volatile关键字最全原理剖析
介绍
volatile是轻量级的同步机制,volatile可以用来解决可见性和有序性问题,但不保证原子性。
volatile的作用:
- 保证了不同线程对共享变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
- 禁止进行指令重排序。
底层原理
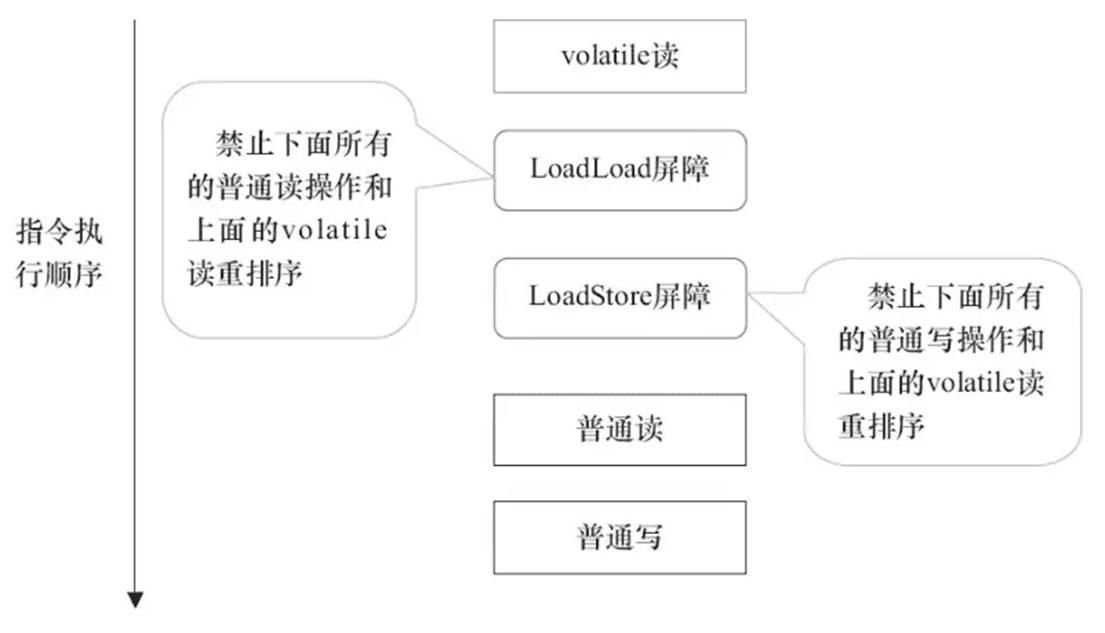
内存屏障
volatile通过内存屏障来维护可见性和有序性,硬件层的内存屏障主要分为两种Load Barrier,Store Barrier,即读屏障和写屏障。对于Java内存屏障来说,它分为四种,即这两种屏障的排列组合。
- 每个volatile写前插入StoreStore屏障;为了禁止之前的普通写和volatile写重排序,还有一个作用是刷出前面线程普通写的本地内存数据到主内存,保证可见性;
- 每个volatile写后插入StoreLoad屏障;防止volatile写与之后可能有的volatile读/写重排序;
- 每个volatile读后插入LoadLoad屏障;禁止之后所有的普通读操作和volatile读操作重排序;
- 每个volatile读后插入LoadStore屏障。禁止之后所有的普通写操作和volatile读重排序;
插入一个内存屏障,相当于告诉CPU和编译器先于这个命令的必须先执行,后于这个命令的必须后执行。对一个volatile字段进行写操作,Java内存模型将在写操作后插入一个写屏障指令,这个指令会把之前的写入值都刷新到内存。
可见性原理
当对volatile变量进行写操作的时候,JVM会向处理器发送一条Lock#前缀的指令

而这个LOCK前缀的指令主要实现了两个步骤:
- 将当前处理器缓存行的数据写回到系统内存;
- 将其他处理器中缓存了该数据的缓存行设置为无效。
原因在于缓存一致性协议,每个处理器通过总线嗅探和MESI协议来检查自己的缓存是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行置为无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存中。
缓存一致性协议:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,就会从内存重新读取。
总结一下:
- 当volatile修饰的变量进行写操作的时候,JVM就会向CPU发送LOCK#前缀指令,通过缓存一致性机制确保写操作的原子性,然后更新对应的主存地址的数据。
- 处理器会使用嗅探技术保证在当前处理器缓存行,主存和其他处理器缓存行的数据的在总线上保持一致。在JVM通过LOCK前缀指令更新了当前处理器的数据之后,其他处理器就会嗅探到数据不一致,从而使当前缓存行失效,当需要用到该数据时直接去内存中读取,保证读取到的数据时修改后的值。
有序性原理
volatile 的 happens-before 关系
happens-before 规则中有一条是 volatile 变量规则:对一个 volatile 域的写,happens-before 于任意后续对这个 volatile 域的读。
//假设线程A执行writer方法,线程B执行reader方法
class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer() {
a = 1; // 1 线程A修改共享变量
flag = true; // 2 线程A写volatile变量
}
public void reader() {
if (flag) { // 3 线程B读同一个volatile变量
int i = a; // 4 线程B读共享变量
……
}
}
}
根据 happens-before 规则,上面过程会建立 3 类 happens-before 关系。
-
根据程序次序规则:1 happens-before 2 且 3 happens-before 4。
-
根据 volatile 规则:2 happens-before 3。
-
根据 happens-before 的传递性规则:1 happens-before 4。

因为以上规则,当线程 A 将 volatile 变量 flag 更改为 true 后,线程 B 能够迅速感知。
volatile 禁止重排序
为了性能优化,JMM 在不改变正确语义的前提下,会允许编译器和处理器对指令序列进行重排序。JMM 提供了内存屏障阻止这种重排序。
Java 编译器会在生成指令系列时在适当的位置会插入内存屏障指令来禁止特定类型的处理器重排序。
JMM 会针对编译器制定 volatile 重排序规则表。

为了实现 volatile 内存语义时,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎是不可能的,为此,JMM 采取了保守的策略。
-
在每个 volatile 写操作的前面插入一个 StoreStore 屏障。
-
在每个 volatile 写操作的后面插入一个 StoreLoad 屏障。
-
在每个 volatile 读操作的后面插入一个 LoadLoad 屏障。
-
在每个 volatile 读操作的后面插入一个 LoadStore 屏障。
volatile 写是在前面和后面分别插入内存屏障,而 volatile 读操作是在后面插入两个内存屏障。

为什么不能保证原子性
在多线程环境中,原子性是指一个操作或一系列操作要么完全执行,要么完全不执行,不会被其他线程的操作打断。
volatile关键字可以确保一个线程对变量的修改对其他线程立即可见,这对于读-改-写的操作序列来说是不够的,因为这些操作序列本身并不是原子的。考虑下面的例子:
public class Counter {
private volatile int count = 0;
public void increment() {
count++; // 这实际上是三个独立的操作:读取count的值,增加1,写回新值到count
}
}
在这个例子中,尽管count变量被声明为volatile,但increment()方法并不是线程安全的。当多个线程同时调用increment()方法时,可能会发生以下情况:
- 线程A读取count的当前值为0。
- 线程B也读取count的当前值为0(在线程A增加count之前)。
- 线程A将count增加到1并写回。
- 线程B也将count增加到1并写回。
在这种情况下,虽然increment()方法被调用了两次,但count的值只增加了1,而不是期望的2。这是因为count++操作不是原子的;它涉及到读取count值、增加1、然后写回新值的多个步骤。在这些步骤之间,其他线程的操作可能会干扰。
为了保证原子性,可以使用synchronized关键字或者java.util.concurrent.atomic包中的原子类(如AtomicInteger),这些机制能够保证此类操作的原子性:
public class Counter {
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.getAndIncrement(); // 这个操作是原子的
}
}
在这个修改后的例子中,使用AtomicInteger及其getAndIncrement()方法来保证递增操作的原子性。这意味着即使多个线程同时尝试递增计数器,每次调用也都会正确地将count的值递增1。
关于作者
来自一线程序员Seven的探索与实践,持续学习迭代中~
本文已收录于我的个人博客:https://www.seven97.top
公众号:seven97,欢迎关注~
本文来自在线网站:seven的菜鸟成长之路,作者:seven,转载请注明原文链接:www.seven97.top



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?