Scrapy入门到放弃05:让Item在Pipeline中飞一会儿
 春风会吹绿冰封的海角天涯
琴弦流淌着岁月喑哑
春风会吹绿冰封的海角天涯
琴弦流淌着岁月喑哑
前言
"又回到最初的起点,呆呆地站在镜子前"。
本来这篇是打算写Spider中间件的,但是因为这一块涉及到Item,所以这篇文章先将Item讲完,顺便再讲讲Pipeline,然后再讲Spider中间件。
Item和Pipeline
依旧是先上架构图。
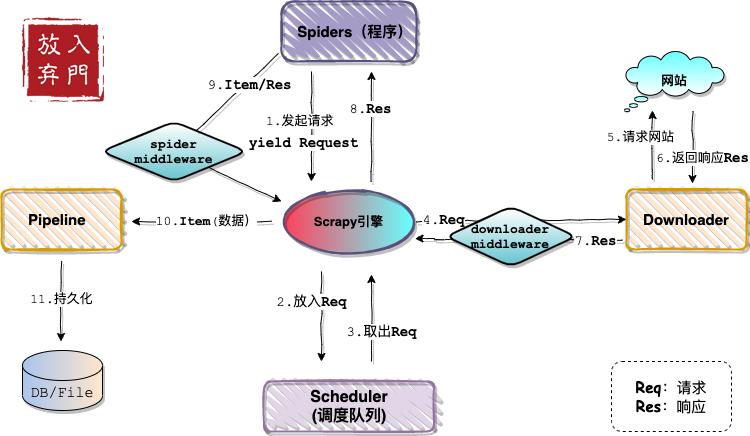
从架构图中可以看出,当下载器从网站获取了网页响应内容,通过引擎又返回到了Spider程序中。我们在程序中将响应内容通过css或者xpath规则进行解析,然后构造成Item对象。
而Item和响应内容在传递到引擎的过程中,会被Spider中间件进行处理。最后Pipeline会将引擎传递过来的Item持久化存储。
总结:Item是数据对象,Pipeline是数据管道。

Item
Item说白了就是一个类,里面包含数据字段。目的是为了让你把从网页解析出来的目标数据进行结构化。需要注意的是,我们通常要先确定Item的结构,然后再在程序中构造、在pipeline中处理。
这里依旧还是以斗罗大陆为例。
Item类定义
Item在items.py中定义。我们先看看此py文件中的Item定义模板。
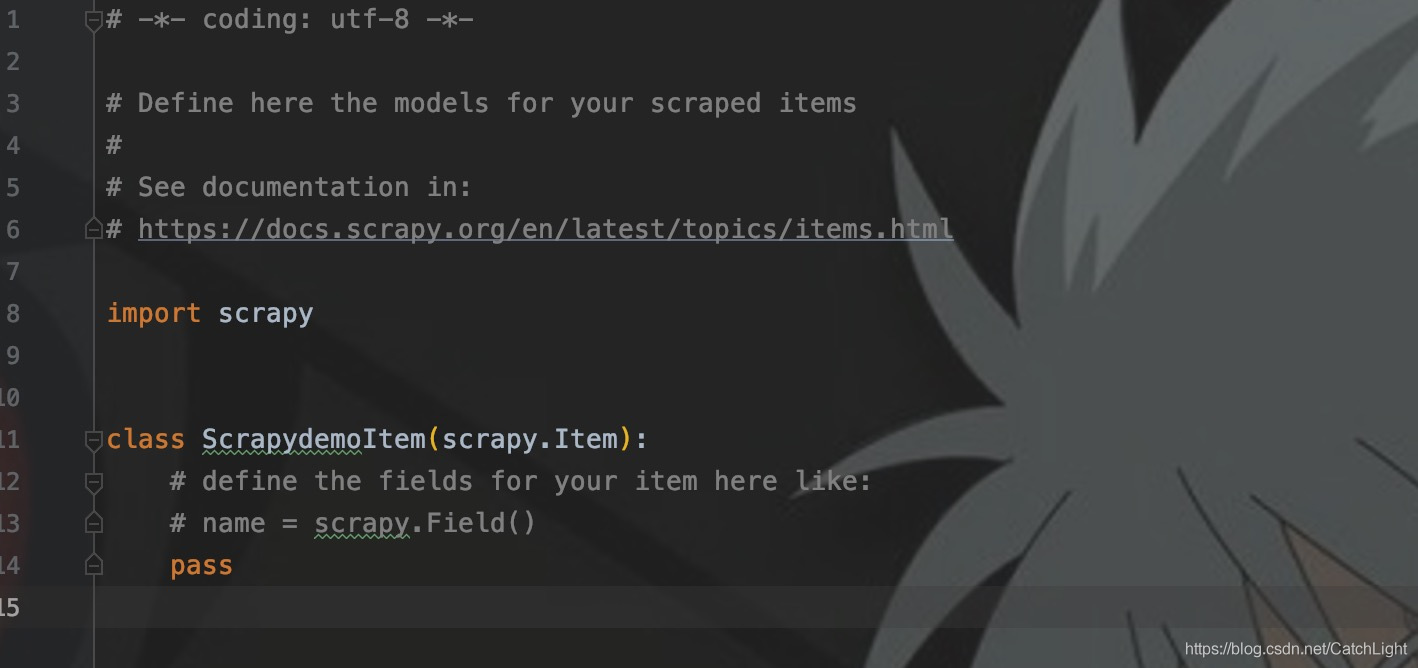
如图所示,即是模板,要点有二。
- Item类继承scrapy.Item
- 字段 = scrapy.Field()
这里根据我们在斗罗大陆页面需要采集的数据字段,进行Item定义。
class DouLuoDaLuItem(scrapy.Item):
name = scrapy.Field()
alias = scrapy.Field()
area = scrapy.Field()
parts = scrapy.Field()
year = scrapy.Field()
update = scrapy.Field()
describe = scrapy.Field()
Item数据构造
当我们将Item类定义之后,就要在spider程序中进行构造,即填充数据。
# 导入Item类,ScrapyDemo是包名
from ScrapyDemo.items import DouLuoDaLuItem
# 构造Item对象
item = DouLuoDaLuItem
item['name'] = name
item['alias'] = alias
item['area'] = area
item['parts'] = parts
item['year'] = year
item['update'] = update
item['describe'] = describe
代码如上,一个Item数据对象就被构造完成。
发射Item到Pipeline
在Item对象构造完成之后,还需要一行代码就能将Item传递到Pipeline中。
yield item
至此,Pipeline,我来了。
Pipeline
Pipeline直译就是管道,负责处理Item数据,从而实现持久化。说白了就是将数据放到各种形式的文件、数据库中。
功能
官方给出的Pipeline功能有:
- 清理HTML数据
- 验证数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库
在实际开发中,4的场景比较多。
定义Pipeline
Pipeline定义在pipeline.py中,这里依旧先看看Pipeline给定的模板。
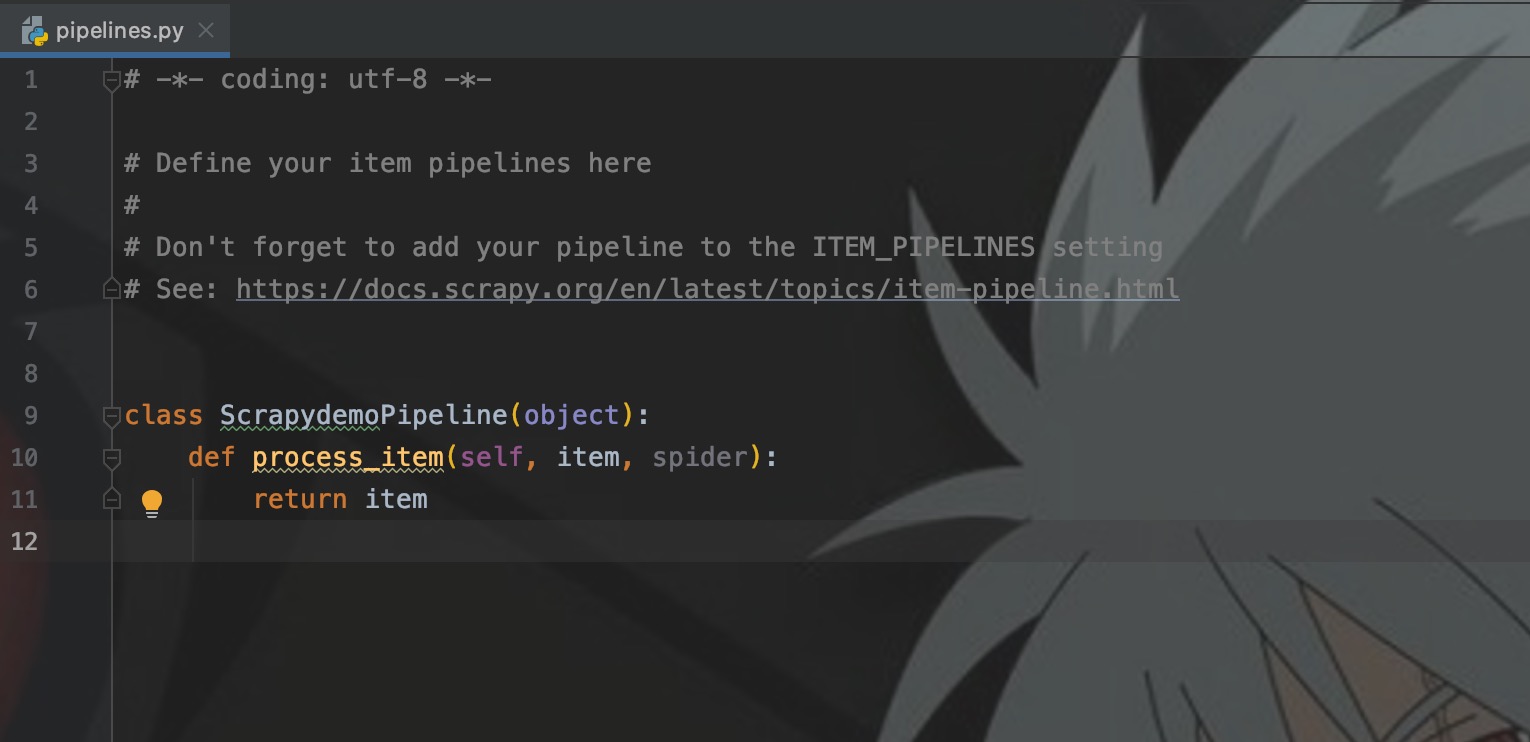
如图,只实现了process_item()方法,来处理传递过来的Item。但是在实际开发中,我们通常要实现三个方法:
- __init__:用来构造对象属性,例如数据库连接等
- from_crawler:类方法,用来初始化变量
- process_item:核心逻辑代码,处理Item
这里,我们就自定义一个Pipeline,将Item数据放入数据库。
配置Pipeline
和middleware一样在settings.py中进行配置,这里对应的是ITEM_PIPELINE参数。
ITEM_PIPELINES = {
'ScrapyDemo.pipelines.CustomDoLuoDaLuPipeline': 300
}
Key依旧对应的是类全路径,Value为优先级,数字越小,优先级越高。Item会根据优先级依此通过每个Pipeline,这样可以在每个Pipeline中对Item进行处理。
为了直观,后续我将Pipeline在代码中进行局部配置。
pipeline连接数据库
1. 配置数据库属性
我们首先在setttings.py中将数据库的IP、账号、密码、数据库名称配置,这样在pipeline中就可直接读取,并创建连接。
MYSQL_HOST = '175.27.xx.xx'
MYSQL_DBNAME = 'scrapy'
MYSQL_USER = 'root'
MYSQL_PASSWORD = 'root'
2. 定义pipeline
主要使用pymysql驱动连接数据库、twisted的adbapi来异步操作数据库,这里异步划重点,基本上异步就是效率、快的代名词。
import pymysql
from twisted.enterprise import adbapi
from ScrapyDemo.items import DouLuoDaLuItem
class CustomDoLuoDaLuPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_crawler(cls, crawler):
# 读取settings中的配置
params = dict(
host=crawler.settings['MYSQL_HOST'],
db=crawler.settings['MYSQL_DBNAME'],
user=crawler.settings['MYSQL_USER'],
passwd=crawler.settings['MYSQL_PASSWORD'],
charset='utf8',
cursorclass=pymysql.cursors.DictCursor,
use_unicode=False
)
# 创建连接池,pymysql为使用的连接模块
dbpool = adbapi.ConnectionPool('pymysql', **params)
return cls(dbpool)
def process_item(self, item, spider):
if isinstance(item, DouLuoDaLuItem):
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider)
return item
# 执行数据库操作的回调函数
def do_insert(self, cursor, item):
sql = 'insert into DLDLItem(name, alias, area, parts, year, `update`, `describe`) values (%s, %s, %s, %s, %s, %s, %s)'
params = (item['name'], item['alias'], item['area'], item['parts'], item['year'], item['update'], item['describe'])
cursor.execute(sql, params)
# 当数据库操作失败的回调函数
def handle_error(self, failue, item, spider):
print(failue)
这里要重点强调一下上面代码中的几个点。
- process_item()中为什么使用isinstance来判断item的类型?
这个是为了解决多种Item经过同一个Pipiline时,需要调用不同的方法来进行数据库操作的场景。如下图所示:
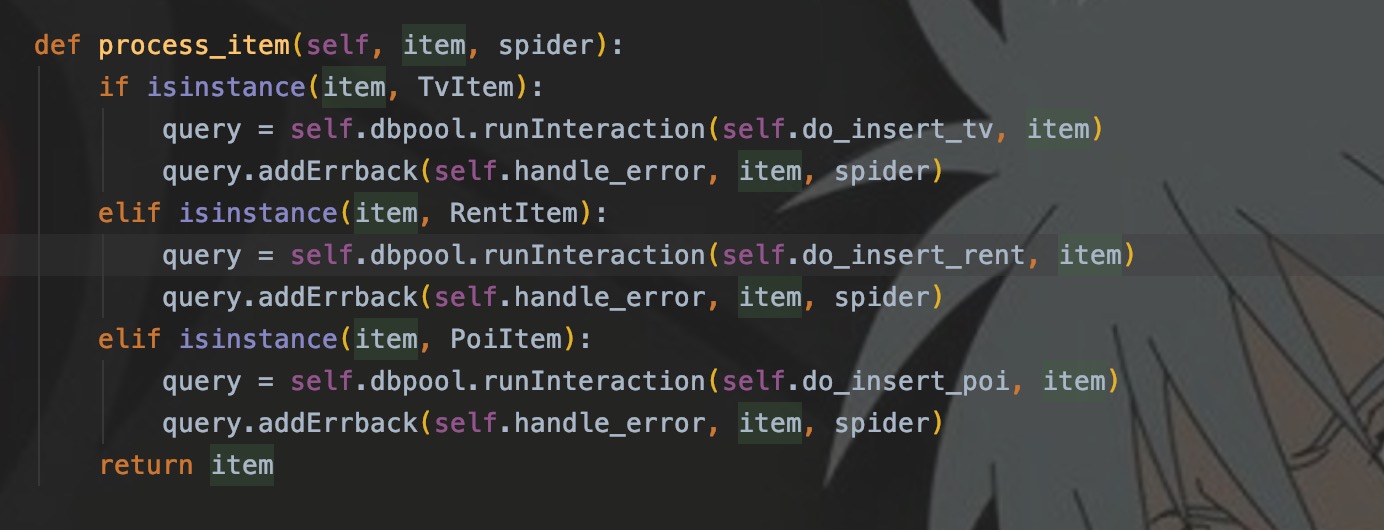
不同的Item具有不同的结构,意味着需要不同的sql来插入到数据库中,所以会先判断Item类型,再调用对应方法处理。
- sql中update、describe字段为什么要加反引号?
update、describe和select一样,都是MySQL的关键字,所以如果想要在字段中使用这些单词,在执行sql和建表语句汇总都要加上反引号,否则就会报错。
3. 生成Item放入pipeline
即将迎面而来的依旧是熟悉的代码,Item结构在上面的items.py中已经定义。pipeline也将在代码内局部配置,这个不清楚的可以看第二篇文章。
import scrapy
from ScrapyDemo.items import DouLuoDaLuItem
class DouLuoDaLuSpider(scrapy.Spider):
name = 'DouLuoDaLu'
allowed_domains = ['v.qq.com']
start_urls = ['https://v.qq.com/detail/m/m441e3rjq9kwpsc.html']
custom_settings = {
'ITEM_PIPELINES': {
'ScrapyDemo.pipelines.CustomDoLuoDaLuPipeline': 300
}
}
def parse(self, response):
name = response.css('h1.video_title_cn a::text').extract()[0]
common = response.css('span.type_txt::text').extract()
alias, area, parts, year, update = common[0], common[1], common[2], common[3], common[4]
describe = response.css('span._desc_txt_lineHight::text').extract()[0]
item = DouLuoDaLuItem()
item['name'] = name
item['alias'] = alias
item['area'] = area
item['parts'] = parts
item['year'] = year
item['update'] = update
item['describe'] = describe
print(item)
yield item
4.程序测试
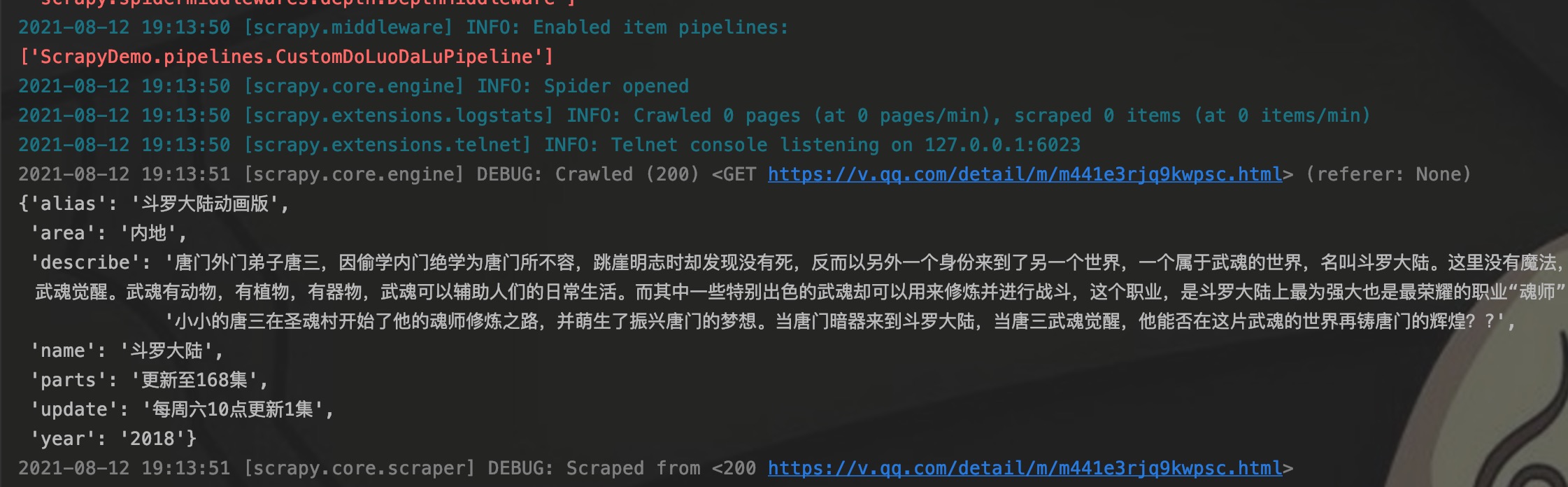
启动程序,可以看到控制台打印了已经启用的pipeline列表,同时也可以看到item的内容。程序执行结束后,我们去数据库查看数据是否已经放到数据库。

如图,在数据库的DLDLItem表中已经可以查到数据。
结语
Item和Pipeline让数据结构存储流程化,我们可以定义并配置多个Pipeline,当yield item之后,数据就会根据存储在文件里、数据库里
与之相关的还有一个ItemLoaders,我基本上没有用过,但是后面还是当做扩展来写一下。期待下一次相遇。
95后小程序员,写的都是日常工作中的亲身实践,置身于初学者的角度从0写到1,详细且认真。文章会在公众号 [入门到放弃之路] 首发,期待你的关注。


