里存放了
void* key和void* value指针, key 指向的是 String 对象,而 value 就是指Redis的几种数据类型。
struct redisServer {
//...
redisDb *db;
//...
int dbnum; //默认16个
}
typedef struct redisDb {
dict *dict; //全局hash表
//...
} redisDb;
struct dict {
//...
dictht ht[2]; //两个dictEntry,一个开始为空,rehash迁移时使用
//...
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
};
typedef struct dictht {
dictEntry **table; // 哈希表节点数组
unsigned long size; // 哈希表大小
unsigned long sizemask; // 哈希表大小掩码,用于计算索引值,总是等于size-1
unsigned long used; // 该哈希表已有节点的数量
} dictht;
struct dictEntry {//具体的对象
void *key; //key
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;//value
struct dictEntry *next; //下一个节点的指针
void *metadata[];
};
void *key 和 void *value 指针指向的就是 Redis 对象。Redis中有全局hash表,key是String,value是不同类型的对象,如果是Java,那可以直接用Map<String,Object>来通用表示。而Redis直接由C语言实现,因此具体的每个对象都由 redisObject 结构表示,用type来表示具体类型,如下:
typedef struct redisObject {
unsigned type: 4; // 对象类型
unsigned storage: 2; // REDIS_VM_MEMORY or REDIS_VM_SWAPPING
unsigned encoding: 4; // 对象所使用的编码
unsigned lru: 22; // lru time (relative to server.lruclock)
int refcount; // 对象的引用计数
void *ptr; // 指向对象的底层实现数据结构
} robj;
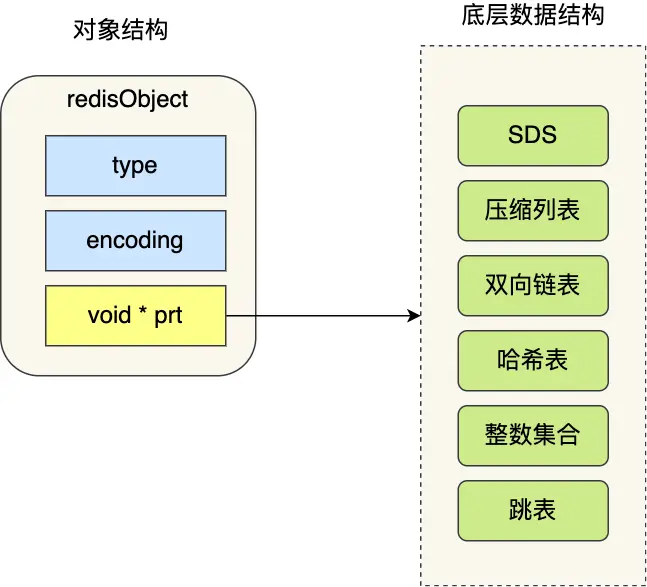
- type,标识该对象是什么类型的对象(String 对象、 List 对象、Hash 对象、Set 对象和 Zset 对象);
- encoding,标识该对象使用了哪种底层的数据结构;
- ptr,指向底层数据结构的指针。
如图,Redis 数据类型(也叫 Redis 对象)和底层数据结构的对应关图:
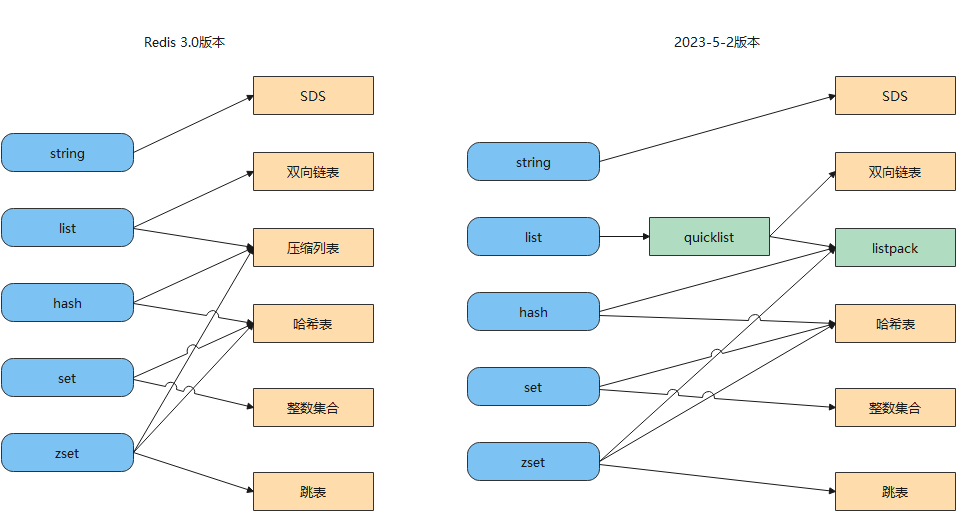
- 默认情况下hash使用listpack存储,当保存的字段-值的数量大于512个或者单个字段的值大于64个字节时,改为hashtable。
- 默认情况下zSet使用listpack做为存储结构,当集合中的元素大于等于128个或是单个值的字节数大于等于64,存储结构会修改为skiplist。
这几个值都是可以修改的,没必要记;在redis.conf里
hash-max-listpack-entries 512
hash-max-listpack-value 64
zset-max-listpack-entries 128
zset-max-listpack-value 64
SDS
Simple Dynamic String,简单动态字符串
C语言中的缺陷
获取字符串长度复杂度为O(n)
在 C 语言里,字符数组的结尾位置用“\0”表示,意思是指字符串的结束。
因此c语言获取字符串长度的函数 strlen,就是遍历字符数组中的每一个字符,遇到字符为 “\0” 后,就会停止遍历,然后返回已经统计到的字符个数,即为字符串长度,因此复杂度为O(n)
字符串只能保存文本数据
字符数组的结尾位置用“\0”表示
因此,除了字符串的末尾之外,字符串里面不能含有 “\0” 字符,否则最先被程序读入的 “\0” 字符将被误认为是字符串结尾,这个限制使得 C 语言的字符串只能保存文本数据,不能保存像图片、音频、视频文化这样的二进制数据
有可能发生缓冲区溢出
C 语言的字符串是不会记录自身的缓冲区大小的,所以 strcat 函数假定程序员在执行这个函数时,已经为 dest 分配了足够多的内存,可以容纳 src 字符串中的所有内容,而一旦这个假定不成立,就会发生缓冲区溢出将可能会造成程序运行终止。

SDS结构

- len,记录了字符串长度。这样获取字符串长度的时候,只需要返回这个成员变量值就行,时间复杂度只需要 O(1)。
- alloc,分配给字符数组的空间长度。这样在修改字符串的时候,可以通过 alloc - len 计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩容至执行修改所需的大小,然后才执行实际的修改操作。这样就不会发生缓冲区溢出
- flags,用来表示不同类型的 SDS。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。
- buf[],字符数组,用来保存实际数据。不仅可以保存字符串,也可以保存二进制数据。
SDS 的 API 使用二进制的方式来处理 SDS 存放在 buf[] 里的数据,使得 Redis 不仅可以保存文本数据,也可以保存任意格式的二进制数据。
SDS的动态其实指的就是动态扩容
hisds hi_sdsMakeRoomFor(hisds s, size_t addlen)
{
... ...
// s目前的剩余空间已足够,无需扩展,直接返回
if (avail >= addlen)
return s;
//获取目前s的长度
len = hi_sdslen(s);
sh = (char *)s - hi_sdsHdrSize(oldtype);
//扩展之后 s 至少需要的长度
newlen = (len + addlen);
//根据新长度,为s分配新空间所需要的大小
if (newlen < HI_SDS_MAX_PREALLOC)
//新长度<HI_SDS_MAX_PREALLOC 则分配所需空间*2的空间
//默认定义HI_SDS_MAX_PREALLOC为(1024*1024)即1M
newlen *= 2;
else
//否则,分配长度为目前长度+1MB
newlen += HI_SDS_MAX_PREALLOC;
...
}
// #define HI_SDS_MAX_PREALLOC (1024*1024)
- 如果所需的 sds 长度小于 1 MB,那么最后的扩容是按照翻倍扩容来执行的,即 2 倍的newlen
- 如果所需的 sds 长度超过 1 MB,那么最后的扩容长度应该是 newlen + 1MB。
双向链表
Redis中的链表是双向链表结构
typedef struct listNode {
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
} listNode;
不过,Redis 在 listNode 结构体基础上又封装了 list 这个数据结构;类似于Java定义了Node节点,同时再此基础上封装了LinkedList
typedef struct list {
//链表头节点
listNode *head;
//链表尾节点
listNode *tail;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void (*free)(void *ptr);
//节点值比较函数
int (*match)(void *ptr, void *key);
//链表节点数量
unsigned long len;
} list;
Redis的链表的优缺点与链表的优缺点一致
压缩列表
压缩列表是 Redis 为了节约内存而开发的,它是由连续内存块组成的顺序型数据结构,类似于数组。


压缩列表有四个重要字段:
- zlbytes,记录整个压缩列表占用对内存字节数;
- zltail,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
- zllen,记录压缩列表包含的节点数量;
- zlend,标记压缩列表的结束点,固定值 0xFF(十进制255)。
在压缩列表中,如果要查找定位第一个元素和最后一个元素,可以通过表头三个字段(zllen)的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了,因此压缩列表不适合保存过多的元素。
压缩列表节点(entry)的构成如下:
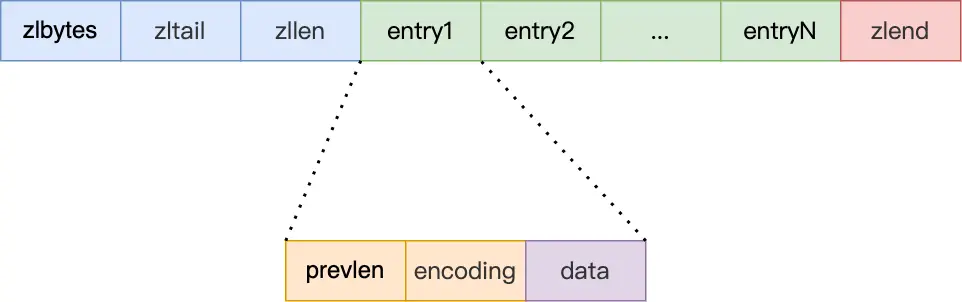
entry中的字段:
- prevlen,记录了前一个节点的长度,目的是为了实现从后向前遍历;
- encoding,记录了当前节点实际数据的类型和长度,类型主要有两种:字符串和整数。
- data,记录了当前节点的实际数据,类型和长度都由 encoding 决定;
往压缩列表中插入数据时,压缩列表会根据数据类型是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息,这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。
压缩列表里的每个节点中的 prevlen 属性都记录了前一个节点的长度,而且 prevlen 属性的空间大小跟前一个节点长度值有关,比如:
- 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
- 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
连锁更新
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。由于prevlen是前一个节点的长度,当新插入的元素较大时,那么就可能会导致后续元素的 prevlen 占用空间都发生变化(比如说1字节编程5字节),如果当前节点的prevlen属性从1字节变成5字节后导致下一个节点的prevlen属性也变大,那可能就会而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。

压缩列表的优缺点
优点:
- 根据数据大小和类型进行不同的空间大小分配来压缩内存空间
- 压缩列表是一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存(链表本身内存地址是不连续的,所以不能利用CPU缓存),而且会针对不同长度的数据,进行相应编码,这种方法可以有效地节省内存开销。
缺点:
- 不能保存过多的元素,否则查询效率就会降低;
- 新增或修改某个元素时,压缩列表占用的内存空间需要重新分配,甚至可能引发连锁更新的问题。
目前已被listpack替代
哈希表
全局哈希表 和 底层哈希表的对象都是使用的这个结构
哈希表中的节点结构
struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /* Next entry in the same hash bucket. */
void *metadata[];
};
dictEntry 结构里不仅包含指向键和值的指针,还包含了指向下一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对链接起来,以此来解决哈希冲突的问题,这就是链式哈希。
关于解决hash冲突问题可以看这篇文章:解决哈希冲突的三种方法
而redis是先通过拉链法解决,再通过rehash来解决hash冲突问题的,即再hash法
rehash
Redis 定义一个 dict 结构体,这个结构体里定义了两个哈希表(ht_table[2])。
struct dict {
//...
dictEntry **ht_table[2]; //两个dictEntry,一个开始为空,rehash迁移时使用
//...
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
};
在正常服务请求阶段,插入的数据,都会写入到哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多(根据负载因子判断),触发了 rehash 操作,这个过程分为如下三步:

如果哈希表 1的数据量非常大,那么在迁移至哈希表 2的时候,因为会涉及大量的数据拷贝,此时可能会对 Redis 造成阻塞,无法服务其他请求。因此redis采用了渐进式rehash
渐进式 rehash 步骤如下:
- 先给
哈希表 2分配空间; - 在 rehash 进行期间,每次哈希表元素进行新增、删除、查找或者更新操作时,Redis 除了会执行对应的操作之外,还会顺序将
哈希表 1中索引位置上的所有 key-value 迁移到哈希表 2上; - 随着处理客户端发起的哈希表操作请求数量越多,最终在某个时间点会把
哈希表 1的所有 key-value 迁移到哈希表 2,从而完成 rehash 操作。
这样就把一次性大量数据迁移工作的开销,分摊到了多次处理请求的过程中,避免了一次性 rehash 的耗时操作。
在进行渐进式 rehash 的过程中,会有两个哈希表,所以在渐进式 rehash 进行期间,哈希表元素的删除、查找、更新等操作都会在这两个哈希表进行。比如,在渐进式 rehash 进行期间,查找一个 key 的值的话,先会在哈希表 1里面进行查找,如果没找到,就会继续到哈希表 2 里面进行找到。新增一个 key-value 时,会被保存到哈希表 2里面,而哈希表 1则不再进行任何添加操作,这样保证了哈希表 1的 key-value 数量只会减少,随着 rehash 操作的完成,最终哈希表 1就会变成空表。
哈希表的查找过程:
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
if (dictSize(d) == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);//检查是否正在渐进式 rehash,如果是,那就rehash一步
h = dictHashKey(d, key);//计算key的hash值
//哈希表元素的删除、查找、更新等操作都会在两个哈希表进行
for (table = 0; table <= 1; table++) {
idx = h & DICTHT_SIZE_MASK(d->ht_size_exp[table]);
he = d->ht_table[table][idx];
while(he) {
void *he_key = dictGetKey(he);
if (key == he_key || dictCompareKeys(d, key, he_key))
return he;
he = dictGetNext(he);
}
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
关键在于哈希表插入时会去检查是都正在Rehash,如果不是,那就往0号hash表中插入;如果是,那就直接往1号hash表中插入,因为如果正在Rehash还往0号hash表中插入,那么最终还是要rehash到1号hash表的
int htidx = dictIsRehashing(d) ? 1 : 0;
rehash的触发条件
负载因子 = 哈希表已保存节点数量/哈希表大小
触发 rehash 操作的条件,主要有两个:
- 当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。
- 当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作
整数集合
当一个 Set 对象只包含整数值元素,并且元素数量不大时,就会使用整数集这个数据结构作为底层实现。
typedef struct intset {
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
} intset;
保存元素的容器是一个 contents 数组,虽然 contents 被声明为 int8_t 类型的数组,但是实际上 contents 数组并不保存任何 int8_t 类型的元素,contents 数组的真正类型取决于 intset 结构体里的 encoding 属性的值。比如:
- 如果 encoding 属性值为 INTSET_ENC_INT16,那么 contents 就是一个 int16_t 类型的数组,数组中每一个元素的类型都是 int16_t;
- 如果 encoding 属性值为 INTSET_ENC_INT32,那么 contents 就是一个 int32_t 类型的数组,数组中每一个元素的类型都是 int32_t;
- 如果 encoding 属性值为 INTSET_ENC_INT64,那么 contents 就是一个 int64_t 类型的数组,数组中每一个元素的类型都是 int64_t;
整数集合升级
将一个新元素加入到整数集合里面,如果新元素的类型(int32_t)比整数集合现有所有元素的类型(int16_t)都要长时,整数集合需要先进行升级,也就是按新元素的类型(int32_t)扩展 contents 数组的空间大小,然后才能将新元素加入到整数集合里,当然升级的过程中,也要维持整数集合的有序性。
整数集合升级的好处:
如果要让一个数组同时保存 int16_t、int32_t、int64_t 类型的元素,最简单做法就是直接使用 int64_t 类型的数组。不过这样的话,当如果元素都是 int16_t 类型的,就会造成内存浪费。
使用整数集合主要思想就是为了节省内存开销。
跳表
跳表的优势是能支持平均 O(logN) 复杂度的节点查找。
跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表,这样的好处是能快读定位数据。
typedef struct zskiplist {
//便于在O(1)时间复杂度内访问跳表的头节点和尾节点;
struct zskiplistNode *header, *tail;
//跳表的长度
unsigned long length;
//跳表的最大层数
int level;
} zskiplist;
typedef struct zskiplistNode {
//Zset 对象的元素值
sds ele;
//元素权重值
double score;
//后向指针,指向前一个节点,目的是为了方便从跳表的尾节点开始访问节点,方便倒序查找。
struct zskiplistNode *backward;
//节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
跳表结构如下:

跳表的相邻两层的节点数量最理想的比例是 2:1,查找复杂度可以降低到 O(logN)。
Redis中的跳表是两步两步跳的吗?
如果采用新增节点或者删除节点时,来调整跳表节点以维持比例2:1的方法的话,显然是会带来额外开销的。
跳表在创建节点时候,会生成范围为[0-1]的一个随机数,如果这个随机数小于 0.25(相当于概率 25%),那么层数就增加 1 层,然后继续生成下一个随机数,直到随机数的结果大于 0.25 结束,最终确定该节点的层数。因为随机数取值在[0,0.25)范围内概率不会超过25%,所以这也说明了增加一层的概率不会超过25%。这样的话,当插入一个新结点时,只需修改前后结点的指针,而其它结点的层数就不需要随之改变了,这样就降低插入操作的复杂度。
// #define ZSKIPLIST_P 0.25
int zslRandomLevel(void) {
static const int threshold = ZSKIPLIST_P*RAND_MAX;
int level = 1; //初始化为一级索引
while (random() < threshold)
level += 1;//随机数小于 0.25就增加一层
//如果level 没有超过最大层数就返回,否则就返回最大层数
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
为什么不用AVL树
- 在做范围查找的时候,跳表比AVL操作要简单。AVL在找到最小值后要中序遍历,跳表直接往后遍历就可
- 跳表实现上更简单。AVL的在插入和删除时可能会需要进行左旋右旋操作,带来额外的开销,而跳表的插入和删除只需要修改相邻节点的指针,操作更简单
listpack
listpack,目的是替代压缩列表,它最大特点是 listpack 中每个节点不再包含前一个节点的长度了,解决压缩列表的连锁更新问题
listpack 采用了压缩列表的很多优秀的设计,比如还是用一块连续的内存空间来紧凑地保存数据,并且为了节省内存的开销,listpack 节点与压缩列表一样采用不同的编码方式保存不同大小的数据

typedef struct {
/* When string is used, it is provided with the length (slen). */
unsigned char *sval;
uint32_t slen;
/* When integer is used, 'sval' is NULL, and lval holds the value. */
long long lval;
} listpackEntry;
- encoding,定义该元素的编码类型,会对不同长度的整数和字符串进行编码;
- data,实际存放的数据;
- len,encoding+data的总长度;
listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。
quicklist
目前版本的 quicklist 其实是 双向链表 + listpack 的组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个listpack。
typedef struct quicklist {
//quicklist的链表头
quicklistNode *head;
//quicklist的链表尾
quicklistNode *tail;
//所有listpacks中的总元素个数
unsigned long count; /* total count of all entries in all listpacks */
//quicklistNodes的个数
unsigned long len; /* number of quicklistNodes */
signed int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistEntry {
const quicklist *quicklist;
quicklistNode *node;
//指向listpack的指针
unsigned char *zi;
unsigned char *value;
long long longval;
size_t sz;
int offset;
} quicklistEntry;
typedef struct quicklistNode {
//前一个quicklistNode
struct quicklistNode *prev;
//下一个quicklistNode
struct quicklistNode *next;
unsigned char *entry;
//listpack的的字节大小
size_t sz; /* entry size in bytes */
//listpack列表的元素个数
unsigned int count : 16; /* count of items in listpack */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* PLAIN==1 or PACKED==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int dont_compress : 1; /* prevent compression of entry that will be used later */
unsigned int extra : 9; /* more bits to steal for future usage */
} quicklistNode;
BitMap
详情请看 位图,源码部分就不多做介绍了
HyperLogLog
HyperLogLog算法是一种非常巧妙的近似统计海量去重元素数量的算法。它内部维护了 16384 个桶(bucket)来记录各自桶的元素数量。当一个元素到来时,它会散列到其中一个桶,以一定的概率影响这个桶的计数值。因为是概率算法,所以单个桶的计数值并不准确,但是将所有的桶计数值进行调合均值累加起来,结果就会非常接近真实的计数值。
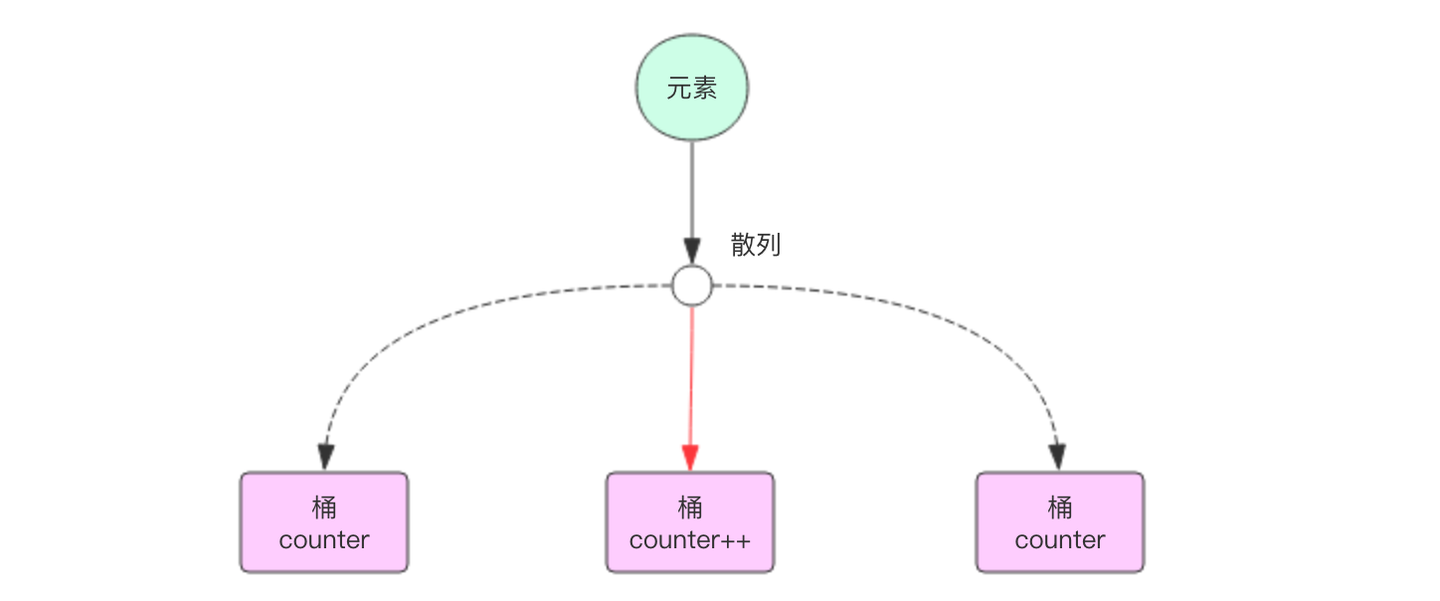
为了便于理解HyperLogLog算法,我们先简化它的计数逻辑。因为是去重计数,如果是准确的去重,肯定需要用到 set 集合,使用集合来记录所有的元素,然后使用 scard 指令来获取集合大小就可以得到总的计数。因为元素特别多,单个集合会特别大,所以将集合打散成 16384 个小集合。当元素到来时,通过 hash 算法将这个元素分派到其中的一个小集合存储,同样的元素总是会散列到同样的小集合。这样总的计数就是所有小集合大小的总和。使用这种方式精确计数除了可以增加元素外,还可以减少元素。
集合打散并没有什么明显好处,因为总的内存占用并没有减少。HyperLogLog肯定不是这个算法,它需要对这个小集合进行优化,压缩它的存储空间,让它的内存变得非常微小。HyperLogLog算法中每个桶所占用的空间实际上只有 6 个 bit,这 6 个 bit 自然是无法容纳桶中所有元素的,它记录的是桶中元素数量的对数值。
为了说明这个对数值具体是个什么东西,我们先来考虑一个小问题。一个随机的整数值,这个整数的尾部有一个 0 的概率是 50%,要么是 0 要么是 1。同样,尾部有两个 0 的概率是 25%,有三个零的概率是 12.5%,以此类推,有 k 个 0 的概率是 2^(-k)。如果我们随机出了很多整数,整数的数量我们并不知道,但是我们记录了整数尾部连续 0 的最大数量 K。我们就可以通过这个 K 来近似推断出整数的数量,这个数量就是 2^K。
当然结果是非常不准确的,因为可能接下来你随机了非常多的整数,但是末尾连续零的最大数量 K 没有变化,但是估计值还是 2^K。你也许会想到要是这个 K 是个浮点数就好了,每次随机一个新元素,它都可以稍微往上涨一点点,那么估计值应该会准确很多。
HyperLogLog通过分配 16384 个桶,然后对所有的桶的最大数量 K 进行调合平均来得到一个平均的末尾零最大数量 K# ,K# 是一个浮点数,使用平均后的 2^K# 来估计元素的总量相对而言就会准确很多。不过这只是简化算法,真实的算法还有很多修正因子,因为涉及到的数学理论知识过于繁多,这里就不再精确描述。
下面我们看看Redis HyperLogLog 算法的具体实现。我们知道一个HyperLogLog实际占用的空间大约是 13684 * 6bit / 8 = 12k 字节。但是在计数比较小的时候,大多数桶的计数值都是零。如果 12k 字节里面太多的字节都是零,那么这个空间是可以适当节约一下的。Redis 在计数值比较小的情况下采用了稀疏存储,稀疏存储的空间占用远远小于 12k 字节。相对于稀疏存储的就是密集存储,密集存储会恒定占用 12k 字节。
密集存储结构
不论是稀疏存储还是密集存储,Redis 内部都是使用字符串位图来存储 HyperLogLog 所有桶的计数值。密集存储的结构非常简单,就是连续 16384 个 6bit 串成的字符串位图。

那么给定一个桶编号,如何获取它的 6bit 计数值呢?这 6bit 可能在一个字节内部,也可能会跨越字节边界。我们需要对这一个或者两个字节进行适当的移位拼接才可以得到计数值。
假设桶的编号为idx,这个 6bit 计数值的起始字节位置偏移用 offset_bytes表示,它在这个字节的起始比特位置偏移用 offset_bits 表示。我们有
offset_bytes = (idx * 6) / 8
offset_bits = (idx * 6) % 8
前者是商,后者是余数。比如 bucket 2 的字节偏移是 1,也就是第 2 个字节。它的位偏移是4,也就是第 2 个字节的第 5 个位开始是 bucket 2 的计数值。需要注意的是字节位序是左边低位右边高位,而通常我们使用的字节都是左边高位右边低位,我们需要在脑海中进行倒置。
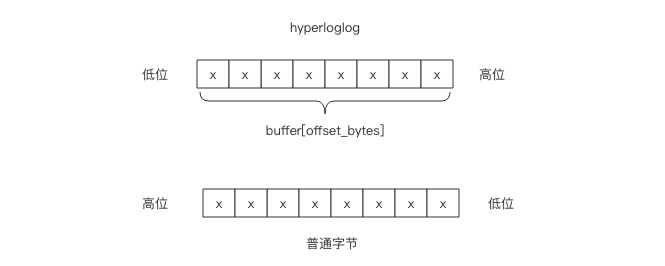
如果 offset_bits 小于等于 2,那么这 6bit 在一个字节内部,可以直接使用下面的表达式得到计数值 val
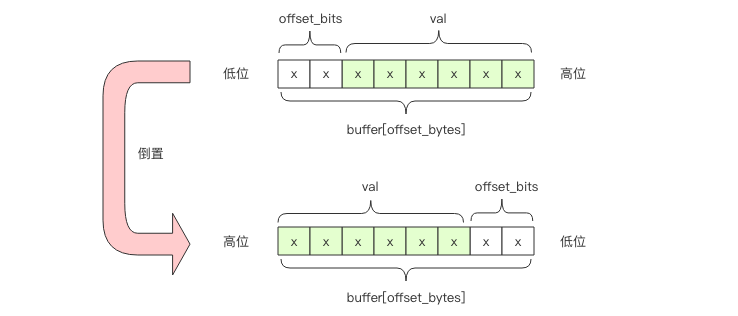
val = buffer[offset_bytes] >> offset_bits # 向右移位
如果 offset_bits 大于 2,那么就会跨越字节边界,这时需要拼接两个字节的位片段。
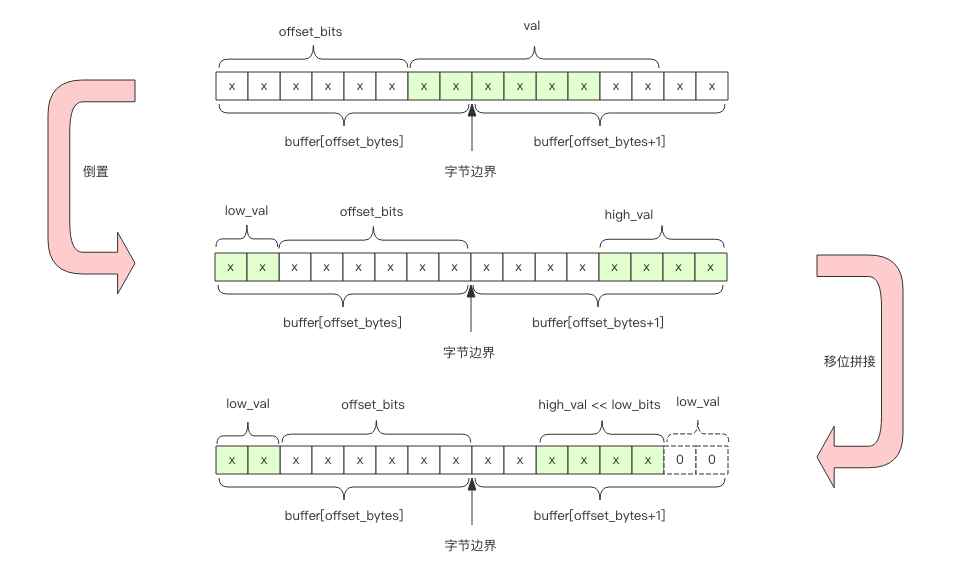
# 低位值
low_val = buffer[offset_bytes] >> offset_bits
# 低位个数
low_bits = 8 - offset_bits
# 拼接,保留低6位
val = (high_val << low_bits | low_val) & 0b111111
不过下面 Redis 的源码要晦涩一点,看形式它似乎只考虑了跨越字节边界的情况。这是因为如果 6bit 在单个字节内,上面代码中的 high_val 的值是零,所以这一份代码可以同时照顾单字节和双字节。
// 获取指定桶的计数值
#define HLL_DENSE_GET_REGISTER(target,p,regnum) do { \
uint8_t *_p = (uint8_t*) p; \
unsigned long _byte = regnum*HLL_BITS/8; \
unsigned long _fb = regnum*HLL_BITS&7; \ # %8 = &7
unsigned long _fb8 = 8 - _fb; \
unsigned long b0 = _p[_byte]; \
unsigned long b1 = _p[_byte+1]; \
target = ((b0 >> _fb) | (b1 << _fb8)) & HLL_REGISTER_MAX; \
} while(0)
// 设置指定桶的计数值
#define HLL_DENSE_SET_REGISTER(p,regnum,val) do { \
uint8_t *_p = (uint8_t*) p; \
unsigned long _byte = regnum*HLL_BITS/8; \
unsigned long _fb = regnum*HLL_BITS&7; \
unsigned long _fb8 = 8 - _fb; \
unsigned long _v = val; \
_p[_byte] &= ~(HLL_REGISTER_MAX << _fb); \
_p[_byte] |= _v << _fb; \
_p[_byte+1] &= ~(HLL_REGISTER_MAX >> _fb8); \
_p[_byte+1] |= _v >> _fb8; \
} while(0)
稀疏存储结构
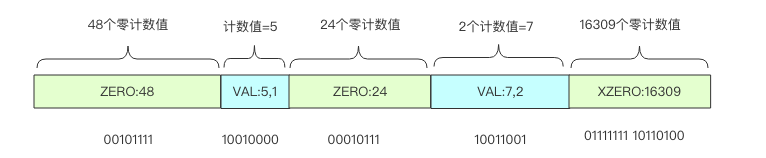
稀疏存储适用于很多计数值都是零的情况。下图表示了一般稀疏存储计数值的状态。

当多个连续桶的计数值都是零时,Redis 使用了一个字节来表示接下来有多少个桶的计数值都是零:00xxxxxx。前缀两个零表示接下来的 6bit 整数值加 1 就是零值计数器的数量,注意这里要加 1 是因为数量如果为零是没有意义的。比如 00010101表示连续 22 个零值计数器。6bit 最多只能表示连续 64 个零值计数器,所以 Redis 又设计了连续多个多于 64 个的连续零值计数器,它使用两个字节来表示:01xxxxxx yyyyyyyy,后面的 14bit 可以表示最多连续 16384 个零值计数器。这意味着 HyperLogLog 数据结构中 16384 个桶的初始状态,所有的计数器都是零值,可以直接使用 2 个字节来表示。
如果连续几个桶的计数值非零,那就使用形如 1vvvvvxx 这样的一个字节来表示。中间 5bit 表示计数值,尾部 2bit 表示连续几个桶。它的意思是连续 (xx +1) 个计数值都是 (vvvvv + 1)。比如 10101011 表示连续 4 个计数值都是 11。注意这两个值都需要加 1,因为任意一个是零都意味着这个计数值为零,那就应该使用零计数值的形式来表示。注意计数值最大只能表示到32,而 HyperLogLog 的密集存储单个计数值用 6bit 表示,最大可以表示到 63。当稀疏存储的某个计数值需要调整到大于 32 时,Redis 就会立即转换 HyperLogLog 的存储结构,将稀疏存储转换成密集存储。

Redis 为了方便表达稀疏存储,它将上面三种字节表示形式分别赋予了一条指令。
- ZERO:len 单个字节表示
00[len-1],连续最多64个零计数值 - VAL:value,len 单个字节表示
1[value-1][len-1],连续 len 个值为 value 的计数值 - XZERO:len 双字节表示
01[len-1],连续最多16384个零计数值
#define HLL_SPARSE_XZERO_BIT 0x40 /* 01xxxxxx */
#define HLL_SPARSE_VAL_BIT 0x80 /* 1vvvvvxx */
#define HLL_SPARSE_IS_ZERO(p) (((*(p)) & 0xc0) == 0) /* 00xxxxxx */
#define HLL_SPARSE_IS_XZERO(p) (((*(p)) & 0xc0) == HLL_SPARSE_XZERO_BIT)
#define HLL_SPARSE_IS_VAL(p) ((*(p)) & HLL_SPARSE_VAL_BIT)
#define HLL_SPARSE_ZERO_LEN(p) (((*(p)) & 0x3f)+1)
#define HLL_SPARSE_XZERO_LEN(p) (((((*(p)) & 0x3f) << 8) | (*((p)+1)))+1)
#define HLL_SPARSE_VAL_VALUE(p) ((((*(p)) >> 2) & 0x1f)+1)
#define HLL_SPARSE_VAL_LEN(p) (((*(p)) & 0x3)+1)
#define HLL_SPARSE_VAL_MAX_VALUE 32
#define HLL_SPARSE_VAL_MAX_LEN 4
#define HLL_SPARSE_ZERO_MAX_LEN 64
#define HLL_SPARSE_XZERO_MAX_LEN 16384
上图可以使用指令形式表示如下
Redis从稀疏存储转换到密集存储的条件是:
- 任意一个计数值从 32 变成 33,因为VAL指令已经无法容纳,它能表示的计数值最大为 32
- 稀疏存储占用的总字节数超过 3000 字节,这个阈值可以通过 hll_sparse_max_bytes 参数进行调整。
计数缓存
前面提到 HyperLogLog 表示的总计数值是由 16384 个桶的计数值进行调和平均后再基于因子修正公式计算得出来的。它需要遍历所有的桶进行计算才可以得到这个值,中间还涉及到很多浮点运算。这个计算量相对来说还是比较大的。
所以 Redis 使用了一个额外的字段来缓存总计数值,这个字段有 64bit,最高位如果为 1 表示该值是否已经过期,如果为 0, 那么剩下的 63bit 就是计数值。
当 HyperLogLog 中任意一个桶的计数值发生变化时,就会将计数缓存设为过期,但是不会立即触发计算。而是要等到用户显示调用 pfcount 指令时才会触发重新计算刷新缓存。缓存刷新在密集存储时需要遍历 16384 个桶的计数值进行调和平均,但是稀疏存储时没有这么大的计算量。也就是说只有当计数值比较大时才可能产生较大的计算量。另一方面如果计数值比较大,那么大部分 pfadd 操作根本不会导致桶中的计数值发生变化。
这意味着在一个极具变化的 HLL 计数器中频繁调用 pfcount 指令可能会有少许性能问题。关于这个性能方面的担忧在 Redis 作者 antirez 的博客中也提到了。不过作者做了仔细的压力的测试,发现这是无需担心的,pfcount 指令的平均时间复杂度就是 O(1)。
After this change even trying to add elements at maximum speed using a pipeline of 32 elements with 50 simultaneous clients, PFCOUNT was able to perform as well as any other O(1) command with very small constant times.
源码解析
接下来通过源码来看一下pfadd和pfcount两个命令的具体流程。在这之前我们首先要了解的是HyperLogLog的头结构体和创建一个HyperLogLog对象的步骤。
HyperLogLog头结构体
struct hllhdr {
char magic[4]; /* "HYLL" */
uint8_t encoding; /* HLL_DENSE or HLL_SPARSE. */
uint8_t notused[3]; /* Reserved for future use, must be zero. */
uint8_t card[8]; /* Cached cardinality, little endian. */
uint8_t registers[]; /* Data bytes. */
};
创建HyperLogLog对象
#define HLL_P 14 /* The greater is P, the smaller the error. */
#define HLL_REGISTERS (1<<HLL_P) /* With P=14, 16384 registers. */
#define HLL_SPARSE_XZERO_MAX_LEN 16384
#define HLL_SPARSE_XZERO_SET(p,len) do { \
int _l = (len)-1; \
*(p) = (_l>>8) | HLL_SPARSE_XZERO_BIT; \
*((p)+1) = (_l&0xff); \
} while(0)
/* Create an HLL object. We always create the HLL using sparse encoding.
* This will be upgraded to the dense representation as needed. */
robj *createHLLObject(void) {
robj *o;
struct hllhdr *hdr;
sds s;
uint8_t *p;
int sparselen = HLL_HDR_SIZE +
(((HLL_REGISTERS+(HLL_SPARSE_XZERO_MAX_LEN-1)) /
HLL_SPARSE_XZERO_MAX_LEN)*2);
int aux;
/* Populate the sparse representation with as many XZERO opcodes as
* needed to represent all the registers. */
aux = HLL_REGISTERS;
s = sdsnewlen(NULL,sparselen);
p = (uint8_t*)s + HLL_HDR_SIZE;
while(aux) {
int xzero = HLL_SPARSE_XZERO_MAX_LEN;
if (xzero > aux) xzero = aux;
HLL_SPARSE_XZERO_SET(p,xzero);
p += 2;
aux -= xzero;
}
serverAssert((p-(uint8_t*)s) == sparselen);
/* Create the actual object. */
o = createObject(OBJ_STRING,s);
hdr = o->ptr;
memcpy(hdr->magic,"HYLL",4);
hdr->encoding = HLL_SPARSE;
return o;
}
这里sparselen=HLL_HDR_SIZE+2,因为初始化时默认所有桶的计数值都是0。其他过程不难理解,用的存储方式是我们前面提到过的稀疏存储,创建的对象实质上是一个字符串对象,这也是字符串命令可以操作HyperLogLog对象的原因。
PFADD命令
/* PFADD var ele ele ele ... ele => :0 or :1 */
void pfaddCommand(client *c) {
robj *o = lookupKeyWrite(c->db,c->argv[1]);
struct hllhdr *hdr;
int updated = 0, j;
if (o == NULL) {
/* Create the key with a string value of the exact length to
* hold our HLL data structure. sdsnewlen() when NULL is passed
* is guaranteed to return bytes initialized to zero. */
o = createHLLObject();
dbAdd(c->db,c->argv[1],o);
updated++;
} else {
if (isHLLObjectOrReply(c,o) != C_OK) return;
o = dbUnshareStringValue(c->db,c->argv[1],o);
}
/* Perform the low level ADD operation for every element. */
for (j = 2; j < c->argc; j++) {
int retval = hllAdd(o, (unsigned char*)c->argv[j]->ptr,
sdslen(c->argv[j]->ptr));
switch(retval) {
case 1:
updated++;
break;
case -1:
addReplySds(c,sdsnew(invalid_hll_err));
return;
}
}
hdr = o->ptr;
if (updated) {
signalModifiedKey(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"pfadd",c->argv[1],c->db->id);
server.dirty++;
HLL_INVALIDATE_CACHE(hdr);
}
addReply(c, updated ? shared.cone : shared.czero);
}
PFADD命令会先判断key是否存在,如果不存在,则创建一个新的HyperLogLog对象;如果存在,会调用isHLLObjectOrReply()函数检查这个对象是不是HyperLogLog对象,检查方法主要是检查魔数是否正确,存储结构是否正确以及头结构体的长度是否正确等。
一切就绪后,才可以调用hllAdd()函数添加元素。hllAdd函数很简单,只是根据存储结构判断需要调用hllDenseAdd()函数还是hllSparseAdd()函数。
密集存储结构只是比较新旧计数值,如果新计数值大于就计数值,就将其替代。
而稀疏存储结构要复杂一些:
- 判断是否需要调整为密集存储结构,如果不需要则继续进行,否则就先调整为密集存储结构,然后执行添加操作
- 我们需要先定位要修改的字节段,通过循环计算每一段表示的桶的范围是否包括要修改的桶
- 定位到桶后,如果这个桶已经是VAL,并且计数值大于当前要添加的计数值,则返回0,如果小于当前计数值,就进行更新
- 如果是ZERO,并且长度为1,那么可以直接把它替换为VAL,并且设置计数值
- 如果不是上述两种情况,则需要对现有的存储进行拆分
PFCOUNT命令
/* PFCOUNT var -> approximated cardinality of set. */
void pfcountCommand(client *c) {
robj *o;
struct hllhdr *hdr;
uint64_t card;
/* Case 1: multi-key keys, cardinality of the union.
*
* When multiple keys are specified, PFCOUNT actually computes
* the cardinality of the merge of the N HLLs specified. */
if (c->argc > 2) {
uint8_t max[HLL_HDR_SIZE+HLL_REGISTERS], *registers;
int j;
/* Compute an HLL with M[i] = MAX(M[i]_j). */
memset(max,0,sizeof(max));
hdr = (struct hllhdr*) max;
hdr->encoding = HLL_RAW; /* Special internal-only encoding. */
registers = max + HLL_HDR_SIZE;
for (j = 1; j < c->argc; j++) {
/* Check type and size. */
robj *o = lookupKeyRead(c->db,c->argv[j]);
if (o == NULL) continue; /* Assume empty HLL for non existing var.*/
if (isHLLObjectOrReply(c,o) != C_OK) return;
/* Merge with this HLL with our 'max' HHL by setting max[i]
* to MAX(max[i],hll[i]). */
if (hllMerge(registers,o) == C_ERR) {
addReplySds(c,sdsnew(invalid_hll_err));
return;
}
}
/* Compute cardinality of the resulting set. */
addReplyLongLong(c,hllCount(hdr,NULL));
return;
}
/* Case 2: cardinality of the single HLL.
*
* The user specified a single key. Either return the cached value
* or compute one and update the cache. */
o = lookupKeyWrite(c->db,c->argv[1]);
if (o == NULL) {
/* No key? Cardinality is zero since no element was added, otherwise
* we would have a key as HLLADD creates it as a side effect. */
addReply(c,shared.czero);
} else {
if (isHLLObjectOrReply(c,o) != C_OK) return;
o = dbUnshareStringValue(c->db,c->argv[1],o);
/* Check if the cached cardinality is valid. */
hdr = o->ptr;
if (HLL_VALID_CACHE(hdr)) {
/* Just return the cached value. */
card = (uint64_t)hdr->card[0];
card |= (uint64_t)hdr->card[1] << 8;
card |= (uint64_t)hdr->card[2] << 16;
card |= (uint64_t)hdr->card[3] << 24;
card |= (uint64_t)hdr->card[4] << 32;
card |= (uint64_t)hdr->card[5] << 40;
card |= (uint64_t)hdr->card[6] << 48;
card |= (uint64_t)hdr->card[7] << 56;
} else {
int invalid = 0;
/* Recompute it and update the cached value. */
card = hllCount(hdr,&invalid);
if (invalid) {
addReplySds(c,sdsnew(invalid_hll_err));
return;
}
hdr->card[0] = card & 0xff;
hdr->card[1] = (card >> 8) & 0xff;
hdr->card[2] = (card >> 16) & 0xff;
hdr->card[3] = (card >> 24) & 0xff;
hdr->card[4] = (card >> 32) & 0xff;
hdr->card[5] = (card >> 40) & 0xff;
hdr->card[6] = (card >> 48) & 0xff;
hdr->card[7] = (card >> 56) & 0xff;
/* This is not considered a read-only command even if the
* data structure is not modified, since the cached value
* may be modified and given that the HLL is a Redis string
* we need to propagate the change. */
signalModifiedKey(c->db,c->argv[1]);
server.dirty++;
}
addReplyLongLong(c,card);
}
}
如果要计算多个HyperLogLog的基数,则需要将多个HyperLogLog对象合并,这里合并方法是将所有的HyperLogLog对象合并到一个名为max的对象中,max采用的是密集存储结构,如果被合并的对象也是密集存储结构,则循环比较每一个计数值,将大的那个存入max。如果被合并的是稀疏存储,则只需要比较VAL即可。
如果计算单个HyperLogLog对象的基数,则先判断对象头结构体中的基数缓存是否有效,如果有效,可直接返回。如果已经失效,则需要重新计算基数,并修改原有缓存,这也是PFCOUNT命令不被当做只读命令的原因。
推荐工具
给大家推荐一个帮助理解HyperLogLog原理的工具:http://content.research.neustar.biz/blog/hll.html,有兴趣的话可以去学习一下。
GEO
特点:
- geo底层用的其实就是zset,根据经纬度编码后的值作为set元素的score
- 总的来说:将三维转为二维,再转为一维
- Redis 采用了业界广泛使用的 GeoHash 编码方法,这 个方法的基本原理就是“二分区间,区间编码”。
- 通过将经度和纬度分别放在奇数位和偶数位,可以使得 zset 中相邻的 geohash 编码在地理空间上也是相邻的
和zset的相似之处
GEO的key里面需要保存各个member和经纬度,而且经纬度还必须得能够排序,所以这个结构其实和redis的zset结构其实挺像的,唯一的区别可能在于zset只有一个score,而GEO有经度和纬度,所以能用一个score来保存经度和纬度就可以解决问题了。其实redis的确也是这么做的,而且GEO的底层其实就是在zset的结果上做了一层封装,所以按照严格意义上讲GEO并不是redis的一种新的数据类型。
GEO的hash编码方式
为了能高效地对经纬度进行比较,Redis 采用了业界广泛使用的 GeoHash 编码方法,这 个方法的基本原理就是“二分区间,区间编码”。GeoHash是一种地理位置编码方法。 由Gustavo Niemeyer 和 G.M. Morton于2008年发明,它将地理位置编码为一串简短的字母和数字。它是一种分层的空间数据结构,将空间细分为网格形状的桶,这是所谓的z顺序曲线的众多应用之一,通常是空间填充曲线。
当要对一组经纬度进行 GeoHash 编码时,要先对经度和纬度分别编码,然后再把经纬度各自的编码组合成一个最终编码。
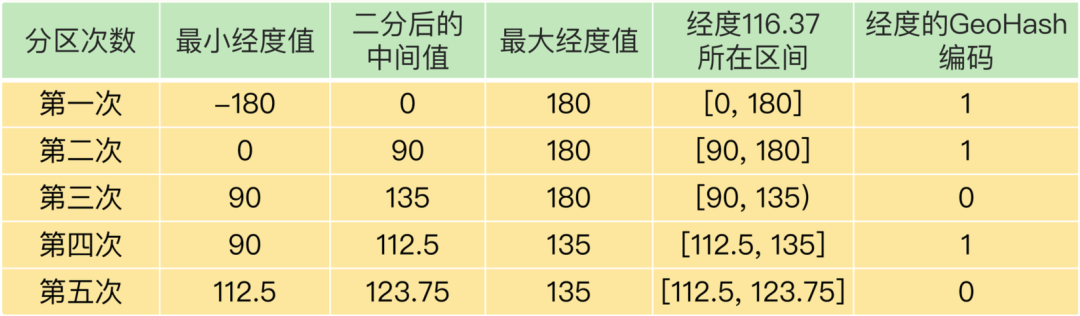
首先,来看下经度和纬度的单独编码过程。以经纬度 116.37,39.86为例,首先看经度 116.37
- 第一次二分区操作,把经度区间[-180,180]分成了左分区[-180,0) 和右分区 [0,180],此时,经度值 116.37 是属于右分区[0,180],所以,用 1 表示第一次二分区 后的编码值。
- 把经度值 116.37 所属的[0,180]区间,分成[0,90) 和[90, 180]。此时,经度值 116.37 还是属于右分区[90,180],所以,第二次分区后的编码值仍然 为 1。等到第三次对[90,180]进行二分区,经度值 116.37 落在了分区后的左分区[90, 135) 中,所以,第三次分区后的编码值就是 0。
- 按照这种方法,做完 5 次分区后,把经度值 116.37 定位在[112.5, 123.75]这个区 间,并且得到了经度值的 5 位编码值,即 11010。这个编码过程如下表所示:
对纬度的编码方式,和对经度的一样,只是纬度的范围是[-90,90],下面这张表显示了对 纬度值 39.86 的编码过程。

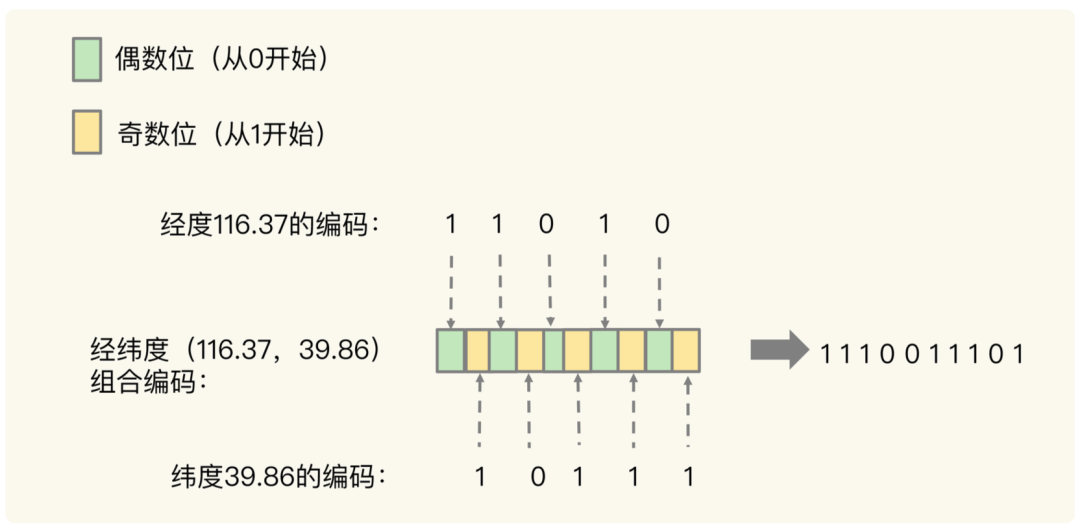
刚刚计算的经纬度(116.37,39.86)的各自编码值是 11010 和 10111,进行交叉组合,偶数位是经度,奇数位是纬度,组合之后, 第 0 位是经度的第 0 位 1,第 1 位是纬度的第 0 位 1,第 2 位是经度的第 1 位 1,第 3 位是纬度的第 1 位 0,以此类推,就能得到最终编码值 1110011101,如下图所示
用了 GeoHash 编码后,原来无法用一个权重分数表示的一组经纬度(116.37,39.86)就 可以用 1110011101 这一个值来表示,就可以保存为 Sorted Set 的权重分数了。最后根据上述得到的二进制值,以5位为一组,进行base32编码
最后获得的结果就是一组经纬度的geohash值。
地理位置二维转一维
上文讲了GeoHash的计算步骤,仅仅说明是什么而没有说明为什么?为什么分别给经度和维度编码?为什么需要将经纬度两串编码交叉组合成一串编码?本节试图回答这一问题。
如下图所示,将二进制编码的结果填写到空间中,当将空间划分为四块时候,编码的顺序分别是左下角00,左上角01,右下脚10,右上角11,也就是类似于Z的曲线,当我们递归的将各个块分解成更小的子块时,编码的顺序是自相似的(分形),每一个子块也形成Z曲线,这种类型的曲线被称为Peano空间填充曲线。
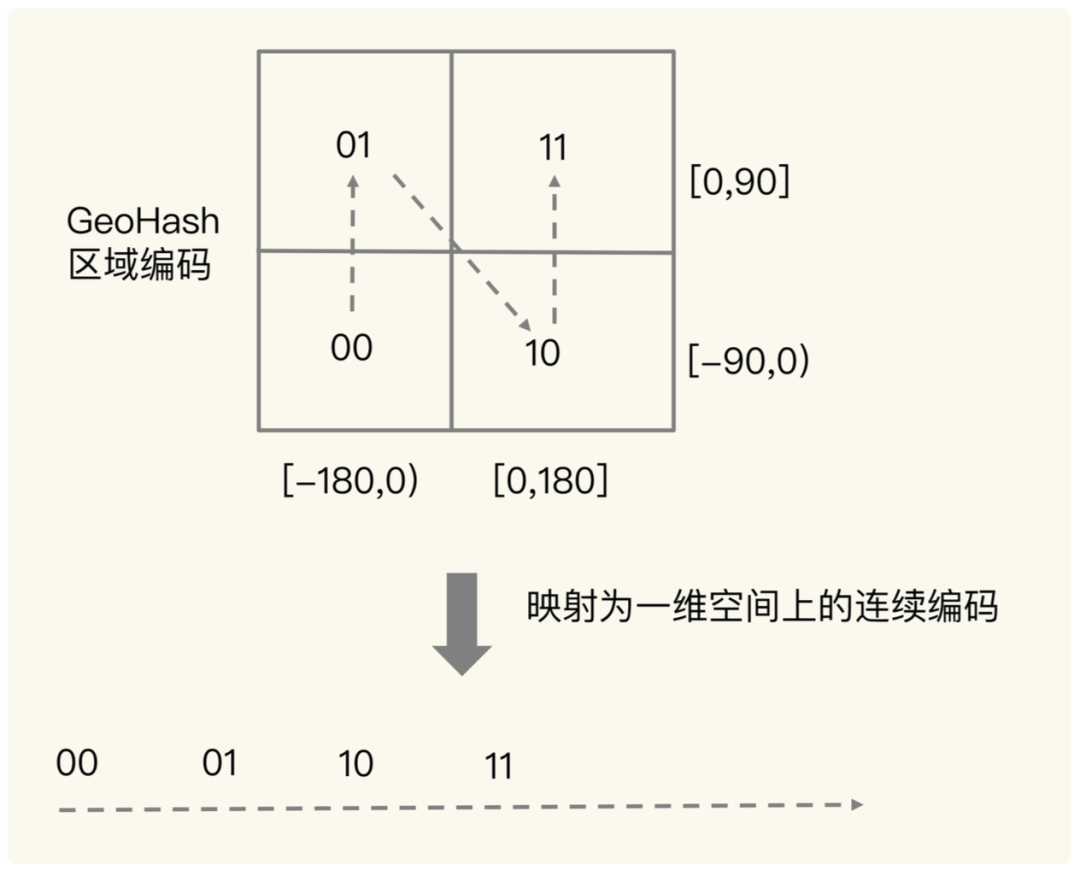
这种类型的空间填充曲线的优点是将二维空间转换成一维曲线(事实上是分形维),对大部分而言,编码相似的距离也相近, 但Peano空间填充曲线最大的缺点就是突变性,有些编码相邻但距离却相差很远,比如0111与1000,编码是相邻的,但距离相差很大。
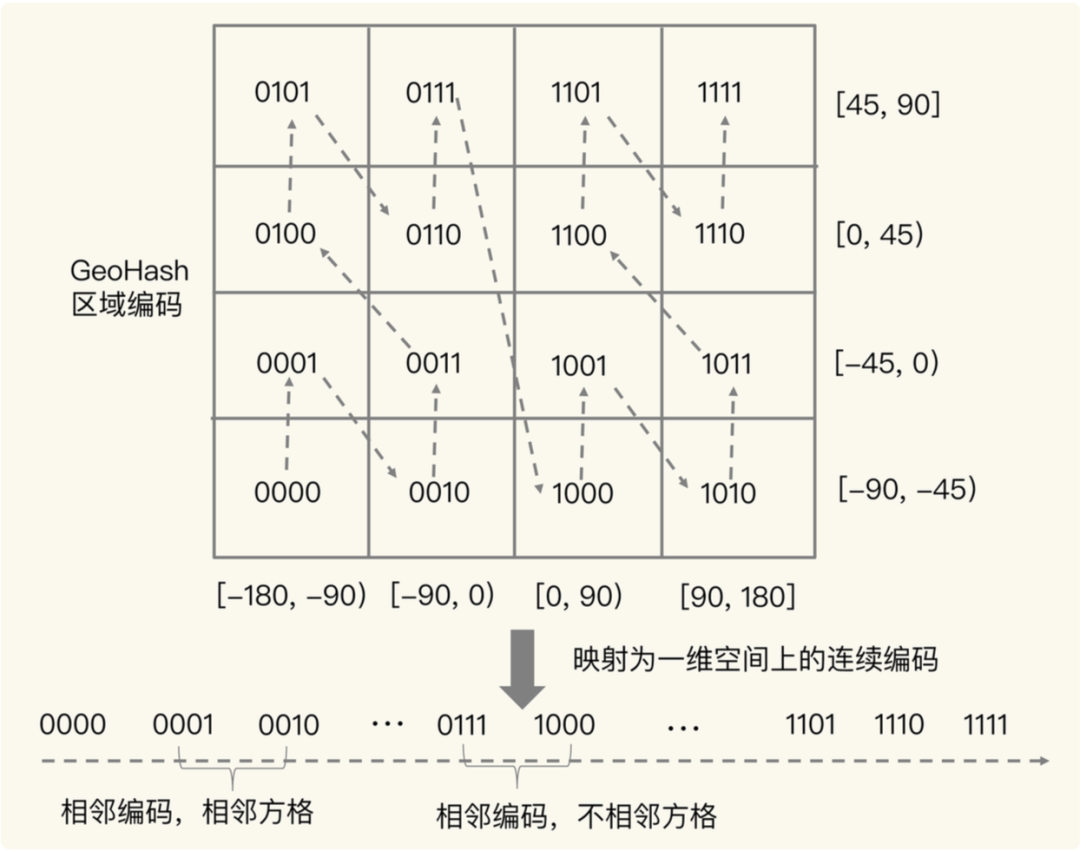
所以,为了避免查询不准确问题,我们可以同时查询给定经纬度所在的方格周围的 4 个或 8 个方格。
源码
本质上redis中的geo就是对geohash的封装,具体geohash相关的代码就不给大家列了(可自行查阅),就给大家介绍下redis geo里的大体流程。
- geoadd命令查看geohash在redis中是怎么存储的
/* GEOADD key [CH] [NX|XX] long lat name [long2 lat2 name2 ... longN latN nameN] */
void geoaddCommand(client *c) {
int xx = 0, nx = 0, longidx = 2;
int i;
/* 解析可选参数 */
while (longidx < c->argc) {
char *opt = c->argv[longidx]->ptr;
if (!strcasecmp(opt,"nx")) nx = 1;
else if (!strcasecmp(opt,"xx")) xx = 1;
else if (!strcasecmp(opt,"ch")) {}
else break;
longidx++;
}
if ((c->argc - longidx) % 3 || (xx && nx)) {
/* 解析所有的经纬度值和member,并对其个数做校验 */
addReplyErrorObject(c,shared.syntaxerr);
return;
}
/* 构建zadd的参数数组 */
int elements = (c->argc - longidx) / 3;
int argc = longidx+elements*2; /* ZADD key [CH] [NX|XX] score ele ... */
robj **argv = zcalloc(argc*sizeof(robj*));
argv[0] = createRawStringObject("zadd",4);
for (i = 1; i < longidx; i++) {
argv[i] = c->argv[i];
incrRefCount(argv[i]);
}
/* 以3个参数为一组,将所有的经纬度和member信息从参数列表里解析出来,并放到zadd的参数数组中 */
for (i = 0; i < elements; i++) {
double xy[2];
if (extractLongLatOrReply(c, (c->argv+longidx)+(i*3),xy) == C_ERR) {
for (i = 0; i < argc; i++)
if (argv[i]) decrRefCount(argv[i]);
zfree(argv);
return;
}
/* 将经纬度坐标转化成score信息 */
GeoHashBits hash;
geohashEncodeWGS84(xy[0], xy[1], GEO_STEP_MAX, &hash);
GeoHashFix52Bits bits = geohashAlign52Bits(hash);
robj *score = createObject(OBJ_STRING, sdsfromlonglong(bits));
robj *val = c->argv[longidx + i * 3 + 2];
argv[longidx+i*2] = score;
argv[longidx+1+i*2] = val;
incrRefCount(val);
}
/* 转化成zadd命令所需要的参数格式*/
replaceClientCommandVector(c,argc,argv);
zaddCommand(c);
}
geo的存储只是zset包了一层,zet底层就是跳表,具体可以看上面跳表内容。
- georadius的大体执行流程(删除大量细节代码)
void georadiusGeneric(client *c, int srcKeyIndex, int flags) {
robj *storekey = NULL;
int storedist = 0; /* 0 for STORE, 1 for STOREDIST. */
/* 根据key找找到对应的zojb */
robj *zobj = NULL;
if ((zobj = lookupKeyReadOrReply(c, c->argv[srcKeyIndex], shared.emptyarray)) == NULL ||
checkType(c, zobj, OBJ_ZSET)) {
return;
}
/* 解析请求中的经纬度值 */
int base_args;
GeoShape shape = {0};
if (flags & RADIUS_COORDS) {
/*
* 各种必选参数的解析,省略细节代码,主要是解析坐标点信息和半径
*/
}
/* 解析所有的可选参数. */
int withdist = 0, withhash = 0, withcoords = 0;
int frommember = 0, fromloc = 0, byradius = 0, bybox = 0;
int sort = SORT_NONE;
int any = 0; /* any=1 means a limited search, stop as soon as enough results were found. */
long long count = 0; /* Max number of results to return. 0 means unlimited. */
if (c->argc > base_args) {
/*
* 各种可选参数的解析,省略细节代码
*/
}
/* Get all neighbor geohash boxes for our radius search
* 获取到要查找范围内所有的9个geo邻域 */
GeoHashRadius georadius = geohashCalculateAreasByShapeWGS84(&shape);
/* 创建geoArray存储结果列表 */
geoArray *ga = geoArrayCreate();
/* 扫描9个区域中是否有满足条的点,有就放到geoArray中 */
membersOfAllNeighbors(zobj, georadius, &shape, ga, any ? count : 0);
/* 如果没有匹配结果,返回空对象 */
if (ga->used == 0 && storekey == NULL) {
addReply(c,shared.emptyarray);
geoArrayFree(ga);
return;
}
long result_length = ga->used;
long returned_items = (count == 0 || result_length < count) ?
result_length : count;
long option_length = 0;
/*
* 后续一些参数逻辑,比如处理排序,存储……
*/
// 释放geoArray占用的空间
geoArrayFree(ga);
}
上述代码删减了大量细节,有兴趣的同学可以自行查阅(redis中的src/geo.c)。不过可以看出georadius的整体流程非常清晰:
- 解析请求参数。
- 计算目标坐标所在的geohash和8个邻居。
- 在zset中查找这9个区域中满足距离限制的所有点集。
- 处理排序等后续逻辑。
- 清理临时存储空间。
面试题专栏
Java面试题专栏已上线,欢迎访问。
- 如果你不知道简历怎么写,简历项目不知道怎么包装;
- 如果简历中有些内容你不知道该不该写上去;
- 如果有些综合性问题你不知道怎么答;
那么可以私信我,我会尽我所能帮助你。
本文来自在线网站:seven的菜鸟成长之路,作者:seven,转载请注明原文链接:www.seven97.top



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)