解决哈希冲突的三种方法
为什么会哈希冲突
我们知道,在使用Map,Set这些集合时,都会重写hashcode方法,但Java中的hashCode方法会将对象映射到一个32位的整数范围(即从-2^31 到 2^31-1)。无论输入数据多么庞大,哈希函数生成的哈希值总是落在这个有限范围内。因此是会存在hash冲突的。
无论哈希函数设计得多么好,也无法避免所有冲突。一个好的哈希函数应尽可能地将输入数据均匀地分布到输出范围内,但总会有一些不同的输入数据生成相同的输出哈希值。这是因为哈希函数本质上是一个压缩映射过程,将大量输入映射到较小的输出范围。
尽管哈希冲突不可避免,但有多种方法可以处理哈希冲突,解决哈希冲突的三种方法:
拉链法、开放地址法、再散列法
拉链法
HashMap,HashSet其实都是采用的拉链法来解决哈希冲突的,就是在每个位桶实现的时候,采用链表(jdk1.8之后采用链表+红黑树)的数据结构来去存取发生哈希冲突的输入域的关键字(也就是被哈希函数映射到同一个位桶上的关键字)
拉链法的装载因子为n/m(n为输入域的关键字个数,m为位桶的数目)
开放地址法
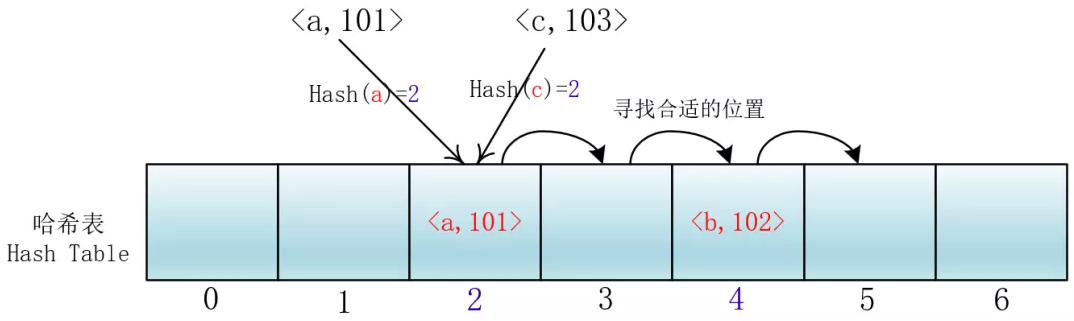
所谓开放地址法就是发生冲突时在散列表(也就是数组里)里去寻找合适的位置存取对应的元素,就是所有输入的元素全部存放在哈希表里。也就是说,位桶的实现是不需要任何的链表来实现的,换句话说,也就是这个哈希表的装载因子不会超过1。
它的实现是在插入一个元素的时候,先通过哈希函数进行判断,若是发生哈希冲突,就以当前地址为基准,根据再寻址的方法(探查序列),去寻找下一个地址,若发生冲突再去寻找,直至找到一个为空的地址为止。
探查序列的方法:
-
线性探查
-
平方探测
-
伪随机探测
线性探查
di =1,2,3,…,m-1;这种方法的特点是:冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
(使用例子:ThreadLocal里面的ThreadLocalMap中的set方法)
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
//线性探测的关键代码
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
但是这样会有一个问题,就是随着键值对的增多,会在哈希表里形成连续的键值对。当插入元素时,任意一个落入这个区间的元素都要一直探测到区间末尾,并且最终将自己加入到这个区间内。这样就会导致落在区间内的关键字Key要进行多次探测才能找到合适的位置,并且还会继续增大这个连续区间,使探测时间变得更长,这样的现象被称为“一次聚集(primary clustering)”。
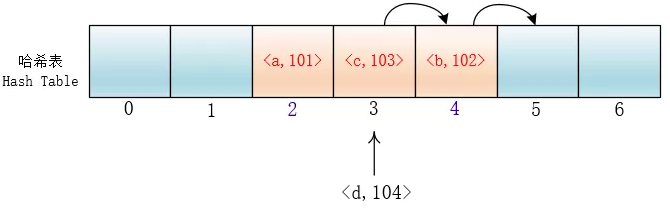

平方探测
在探测时不一个挨着一个地向后探测,可以跳跃着探测,这样就避免了一次聚集。
di=12,-12,22,-22,…,k2,-k2;这种方法的特点是:冲突发生时,在表的左右进行跳跃式探测,比较灵活。虽然平方探测法解决了线性探测法的一次聚集,但是它也有一个小问题,就是关键字key散列到同一位置后探测时的路径是一样的。这样对于许多落在同一位置的关键字而言,越是后面插入的元素,探测的时间就越长。
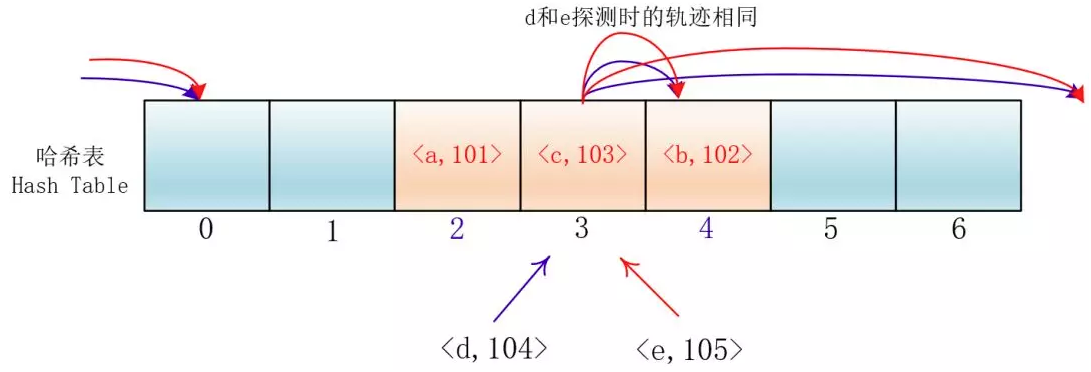
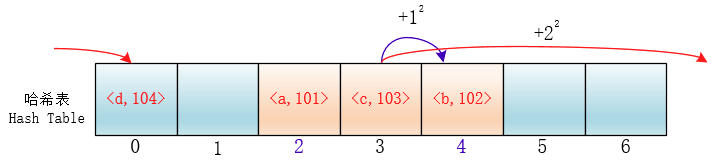
这种现象被称作“二次聚集(secondary clustering)”,其实这个在线性探测法里也有。
伪随机探测
di=伪随机数序列;具体实现时,应建立一个伪随机数发生器,(如i=(i+p) % m),生成一个位随机序列,并给定一个随机数做起点,每次去加上这个伪随机数++就可以了。
再散列法
再散列法其实很简单,就是再使用哈希函数去散列一个输入的时候,输出是同一个位置就再次散列,直至不发生冲突位置
缺点:每次冲突都要重新散列,计算时间增加。一般不用这种方式
关于作者
来自一线程序员Seven的探索与实践,持续学习迭代中~
本文已收录于我的个人博客:https://www.seven97.top
公众号:seven97,欢迎关注~
本文来自在线网站:seven的菜鸟成长之路,作者:seven,转载请注明原文链接:www.seven97.top



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)