
Python大数据处理模块Pandas
Pandas使用一个二维的数据结构DataFrame来表示表格式的数据,相比较于Numpy,Pandas可以存储混合的数据结构,同时使用NaN来表示缺失的数据,而不用像Numpy一样要手工处理缺失的数据,并且Pandas使用轴标签来表示行和列
1、文件读取
首先将用到的pandas和numpy加载进来
import pandas as pd
import numpy as np
读取数据:
#csv和xlsx分别用read_csv和read_xlsx,下面以csv为例
df=pd.read_csv('f:\1024.csv')
2、查看数据
df.head()
#默认出5行,括号里可以填其他数据
3、查看数据类型
df.dtypes
4、利用现有数据生成一列新数据
比如:max_time和min_time是现有的两列,现在业务需要生成一列gs,gs=max_time-min_time
df.['gs']=df.['max_time']-['min_time']
#查看是否成功
df.head()
5、查看基本统计量
df.describe(include='all') # all代表需要将所有列都列出
通常来说,数据是CSV格式,就算不是,至少也可以转换成CSV格式。在Python中,我们的操作如下:
import pandas as pd
# Reading data locally
df = pd.read_csv('/Users/al-ahmadgaidasaad/Documents/d.csv')
# Reading data from web
df = pd.read_csv(data_url)
为了读取本地CSV文件,我们需要pandas这个数据分析库中的相应模块。
其中的read_csv函数能够读取本地和web数据。
# Head of the data
print df.head()
# OUTPUT
Abra Apayao Benguet Ifugao Kalinga
0 1243 2934 148 3300 10553
1 4158 9235 4287 8063 35257
2 1787 1922 1955 1074 4544
3 17152 14501 3536 19607 31687
4 1266 2385 2530 3315 8520
# Tail of the data
print df.tail()
# OUTPUT
Abra Apayao Benguet Ifugao Kalinga
74 2505 20878 3519 19737 16513
75 60303 40065 7062 19422 61808
76 6311 6756 3561 15910 23349
77 13345 38902 2583 11096 68663
78 2623 18264 3745 16787 16900
上述操作等价于通过print(head(df))来打印数据的前6行,以及通过print(tail(df))来打印数据的后6行。
当然Python中,默认打印是5行,而R则是6行。因此R的代码head(df, n = 10),
在Python中就是df.head(n = 10),打印数据尾部也是同样道理。
在Python中,我们则使用columns和index属性来提取,如下:
# Extracting column names
print df.columns
# OUTPUT
Index([u'Abra', u'Apayao', u'Benguet', u'Ifugao', u'Kalinga'], dtype='object')
# Extracting row names or the index
print df.index
# OUTPUT
Int64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30], dtype='int64')
数据转置使用T方法,
# Transpose data
print df.T
# OUTPUT
0 1 2 3 4 5 6 7 8 9
Abra 1243 4158 1787 17152 1266 5576 927 21540 1039 5424
Apayao 2934 9235 1922 14501 2385 7452 1099 17038 1382 10588
Benguet 148 4287 1955 3536 2530 771 2796 2463 2592 1064
Ifugao 3300 8063 1074 19607 3315 13134 5134 14226 6842 13828
Kalinga 10553 35257 4544 31687 8520 28252 3106 36238 4973 40140
... 69 70 71 72 73 74 75 76 77
Abra ... 12763 2470 59094 6209 13316 2505 60303 6311 13345
Apayao ... 37625 19532 35126 6335 38613 20878 40065 6756 38902
Benguet ... 2354 4045 5987 3530 2585 3519 7062 3561 2583
Ifugao ... 9838 17125 18940 15560 7746 19737 19422 15910 11096
Kalinga ... 65782 15279 52437 24385 66148 16513 61808 23349 68663
78
Abra 2623
Apayao 18264
Benguet 3745
Ifugao 16787
Kalinga 16900
其他变换,例如排序就是用sort属性。现在我们提取特定的某列数据。
Python中,可以使用iloc或者ix属性。但是我更喜欢用ix,因为它更稳定一些。假设我们需数据第一列的前5行,我们有:
print df.ix[:, 0].head()
# OUTPUT
0 1243
1 4158
2 1787
3 17152
4 1266
Name: Abra, dtype: int64
顺便提一下,Python的索引是从0开始而非1。为了取出从11到20行的前3列数据,我们有:
print df.ix[10:20, 0:3]
# OUTPUT
Abra Apayao Benguet
10 981 1311 2560
11 27366 15093 3039
12 1100 1701 2382
13 7212 11001 1088
14 1048 1427 2847
15 25679 15661 2942
16 1055 2191 2119
17 5437 6461 734
18 1029 1183 2302
19 23710 12222 2598
20 1091 2343 2654
上述命令相当于df.ix[10:20, ['Abra', 'Apayao', 'Benguet']]。
为了舍弃数据中的列,这里是列1(Apayao)和列2(Benguet),我们使用drop属性,如下:
print df.drop(df.columns[[1, 2]], axis = 1).head()
# OUTPUT
Abra Ifugao Kalinga
0 1243 3300 10553
1 4158 8063 35257
2 1787 1074 4544
3 17152 19607 31687
4 1266 3315 8520
axis 参数告诉函数到底舍弃列还是行。如果axis等于0,那么就舍弃行。
下一步就是通过describe属性,对数据的统计特性进行描述:
print df.describe()
# OUTPUT
Abra Apayao Benguet Ifugao Kalinga
count 79.000000 79.000000 79.000000 79.000000 79.000000
mean 12874.379747 16860.645570 3237.392405 12414.620253 30446.417722
std 16746.466945 15448.153794 1588.536429 5034.282019 22245.707692
min 927.000000 401.000000 148.000000 1074.000000 2346.000000
25% 1524.000000 3435.500000 2328.000000 8205.000000 8601.500000
50% 5790.000000 10588.000000 3202.000000 13044.000000 24494.000000
75% 13330.500000 33289.000000 3918.500000 16099.500000 52510.500000
max 60303.000000 54625.000000 8813.000000 21031.000000 68663.000000
Python有一个很好的统计推断包。那就是scipy里面的stats。ttest_1samp实现了单样本t检验。因此,如果我们想检验数据Abra列的稻谷产量均值,通过零假设,这里我们假定总体稻谷产量均值为15000,我们有:
from scipy import stats as ss
# Perform one sample t-test using 15000 as the true mean
print ss.ttest_1samp(a = df.ix[:, 'Abra'], popmean = 15000)
# OUTPUT
statistic=-1.1281738488299586, pvalue=0.26270472069109496
返回下述值组成的元祖:
t : 浮点或数组类型
t统计量
prob : 浮点或数组类型
two-tailed p-value 双侧概率值
通过上面的输出,看到p值是0.267远大于α等于0.05,因此没有充分的证据说平均稻谷产量不是15000。将这个检验应用到所有的变量,同样假设均值为15000,我们有:
print ss.ttest_1samp(a = df, popmean = 15000)
# OUTPUT
statistic=array([ -1.12817385, 1.07053437, -65.81425599, -4.564575 , 6.17156198]), pvalue=array([2.62704721e-01, 2.87680340e-01, 4.15643528e-70, 1.83764399e-05, 2.82461897e-08]))第一个数组是t统计量,第二个数组则是相应的p值。
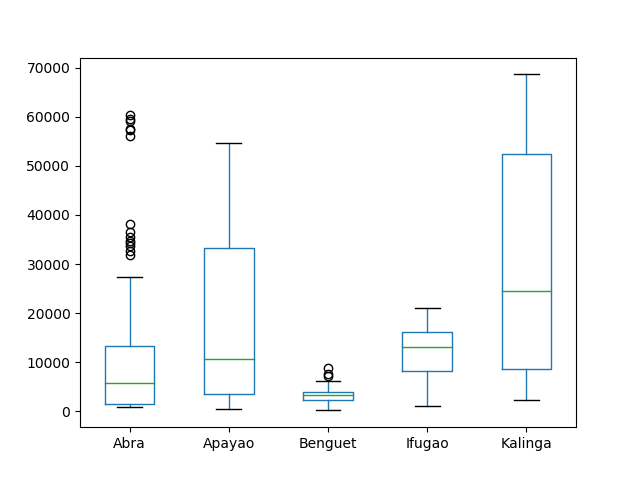
可视化
Python中有许多可视化模块,最流行的当属matpalotlib库。稍加提及,我们也可选择bokeh和seaborn模块。matplotlib库中有个盒须图模块功能。
# Import the module for plotting
import matplotlib.pyplot as plt
plt.show(df.plot(kind = 'box'))
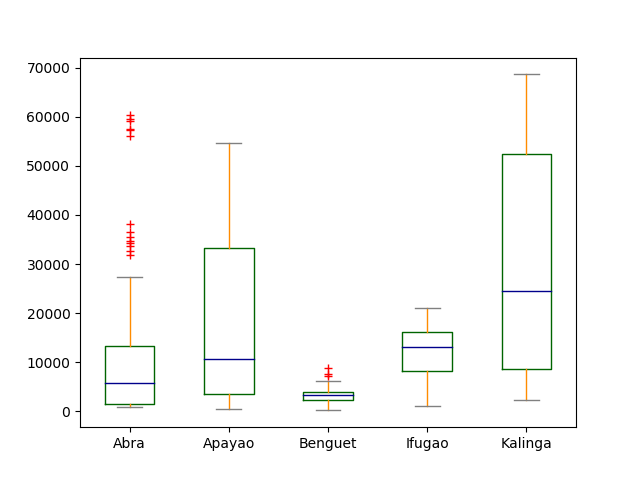
现在,我们也可以来美化图表:
import matplotlib.pyplot as plt
df.plot(kind = 'box')color = dict(boxes='DarkGreen', whiskers='DarkOrange',medians='DarkBlue', caps='Gray')
plt.show(df.plot.box(color=color, sym='r+'))
读取数据
Pandas使用函数read_csv()来读取csv文件
import pandas
food_info = ('food_info.csv')
print(type(food_info))
# 输出:<class 'pandas.core.frame.DataFrame'> 可见读取后变成一个DataFrame变量
该文件的内容如下:

使用函数head( m )来读取前m条数据,如果没有参数m,默认读取前五条数据
first_rows = food_info.head() first_rows = food_info.head(3)
由于DataFrame包含了很多的行和列,
Pandas使用省略号(...)来代替显示全部的行和列,可以使用colums属性来显示全部的列名
print(food_info.columns)
# 输出:输出全部的列名,而不是用省略号代替
Index(['NDB_No', 'Shrt_Desc', 'Water_(g)', 'Energ_Kcal', 'Protein_(g)', 'Lipid_Tot_(g)', 'Ash_(g)', 'Carbohydrt_(g)', 'Fiber_TD_(g)', 'Sugar_Tot_(g)', 'Calcium_(mg)', 'Iron_(mg)', 'Magnesium_(mg)', 'Phosphorus_(mg)', 'Potassium_(mg)', 'Sodium_(mg)', 'Zinc_(mg)', 'Copper_(mg)', 'Manganese_(mg)', 'Selenium_(mcg)', 'Vit_C_(mg)', 'Thiamin_(mg)', 'Riboflavin_(mg)', 'Niacin_(mg)', 'Vit_B6_(mg)', 'Vit_B12_(mcg)', 'Vit_A_IU', 'Vit_A_RAE', 'Vit_E_(mg)', 'Vit_D_mcg', 'Vit_D_IU', 'Vit_K_(mcg)', 'FA_Sat_(g)', 'FA_Mono_(g)', 'FA_Poly_(g)', 'Cholestrl_(mg)'], dtype='object')
可以使用tolist()函数转化为list
food_info.columns.tolist()
与Numpy一样,用shape属性来显示数据的格式
dimensions = food_info.shapeprint(dimensions) print(dimensions)
输出:(8618,36) , 其中dimensions[0]为8618,dimensions[1]为36
与Numpy一样,用dtype属性来显示数据类型,Pandas主要有以下几种dtype:
-
object -- 代表了字符串类型
-
int -- 代表了整型
-
float -- 代表了浮点数类型
-
datetime -- 代表了时间类型
-
bool -- 代表了布尔类型
当读取了一个文件之后,Pandas会通过分析值来推测每一列的数据类型
print()
输出:每一列对应的数据类型
NDB_No int64
Shrt_Desc object
Water_(g) float64
Energ_Kcal int64
Protein_(g) float64
...
索引
读取了文件后,Pandas会把文件的一行作为列的索引标签,使用行数字作为行的索引标签

注意,行标签是从数字0开始的
Pandas使用Series数据结构来表示一行或一列的数据,类似于Numpy使用向量来表示数据。Numpy只能使用数字来索引,而Series可以使用非数字来索引数据,当你选择返回一行数据的时候,Series并不仅仅返回该行的数据,同时还有每一列的标签的名字。
譬如要返回文件的第一行数据,Numpy就会返回一个列表(但你可能不知道每一个数字究竟代表了什么)

而Pandas则会同时把每一列的标签名返回(此时就很清楚数据的意思了)

选择数据
Pandas使用loc[]方法来选择行的数据
# 选择单行数据: food_info.loc[0] # 选择行标号为0的数据,即第一行数据 food_info.loc[6] # 选择行标号为6的数据,即第七行数据 # 选择多行数据: food_info.loc[3:6] # 使用了切片,注意:由于这里使用loc[]函数,所以返回的是行标号为3,4,5,6的数据,与python的切片不同的是这里会返回最后的标号代表的数据,但也可以使用python的切片方法:food_info[3:7] food_info.loc[[2,5,10]] # 返回行标号为2,5,10三行数据 练习:返回文件的最后五行 方法一: length = food_info.shape[0] last_rows = food_info.loc[length-5:length-1] 方法二: num_rows = food_info.shape[0] last_rows = food_info[num_rows-5:num_rows] Pandas直接把列名称填充就能返回该列的数据 ndb_col = food_info["NDB_No"] # 返回列名称为NDB_No的那一列的数据 zinc_copper = food_info[["Zinc_(mg)", "Copper_(mg)"]] # 返回两列数据
简单运算
现在要按照如下公式计算所有食物的健康程度,并按照降序的方式排列结果:
Score=2×(Protein_(g))−0.75×(Lipid_Tot_(g))
对DataFrame中的某一列数据进行算术运算,其实是对该列中的所有元素进行逐一的运算,譬如:
water_energy = food_info["Water_(g)"] * food_info["Energ_Kcal"]
原理:

由于每一列的数据跨度太大,有的数据是从0到100000,而有的数据是从0到10,所以为了尽量减少数据尺度对运算结果的影响,采取最简单的方法来规范化数据,那就是将每个数值都除以该列的最大值,从而使所有数据都处于0和1之间。其中max()函数用来获取该列的最大值.
food_info['Normalized_Protein'] = food_info['Protein_(g)'] / food_info['Protein_(g)'].max()
food_info['Normalized_Fat'] = food_info['Lipid_Tot_(g)'] / food_info['Lipid_Tot_(g)'].max()
food_info['Norm_Nutr_Index'] = food_info["Normalized_Protein"] * 2 - food_info["Normalized_Fat"] * 0.75
注意:上面的两个语句已经在原来的DataFrame中添加了三列,列名分别为Normalized_Protein和Normalized_Fat,Norm_Nutr_Index。只需要使用中括号和赋值符就能添加新列,类似于字典
对DataFrame的某一列数据排序,只需要使用函数sort()即可
food_info.sort("Sodium_(mg)") # 函数参数为列名,默认是按照升序排序,同时返回一个新的
DataFramefood_info.sort("Norm_Nutr_Index", inplace=True, ascending=False )
# 通过inplace参数来控制在原表排序,而不是返回一个新的对象;ascending参数用来控制是否升序排序
import pandas as pd
read_csv()
读写csv数据
df = pd.read_csv(path): 读入csv文件,形成一个数据框(data.frame)
df = pd.read_csv(path, header=None) 不要把第一行作为header
to_csv()
* 注意,默认会将第一行作为header,并且默认会添加index,所以不需要的话需要手动禁用 *
df.to_csv(path, header=False, index=False)
数据框操作
df.head(1) 读取头几条数据
df.tail(1) 读取后几条数据
df[‘date’] 获取数据框的date列
df.head(1)[‘date’] 获取第一行的date列
df.head(1)[‘date’][0] 获取第一行的date列的元素值
sum(df[‘ability’]) 计算整个列的和
df[df[‘date’] == ‘20161111’] 获取符合这个条件的行
df[df[‘date’] == ‘20161111’].index[0] 获取符合这个条件的行的行索引的值
df.iloc[1] 获取第二行
df.iloc[1][‘test2’] 获取第二行的test2值
10 mins to pandas
df.index 获取行的索引
df.index[0] 获取第一个行索引
df.index[-1] 获取最后一个行索引,只是获取索引值
df.columns 获取列标签
df[0:2] 获取第1到第2行,从0开始,不包含末端
df.loc[1] 获取第二行
df.loc[:,’test1’] 获取test1的那一列,这个冒号的意思是所有行,逗号表示行与列的区分
df.loc[:,[‘test1’,’test2’]] 获取test1列和test2列的数据
df.loc[1,[‘test1’,’test2’]] 获取第二行的test1和test2列的数据
df.at[1,’test1’] 表示取第二行,test1列的数据,和上面的方法类似
df.iloc[0] 获取第一行
df.iloc[0:2,0:2] 获取前两行前两列的数据
df.iloc[[1,2,4],[0,2]] 获取第1,2,4行中的0,2列的数据
(df[2] > 1).any() 对于Series应用any()方法来判断是否有符合条件的

一、 创建对象
可以通过 Data Structure Intro Setion 来查看有关该节内容的详细信息。
1、可以通过传递一个list对象来创建一个Series,pandas会默认创建整型索引:

2、通过传递一个numpy array,时间索引以及列标签来创建一个DataFrame:

3、通过传递一个能够被转换成类似序列结构的字典对象来创建一个DataFrame:

4、查看不同列的数据类型:

5、如果你使用的是IPython,使用Tab自动补全功能会自动识别所有的属性以及自定义的列,下图中是所有能够被自动识别的属性的一个子集:

二、 查看数据
详情请参阅:Basics Section
1、 查看frame中头部和尾部的行:

2、 显示索引、列和底层的numpy数据:

3、 describe()函数对于数据的快速统计汇总:
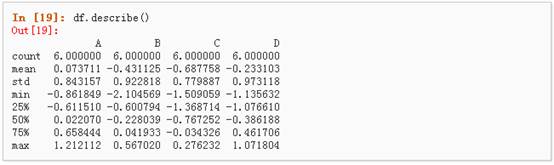
4、 对数据的转置:

5、 按轴进行排序
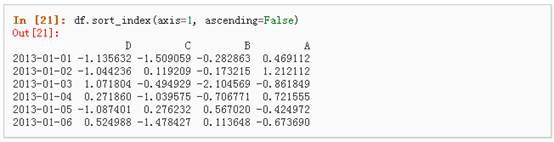
6、 按值进行排序
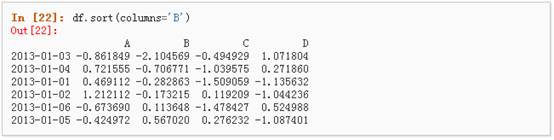
三、 选择
虽然标准的Python/Numpy的选择和设置表达式都能够直接派上用场,但是作为工程使用的代码,我们推荐使用经过优化的pandas数据访问方式: .at, .iat, .loc, .iloc 和 .ix详情请参阅Indexing and Selecing Data 和 MultiIndex / Advanced Indexing。
l 获取
1、 选择一个单独的列,这将会返回一个Series,等同于df.A:

2、 通过[]进行选择,这将会对行进行切片
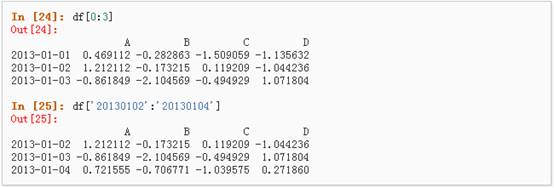
l 通过标签选择
1、 使用标签来获取一个交叉的区域
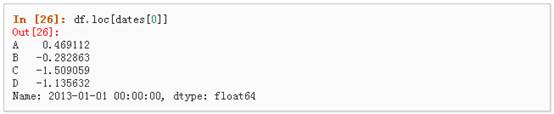
2、 通过标签来在多个轴上进行选择

3、 标签切片

4、 对于返回的对象进行维度缩减

5、 获取一个标量
![]()
6、 快速访问一个标量(与上一个方法等价)
![]()
l 通过位置选择
1、 通过传递数值进行位置选择(选择的是行)
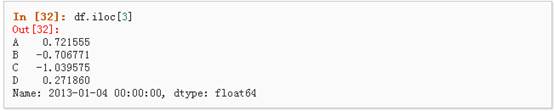
2、 通过数值进行切片,与numpy/python中的情况类似

3、 通过指定一个位置的列表,与numpy/python中的情况类似

4、 对行进行切片

5、 对列进行切片

6、 获取特定的值

l 布尔索引
1、 使用一个单独列的值来选择数据:

2、 使用where操作来选择数据:

3、 使用isin()方法来过滤:

l 设置
1、 设置一个新的列:

2、 通过标签设置新的值:
![]()
3、 通过位置设置新的值:
![]()
4、 通过一个numpy数组设置一组新值:
![]()
上述操作结果如下:
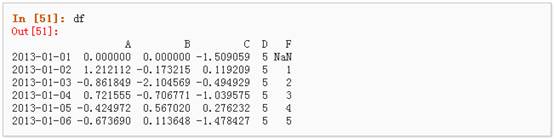
5、 通过where操作来设置新的值:

四、 缺失值处理
在pandas中,使用np.nan来代替缺失值,这些值将默认不会包含在计算中,详情请参阅:Missing Data Section。
1、 reindex()方法可以对指定轴上的索引进行改变/增加/删除操作,这将返回原始数据的一个拷贝:、

2、 去掉包含缺失值的行:

3、 对缺失值进行填充:

4、 对数据进行布尔填充:

五、 相关操作
详情请参与 Basic Section On Binary Ops
-
统计(相关操作通常情况下不包括缺失值)
1、 执行描述性统计:

2、 在其他轴上进行相同的操作:

3、 对于拥有不同维度,需要对齐的对象进行操作。Pandas会自动的沿着指定的维度进行广播:
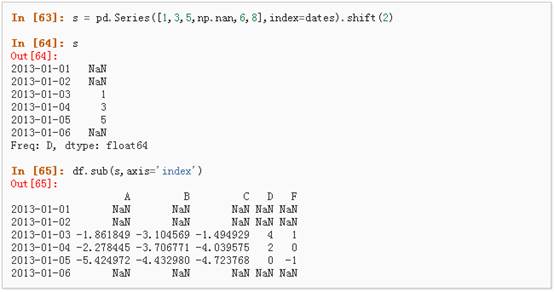
-
Apply
1、 对数据应用函数:

-
直方图
具体请参照:Histogramming and Discretization

-
字符串方法
Series对象在其str属性中配备了一组字符串处理方法,可以很容易的应用到数组中的每个元素,如下段代码所示。更多详情请参考:Vectorized String Methods.

六、 合并
Pandas提供了大量的方法能够轻松的对Series,DataFrame和Panel对象进行各种符合各种逻辑关系的合并操作。具体请参阅:Merging section
-
Concat

-
Join 类似于SQL类型的合并,具体请参阅:Database style joining

-
Append 将一行连接到一个DataFrame上,具体请参阅Appending:
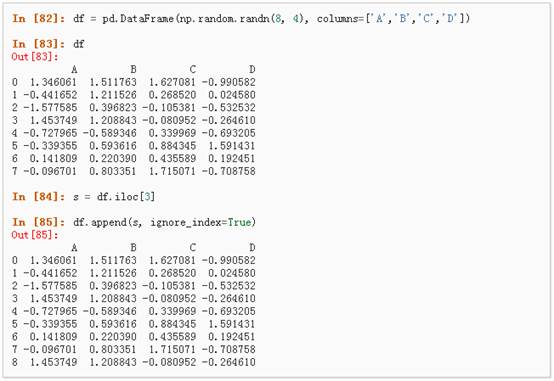
七、 分组
对于”group by”操作,我们通常是指以下一个或多个操作步骤:
-
(Splitting)按照一些规则将数据分为不同的组;
-
(Applying)对于每组数据分别执行一个函数;
-
(Combining)将结果组合到一个数据结构中;
详情请参阅:Grouping section

1、 分组并对每个分组执行sum函数:

2、 通过多个列进行分组形成一个层次索引,然后执行函数:
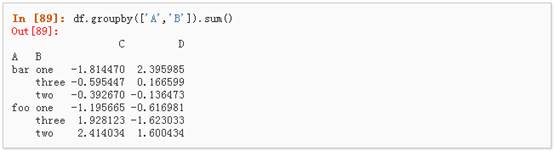
八、 Reshaping
详情请参阅 Hierarchical Indexing 和 Reshaping。
-
Stack



-
数据透视表,详情请参阅:Pivot Tables.
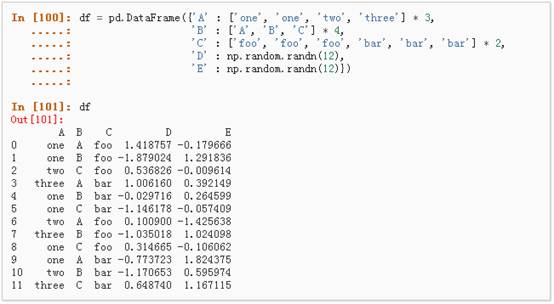
可以从这个数据中轻松的生成数据透视表:

九、 时间序列
Pandas在对频率转换进行重新采样时拥有简单、强大且高效的功能(如将按秒采样的数据转换为按5分钟为单位进行采样的数据)。这种操作在金融领域非常常见。具体参考:Time Series section。
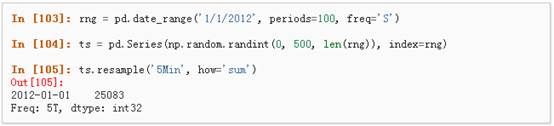
1、 时区表示:
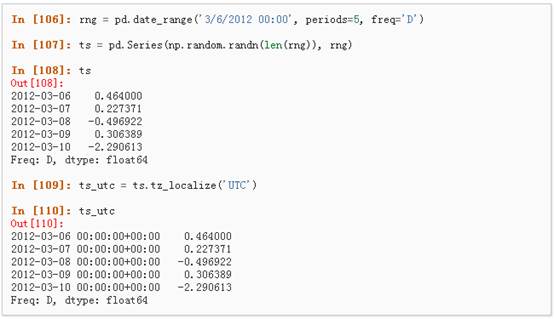
2、 时区转换:

3、 时间跨度转换:
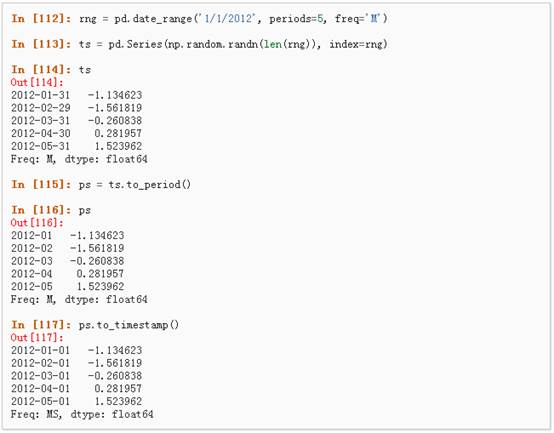
4、 时期和时间戳之间的转换使得可以使用一些方便的算术函数。

十、 Categorical
从0.15版本开始,pandas可以在DataFrame中支持Categorical类型的数据,详细 介绍参看:categorical introduction和API documentation。

1、 将原始的grade转换为Categorical数据类型:

2、 将Categorical类型数据重命名为更有意义的名称:
![]()
3、 对类别进行重新排序,增加缺失的类别:

4、 排序是按照Categorical的顺序进行的而不是按照字典顺序进行:

5、 对Categorical列进行排序时存在空的类别:

十一、 画图
具体文档参看:Plotting docs

对于DataFrame来说,plot是一种将所有列及其标签进行绘制的简便方法:


十二、 导入和保存数据
-
CSV,参考:Writing to a csv file
1、 写入csv文件:
![]()
2、 从csv文件中读取:

-
HDF5,参考:HDFStores
1、 写入HDF5存储:
![]()
2、 从HDF5存储中读取:

-
Excel,参考:MS Excel
1、 写入excel文件:
![]()
2、 从excel文件中读取:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号