python之路_并发编程之多线程1
一、多线程相关概念
1.线程的定义
在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程,线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程是一个进程。车间负责把资源整合到一起,是一个资源单位,而一个车间内至少有一个流水线,流水线的工作需要电源,电源就相当于cpu。所以,进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。
多线程(即多个控制线程)的概念是,在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源。
2.线程的特点
开销小的特点:类比车间与流水线的关系,开启进程需要申请一个空间,并至少开启一条流水线(线程),而线程只是在车间(进程)中开一条流水线,不需要申请空间。
3.多线程应用
多线程指的是,在一个进程中开启多个线程,简单的讲:如果多个任务共用一块地址空间,那么必须在一个进程内开启多个线程。详细的讲分为4点:
(1)多线程共享一个进程的地址空间。
(2)线程比进程更轻量级,线程比进程更容易创建可撤销,在许多操作系统中,创建一个线程比创建一个进程要快10-100倍,在有大量线程需要动态和快速修改时,这一特性很有用。
(3)若多个线程都是cpu密集型的,那么并不能获得性能上的增强,但是如果存在大量的计算和大量的I/O处理,拥有多个线程允许这些活动彼此重叠运行,从而会加快程序执行的速度。
(4)在多cpu系统中,为了最大限度的利用多核,可以开启多个线程,比开进程开销要小的多。(并不适用于python)
二、开启线程的方式
方式一:
from threading import Thread def work(n): print('%s is running' %n) if __name__ == '__main__': for i in range(4): t=Thread(target=work,args=(i,)) t.start() print('主') ''' 输出结果为: 0 is running 1 is running 2 is running 3 is running 主 '''
方式二:
from threading import Thread class Mythread(Thread): def __init__(self,n): super().__init__() self.n=n def run(self): print('%s is running' %self.n) if __name__ == '__main__': for i in range(4): t=Mythread(i) t.start() print('主') ''' 输出结果为: 0 is running 1 is running 2 is running 3 is running 主 '''
三、方法及实例
1、线程共享进程中的资源
from threading import Thread n=100 def work(): global n n=0 if __name__ == '__main__': t=Thread(target=work) t.start() t.join() print(n) #输出结果:0
结果分析:t线程执行完成后将主进程中的n进行了更改,并得以保存下来,所以当执行完线程t后,主进程打印得到n的结果为0
from multiprocessing import Process import time n=100 def work(): time.sleep(1) global n n=0 if __name__ == '__main__': p=Process(target=work) p.start() p.join() print(n) #输出结果:100
结果分析:进程的特点是彼此间是独立的空间,故开启子进程p的时候,将主进程的内容进行了单独的拷贝,子进程执行函数时,是将自己拷贝内容的n进行了更改,而打印主进程中的n时,n值不会发生变化。
2、运行速度比较
同一进程开多线程情况:
import os from threading import Thread def work(n): print('子线程%s:%s' %(n+1,os.getpid())) if __name__ == '__main__': for i in range(2): t=Thread(target=work,args=(i,)) t.start() print('主进程:%s'%os.getpid()) ''' 子线程1:8784 子线程2:8784 主进程:8784 '''
结果分析:从以上结果可以看出,线程的执行速度很快,线程开启就瞬间完成执行,故先打印子线程中的内容,最后才打印主进程中的内容,且线程中pid与进程一致。
同一进程开多进程情况:
import os from multiprocessing import Process def work(n): print('子进程%s:%s' %(n+1,os.getpid())) if __name__ == '__main__': for i in range(2): p=Process(target=work,args=(i,)) p.start() print('主进程:%s'%os.getpid()) ''' 主进程:7208 子进程1:8024 子进程2:4072 '''
结果分析:由于进程间彼此之间是独立的空间,开启进程的损耗比线程大,所以在主进程中发出开启子进程后,子进程未执行完,主进程便打印出主进程内容,且各进程的pid各不相同。
3、线程主要方法实例
from threading import Thread,current_thread,enumerate,activeCount def work(): print('%s is running' %(current_thread().getName())) #获取当前线程的名字 if __name__ == '__main__': t=Thread(target=work) t.start() print(enumerate()) #当前活跃线程 print(activeCount()) #当前活跃线程数量 t.join()
四、守护线程
无论是进程还是线程,都遵循:守护xxx会等待主xxx运行完毕后被销毁,需要强调的是:运行完毕并非终止运行。对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕。
实例:
from threading import Thread import time def foo(): print(123) time.sleep(5) print('end123') def bar(): print('start456') time.sleep(3) print('end456') if __name__ == '__main__': t1=Thread(target=foo) t2=Thread(target=bar) t1.daemon=True #必须放在start()前 t1.start() t2.start() print('main') ''' 123 start456 main end456 '''
结果分析:t1为守护线程,与守护进程不一样(主进程代码结束,则就结束守护进程),主线程代码结束后待非守护线程代码都执行完成,才能结束守护线程。
五、GIL互斥锁
在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势。为什么会这样呢?
1、python程序执行顺序
如执行test.py程序,都会开启python一个进程,代码中包含多个线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有线程都运行在这一个进程内,毫无疑问。
执行流程:多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码去执行,解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,而这把锁就是GIL,保证python解释器同一时间只能执行一个任务的代码。
2、GIL锁介绍
GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理,如下图主进程中开启了两个线程,由于线程1先拿到解释器的GIL锁,故向cpu传送指令执行此线程,若此线程在执行过程遇到IO阻塞,被解释器强行要求释放GIL锁,线程2进入解释器执行相应代码,等线程1再次拿到解释器的权限时,继续执行其剩余程序。
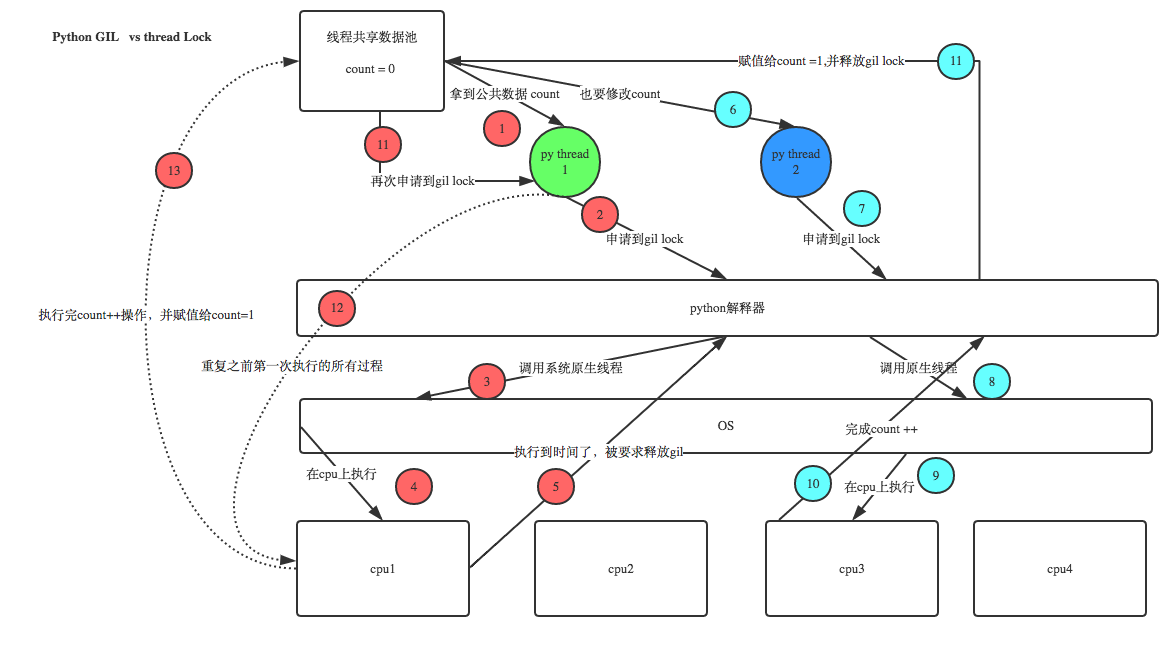
3.多线程与GIL
有了GIL存在,同一时刻同一进程中只有一个线程被执行。但是多线程仍然存在它的意义,解释如下:
案例:我们有四个任务需要处理,处理方式肯定是要玩出并发的效果,解决方案可以是:方案一:开启四个进程,方案二:一个进程下,开启四个线程。
#单核情况下,分析结果: 如果四个任务是计算密集型,没有多核来并行计算,方案一徒增了创建进程的开销,方案二胜 如果四个任务是I/O密集型,方案一创建进程的开销大,且进程的切换速度远不如线程,方案二胜 #多核情况下,分析结果: 如果四个任务是计算密集型,多核意味着并行计算,在python中一个进程中同一时刻只有一个线程执行用不上多核,方案一胜 如果四个任务是I/O密集型,再多的核也解决不了I/O问题,方案二胜
结论:现在的计算机基本上都是多核,python对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
(1)计算密集型实例
多线程:
from threading import Thread import time def work(): res=0 for i in range(100000000): res*=i if __name__ == '__main__': start=time.time() result=[] for i in range(4):#因为4核,所以开启4个进程 p=Thread(target=work) result.append(p) p.start() for p in result: p.join() end=time.time() print(end-start) #24.468851566314697
#多进程:
from multiprocessing import Process import time def work(): res=0 for i in range(100000000): res*=i if __name__ == '__main__': start=time.time() result=[] for i in range(4):#因为4核,所以开启4个进程 p=Process(target=work) result.append(p) p.start() for p in result: p.join() end=time.time() print(end-start) #15.74721097946167
分析:对于多进程情况,所开4个进程分别在4个cpu上同时进行执行,所花时间为开启进程时间和单个进程运行时间的总和,对于多线程情况,其都在竞争解释器权限,排队进行执行代码,所化时间为四个线程的总和。多线程花费时间未与多进程花费时间呈4倍关系是因为开启进程开销比开启线程开销大很多。
(2)IO密集型实例
多线程:
from threading import Thread import time def work(): time.sleep(2) if __name__ == '__main__': start=time.time() result=[] for i in range(400): p=Thread(target=work) result.append(p) p.start() for p in result: p.join() end=time.time() print(end-start) #2.049804925918579
多进程:
from multiprocessing import Process import time def work(): time.sleep(2) if __name__ == '__main__': start = time.time() result = [] for i in range(400): p = Process(target=work) result.append(p) p.start() for p in result: p.join() end = time.time() print(end - start) # 27.082503080368042
分析:对于多线程情况,线程遇到阻塞,便会切换到另个线程,所化总时间就为花时间最长的单个线程的时间,对于多进程情况,同时开启这么多进程会花费很多时间,其次单个进程执行遇到阻塞时,若没有其他任务也会继续等待阻塞结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号