Zookeeper系列(4):搭建Zookeeper集群
简介
Zookeeper集群主要解决单节点故障问题以及提高整体并发访问能力。
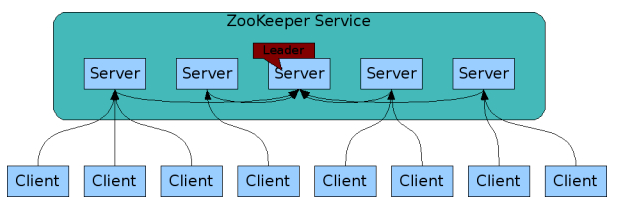
Zookeeper集群具有以下特点:
-
Zookeeper集群有一个leader服务器和多个follower服务器,leader是运行时动态选举出来的。
-
Zookeeper集群中只要由半数以上的节点可用,Zookeeper集群就能正常提供服务。
-
Zookeeper集群中每个服务器保存一份相同的数据副本,客户端无论连接哪台服务器,数据都是一致的。
-
更新请求顺序进行,来自同一个客户端的更新请求按其发送的顺序依次执行。
-
数据更新原子性,一次数据要么更新成功,要么更新失败。
-
实时性,在一定时间范围内,客户端能读到最新数据。
集群搭建
搭建Zookeeper集群至少需要三台服务器,并且服务器应该是奇数台。
假如集群只有两台服务器,那么其中任意一台服务器发生故障,集群就不可用了(集群中可用节点数量需要大于一半才可用),由于存在两个单点故障,因此两个服务器还不如单个服务器稳定。
下面将介绍如何在单台机器上搭建三个Zookeeper服务组成的集群。
1.创建三个dataDir:
mkdir /opt/zkdata1 /opt/zkdata2 /opt/zkdata3
2.分别在三个dataDir中创建myid文件,并在myid文件中指定服务器标识:
[root@localhost opt]# touch ./zkdata1/myid ./zkdata2/myid ./zkdata3/myid
[root@localhost opt]# echo 1 > ./zkdata1/myid
[root@localhost opt]# echo 2 > ./zkdata2/myid
[root@localhost opt]# echo 3 > ./zkdata3/myid
3.创建三个Zookeeper配置文件,并添加集群配置:
zoo1.cfg:
tickTime=2000
initLimit=10
syncLimit=5
# 指定数据存储位置
dataDir=/opt/zkdata1
# 指定客户端连接的端口
clientPort=2181
# 指定集群中服务器
# 端口1:用于数据同步
# 端口2:用于leader选举
server.1=localhost:2880:3881
server.2=localhost:2882:3883
server.3=localhost:2884:3885
zoo2.cfg:
tickTime=2000
initLimit=10
syncLimit=5
# 指定数据存储位置
dataDir=/opt/zkdata2
# 指定客户端连接的端口
clientPort=2182
# 指定集群中服务器
# 端口1:用于数据同步
# 端口2:用于leader选举
server.1=localhost:2880:3881
server.2=localhost:2882:3883
server.3=localhost:2884:3885
zoo3.cfg:
tickTime=2000
initLimit=10
syncLimit=5
# 指定数据存储位置
dataDir=/opt/zkdata3
# 指定客户端连接的端口
clientPort=2183
# 指定集群中服务器
# 端口1:用于数据同步
# 端口2:用于leader选举
server.1=localhost:2880:3881
server.2=localhost:2882:3883
server.3=localhost:2884:3885
4.分别启动各个服务器:
依次启动服务器1、2、3。
[root@localhost opt]# ./apache-zookeeper-3.6.3-bin/bin/zkServer.sh start ./apache-zookeeper-3.6.3-bin/conf/zoo1.cfg
ZooKeeper JMX enabled by default
Using config: ./apache-zookeeper-3.6.3-bin/conf/zoo1.cfg
Starting zookeeper ... STARTED
[root@localhost opt]# ./apache-zookeeper-3.6.3-bin/bin/zkServer.sh start ./apache-zookeeper-3.6.3-bin/conf/zoo2.cfg
ZooKeeper JMX enabled by default
Using config: ./apache-zookeeper-3.6.3-bin/conf/zoo2.cfg
Starting zookeeper ... STARTED
[root@localhost opt]# ./apache-zookeeper-3.6.3-bin/bin/zkServer.sh start ./apache-zookeeper-3.6.3-bin/conf/zoo3.cfg
ZooKeeper JMX enabled by default
Using config: ./apache-zookeeper-3.6.3-bin/conf/zoo3.cfg
Starting zookeeper ... STARTED
5.集群搭建完毕,可以使用客户端连接任意一台服务器进行操作:
连接服务器3,创建新的节点,连接服务器1,查看新创建的节点。
[root@localhost opt]# ./apache-zookeeper-3.6.3-bin/bin/zkCli.sh -server localhost:2183
[zk: localhost:2183(CONNECTED) 1] ls /
[zookeeper]
[zk: localhost:2183(CONNECTED) 2] create /mynode1 mydata1
Created /mynode1
[root@localhost opt]# ./apache-zookeeper-3.6.3-bin/bin/zkCli.sh -server localhost:2181
[zk: localhost:2181(CONNECTED) 1] ls /
[mynode1, zookeeper]
选举机制
集群中节点状态分为以下几种:
-
LOOKING:表示当前集群中没有leader节点,需要进行选举。
-
LEADING:表示当前节点为leader。
-
FOLLOWING:表示leader已经被选出,当前节点为follower。
-
OBSERVER:表示当前节点为observer。
查看集群中各个服务器角色信息:
[root@localhost opt]# ./apache-zookeeper-3.6.3-bin/bin/zkServer.sh status ./apache-zookeeper-3.6.3-bin/conf/zoo1.cfg
ZooKeeper JMX enabled by default
Using config: ./apache-zookeeper-3.6.3-bin/conf/zoo1.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@localhost opt]# ./apache-zookeeper-3.6.3-bin/bin/zkServer.sh status ./apache-zookeeper-3.6.3-bin/conf/zoo2.cfg
ZooKeeper JMX enabled by default
Using config: ./apache-zookeeper-3.6.3-bin/conf/zoo2.cfg
Client port found: 2182. Client address: localhost. Client SSL: false.
Mode: leader
[root@localhost opt]# ./apache-zookeeper-3.6.3-bin/bin/zkServer.sh status ./apache-zookeeper-3.6.3-bin/conf/zoo3.cfg
ZooKeeper JMX enabled by default
Using config: ./apache-zookeeper-3.6.3-bin/conf/zoo3.cfg
Client port found: 2183. Client address: localhost. Client SSL: false.
Mode: follower
可以看出服务器2被选举为leader,服务器1和服务器3为follower。选举流程如下:
-
服务器1和服务器2启动后进入LOOKING状态,开始进行Leader选举。
-
每个服务器都会发出一个投票,在初始阶段,服务器1和服务器2将投票自己作为Leader服务器,每次投票都会包含推荐服务器的myid和zxid,然后将每个投票发送给集群中的其他服务器。
-
集群中的每个服务器接收到投票后,首先判断投票的有效性,例如是否为当前轮投票,是否来自处于LOOKING状态的服务器。
-
每个服务器都会将其他服务器的投票和自己的投票进行对比,首先对比zxid,较大zxid的服务器优先作为leader。如果zxid一样,则比较myid,myid较大的优先作为leader。
-
由于是集群初始化阶段,每个服务器的zxid都为0,所以开始比较myid,服务器2的myid较大,所以服务器2获胜。服务器1将其投票更新为投给服务器2,并将投票重新发送给服务器2,此时服务器的票数已经超过集群节点半数,服务器2被选为leader。
-
一旦确定了leader,每个服务器将更新自己的状态。服务器1将状态改为FOLLOWING,服务器2将状态改为LEADING,当服务器3启动时,发现已经有一个Leader,不再进行选举,直接将状态从LOOKING改为FOLLOWING。
当作为leader的服务器2被停止后,又会重新进行leader选举。停止服务器2:
[root@localhost opt]# ./apache-zookeeper-3.6.3-bin/bin/zkServer.sh stop ./apache-zookeeper-3.6.3-bin/conf/zoo2.cfg
ZooKeeper JMX enabled by default
Using config: ./apache-zookeeper-3.6.3-bin/conf/zoo2.cfg
Stopping zookeeper ... STOPPED
再次查看各个服务器角色信息:
[root@localhost opt]# ./apache-zookeeper-3.6.3-bin/bin/zkServer.sh status ./apache-zookeeper-3.6.3-bin/conf/zoo1.cfg
ZooKeeper JMX enabled by default
Using config: ./apache-zookeeper-3.6.3-bin/conf/zoo1.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@localhost opt]# ./apache-zookeeper-3.6.3-bin/bin/zkServer.sh status ./apache-zookeeper-3.6.3-bin/conf/zoo3.cfg
ZooKeeper JMX enabled by default
Using config: ./apache-zookeeper-3.6.3-bin/conf/zoo3.cfg
Client port found: 2183. Client address: localhost. Client SSL: false.
Mode: leader
此时服务器3被选举为leader,原因是服务器3最近创建了节点,拥有了比服务器1更大的zxid,所以服务器3被选举为leader。(节点的变化会导致zxid递增)
数据写入流程
在Zookeeper集群中,客户端可用连接集群中任意一台服务器进行操作。
如果是读请求,则直接从当前服务器读取数据。
如果是写请求则分为以下步骤:
-
如果请求的服务器不是leader,则当前请求的服务器会把请求转发给leader。
-
leader将写请求广播给各个服务器,各个服务器写成功后会通知leader。
-
当leader收到大多数服务器写成功的通知,则表示写入成功,leader将通知之前的接收请求的服务器,由它进一步的通知客户端写入成功。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号