Scrapy入门到放弃06:Spider中间件
 如果有时间 你会来看一看我吧
看大雪如何衰老的 我的眼睛如何融化
如果有时间 你会来看一看我吧
看大雪如何衰老的 我的眼睛如何融化
前言
写一写Spider中间件吧,都凌晨了,一点都不想写,主要是也没啥用...哦不,是平时用得少。因为工作上的事情,已经拖更好久了,这次就趁着半夜写一篇。
Scrapy-deltafetch插件是在Spider中间件实现的去重逻辑,开发过程中个人用的还是比较少一些的。
作用
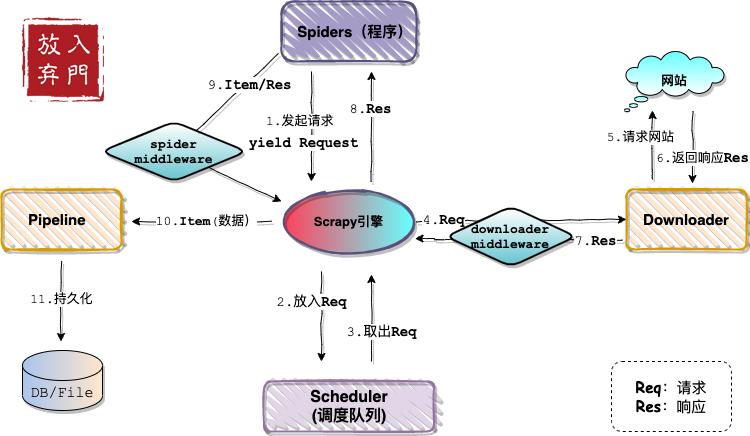
依旧是那张熟悉的架构图,不出意外,这张图是最后一次出现在Scrapy系列文章中了。
如架构图所示,Spider中间件位于Spiders(程序)和engine之间,在Item即将拥抱Pipeline之前,对Item和Response进行处理。官方定义如下:
Spider中间件是介入Scrapy的spider处理机制的钩子框架,可以添加代码来处理发送给 Spiders 的response及spider产生的item和request。
Spider中间件
当我们启动爬虫程序的时候,Scrapy自动帮我们激活启用一些内置的Spider中间件。
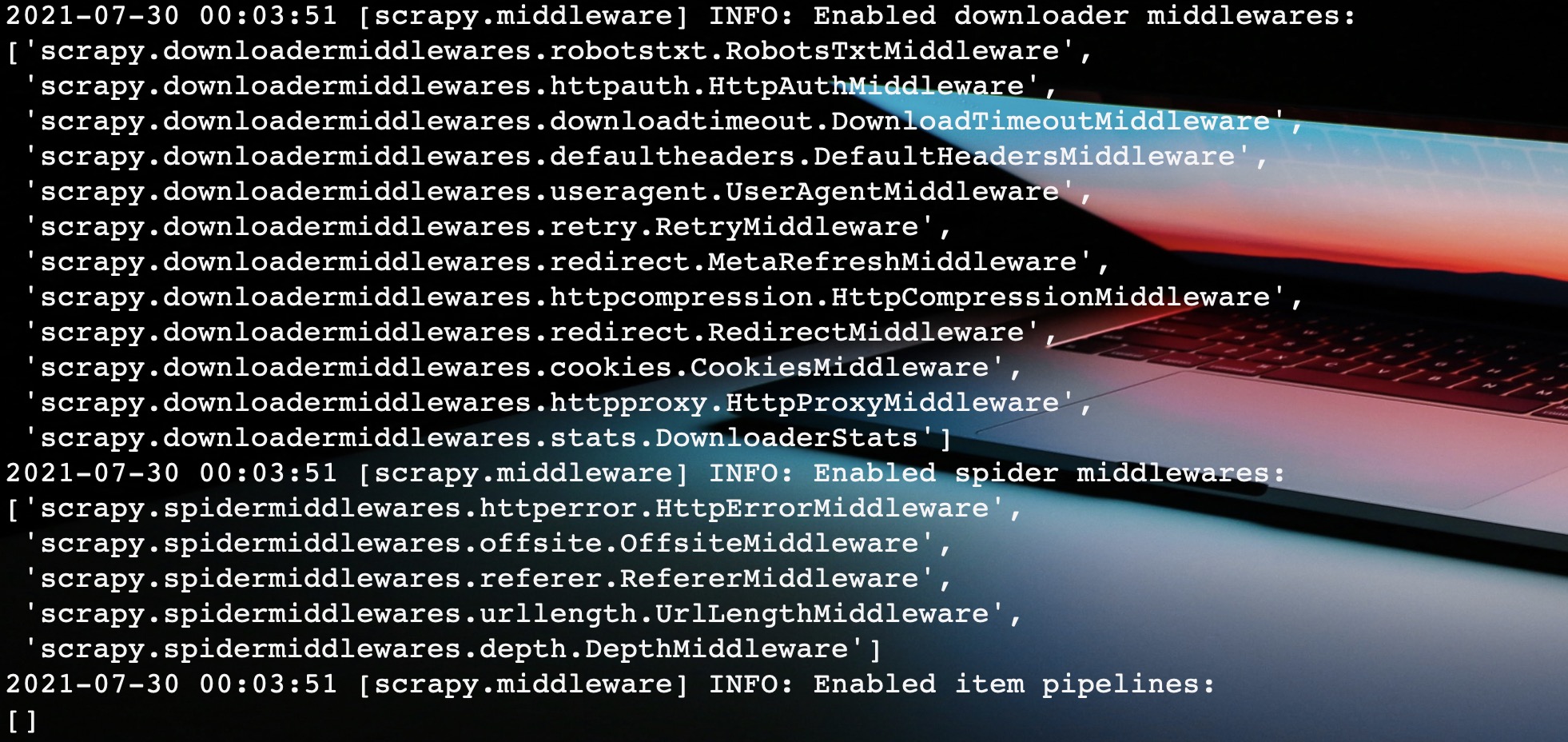
如图所示,这里帮我们启用了五个Spider中间件,这里我们依次分析一波。
内置Spider中间件
之前在下载器中间件也说了:大部分内置中间件是和settings中的配置配套使用的。Spider中间件也不例外。这里就想将
1. HttpErrorMiddleware
作用:默认过滤出所有失败,即响应值不在200-300之间)的response。
使用:方式很多,只讲两个,选一即可。
- 程序内属性定义
class MySpider(CrawlSpider):
handle_httpstatus_list = [404]
这个和custom_settings有异曲同工之妙,都是只在当前爬虫生效,但是这里作为属性出现的。
- settings.py全局定义
HTTPERROR_ALLOWED_CODES = [400, 404]
如果使用custom_settings定义此配置时,和方法1一样,都是在当前程序生效。话到此处,不妨看看HttpError中间件的源码是如何处理响应码的。
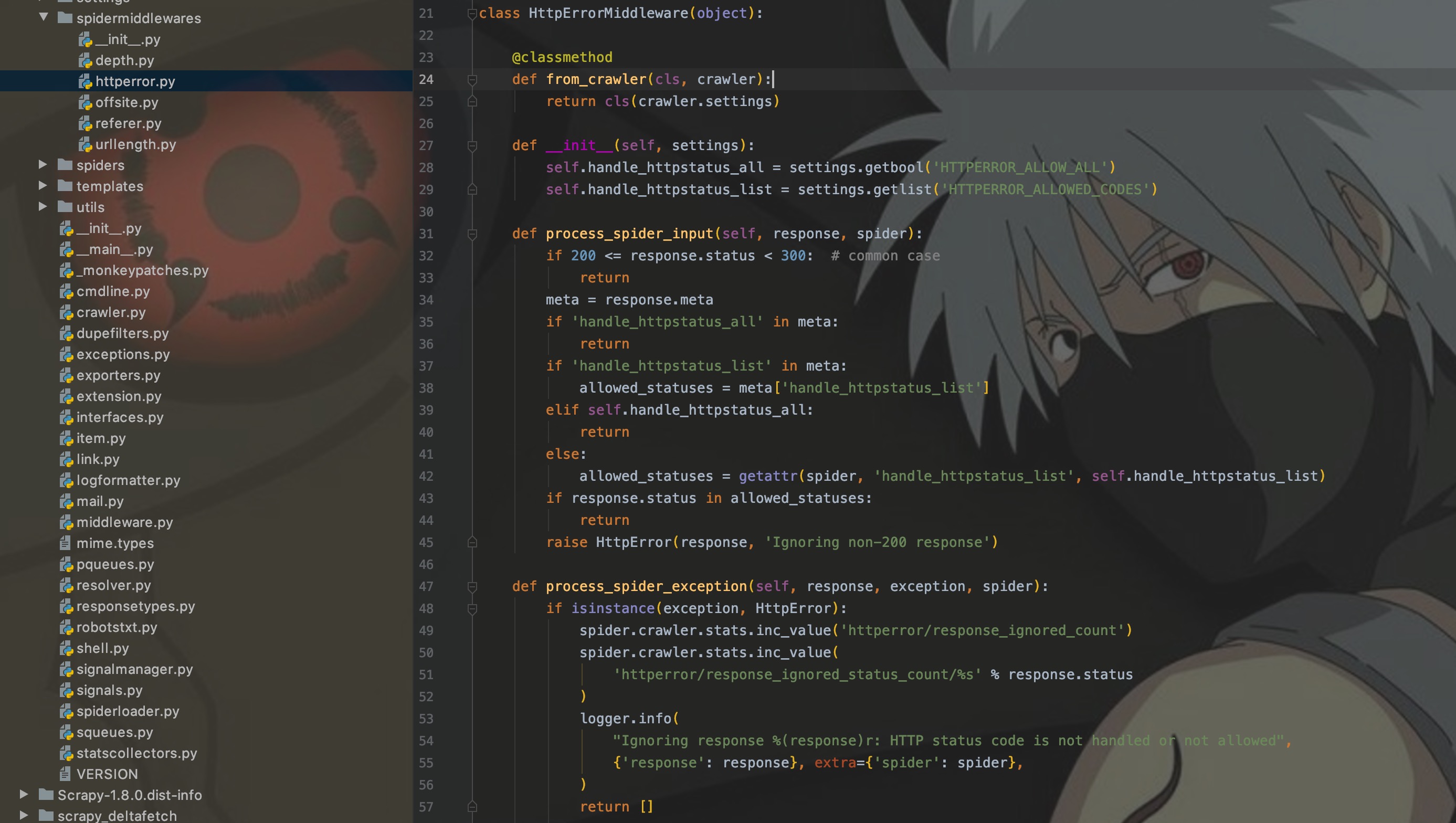
上图为HttpError中间件的源码,可以看出通过response的status来获取响应码,然后进行过滤判断,如果响应码在[200, 300)区间,则直接通过;否则就要查看配置,再次进行判断。
2. OffsiteMiddleware
该中间件过滤出所有主机名不在spider属性 allowed_domains 的request,request设置了 dont_filter,则就算不在也不过滤pider的 handle_httpstatus_list 属性或 HTTPERROR_ALLOWED_CODES 设置来指定spider能处理的response返回值
3. RefererMiddleware
根据生成Request的Response的URL来设置Request的Referer字段
4. UrlLengthMiddleware
过滤URLLENGTH_LIMIT - 允许爬取URL最长的长度
5. DepthMiddleware
用来限制爬取深度的最大深度或类似,
DEPTH_LIMIT - 爬取所允许的最大深度,如果为0,则没有限制。
DEPTH_STATS - 是否收集爬取状态。
DEPTH_PRIORITY - 是否根据其深度对requet安排优先级
自定义Spider中间件
Spider中间件也是在middlewares.py中进行定义,通过SPIDER_MIDDLEWARES进行激活启用配置。
这里我们先看看Scrapy给定的自定义模板是怎么样的。
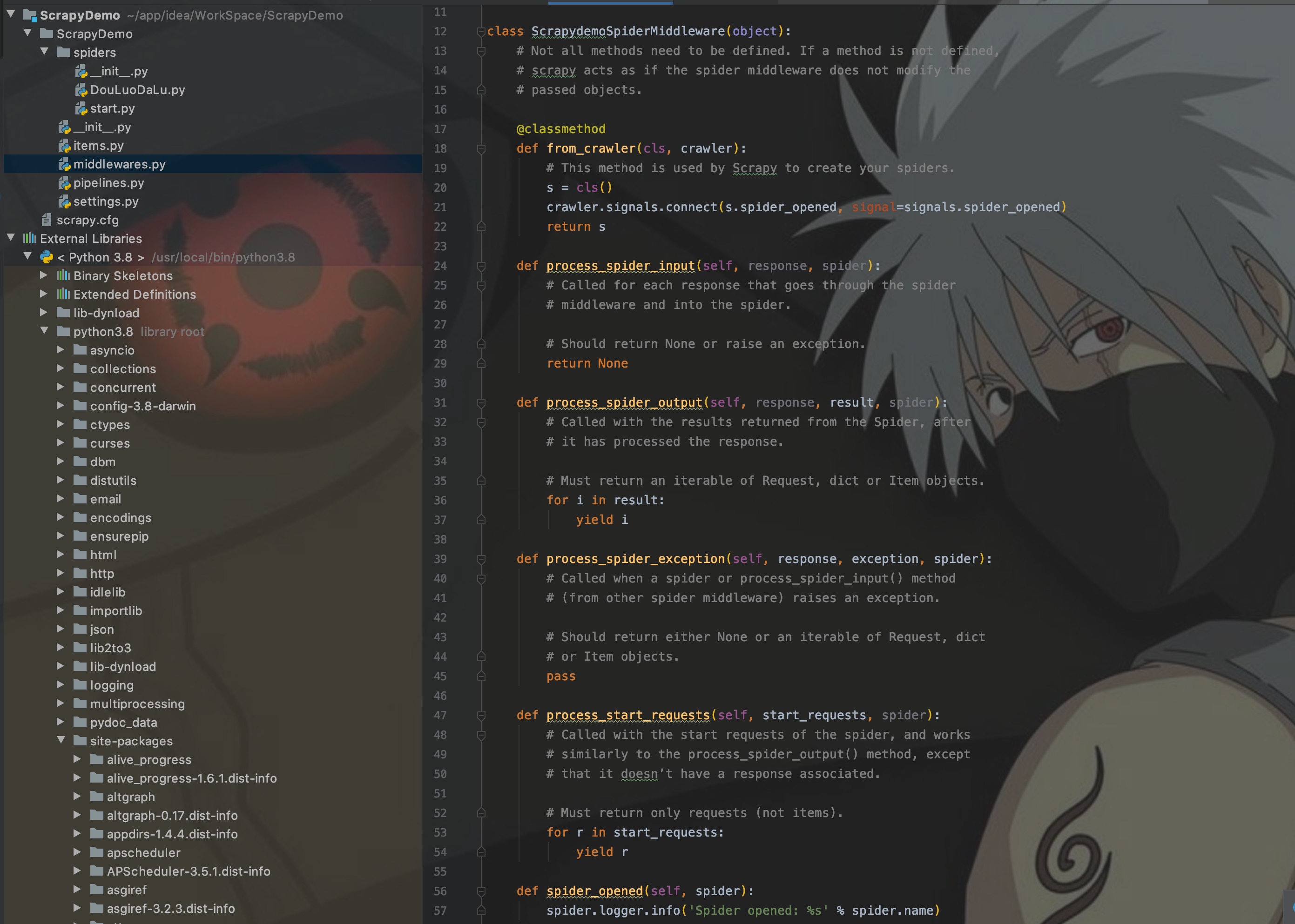
如图,主要需要实现以下几个方法:
- from_crawler:类方法,用于初始化中间件
- process_spider_input:当response通过spider中间件时,该方法被调用,处理该response
- process_spider_output:当Spider处理response返回result时,该方法被调用
- process_spider_exception:异常时, 该方法被调用
- process_start_requests:该方法以spider 启动的request为参数被调用,执行的过程类似于 process_spider_outpu ,只不过其没有相关联的response并且必须返回request(不是item)。
这里具体如何实现就不写了,参考上面HttpErrorMiddleware的代码实现即可。
区别
Spider中间件和下载器中间件有什么区别?
- Spider中间件可以获取到Item,即爬取数据的封装结构。
- Spider中间件是单向的,处理请求和响应。下载器中间件是双向的,第一次处理请求,第二次处理请求和响应。
- Spider中间件主要对请求后的响应结果进行处理;下载器中间件主要是对在请求前构造请求,例如添加请求头、代理IP等。
结语
这篇文章主要是作一个知识扩展,对于Spider中间件来说,了解并会使用内置中间件即可,至于自定义真的很少会用到。
写这种基础理论篇是最磨人性子的了,其实可能自己一看就懂,但是就是很难很好的讲出来。所幸的是,后面应该就快要到实操的环节了。期待下一次相遇。
95后小程序员,写的都是日常工作中的亲身实践,置身于初学者的角度从0写到1,详细且认真。文章会在公众号 [入门到放弃之路] 首发,期待你的关注。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号