[转]python执行系统命令,怎么就卡死了?
最近很忙,术后恢复也很久没有去更新博客了。
来自陌陌安全团队的文章,但是python 执行系统命令popen方法设置了stdout或者stderr,创建子进程把pipe size填满之前没有具体了解,终于知道原因了,也顺手记录一下。
====================================================
title: python执行系统命令,怎么就卡死了?
发生背景
本次问题的发现,主要来源于最近的一个需求,调用第三方工具扫描从gitlab中拉下来项目的依赖信息。其实这个需求要实现的功能比较简单,核心就是在拉下来的项目目录下执行第三方工具,然后读取该工具产生的结果文件,处理后写到回数据库中。
发生过程
该脚本开发完毕后,在经过了单元测试和在测试机器中的完整流程测试后,就在生产环境中上线了。但上线后却发现,扫描任务队列的的数据并没有像预想的那样被消费掉,于是开始检查日志,但并没有发现任何的异常信息。
接着尝试记录更加详细日志进行排错,并在观察中有如下发现:
①并不是所有的任务都会卡死;
②同一个任务第一次执行卡死,第二次重新执行就正常了。
这里我第一个排除掉的原因是当前代码中的逻辑问题,再次仔细观察日志后终于发现了端倪:每次发生的卡死现象都发生在了执行系统命令上,于是开始重点关注命令调用逻辑的代码。
问题分析
下面是问题代码:

由于在之前的脚本中写过不少类似的功能,但大多使用的都是io模块中的os.popen()方法,在新版的python中推荐使用subprocess模块来替代一些旧的模块,于是这次也改成了新的方式,但问题也随之被引入了。
我们先手动调用下这个工具来分析下这个项目的依赖:
https://github.com/momosecurity/mosec-maven-plugin
这个工具的使用也比较简单,具体使用方式可以参考github上的说明,先看看它的输出:

这里需要注意的是,在执行过程中会输出大量的下载信息。
然后我们回到上面的问题代码中,当popen方法设置了stdout或者stderr参数后,系统会创建一个管道用于和子进程进行通信,而上面输出的大量下载信息会把创建的管道填满,进而使得后续的内容无法继续写入管道中,这样整个程序就卡死了。此外这里也没及时读取管道的数据,而是一直等待子进程完成,于是就发生了我们最常见的死锁情况,所以最后的表现就是脚本卡死了。
但是当我们第二次重启脚本运行的时候,由于缓存的存在,使得之前大量的下载信息没有被打印出来,所以这次程序输出的内容少了很多,也就不会把上面的管道填满了。
通过查询我们机器的信息,可以看到当前Linux系统管道的默认大小是4kB(8 * 512B = 4kB),而在第二次调用的时候因为输出的数据明显小于4kB,这才有了第一次卡死,第二次却执行成功的现象。

此外在Python的官方文档*中也在wait方法和stderr属性中做了明确的标注:
当
stdout=PIPE或者 stderr=PIPE 并且子进程产生了足以阻塞 OS 管道缓冲区接收更多数据的输出到管道时,将会发生死锁。当使用管道时用 Popen.communicate() 来规避它。
警告:
使用 communicate() 而非 .stdin.write, .stdout.read 或者 .stderr.read 来避免由于任意其他 OS 管道缓冲区被子进程填满阻塞而导致的死锁。
问题解决
这里是我们修改后的代码:

虽然官方推荐是使用communicate方法来解决上面的问题,但我们只是为了获得输出,并尽可能的避免其他可能发生的问题,就直接使用check_output方法来替代。此外我们还可以看到,在check_output方法中也确实使用了communicate:
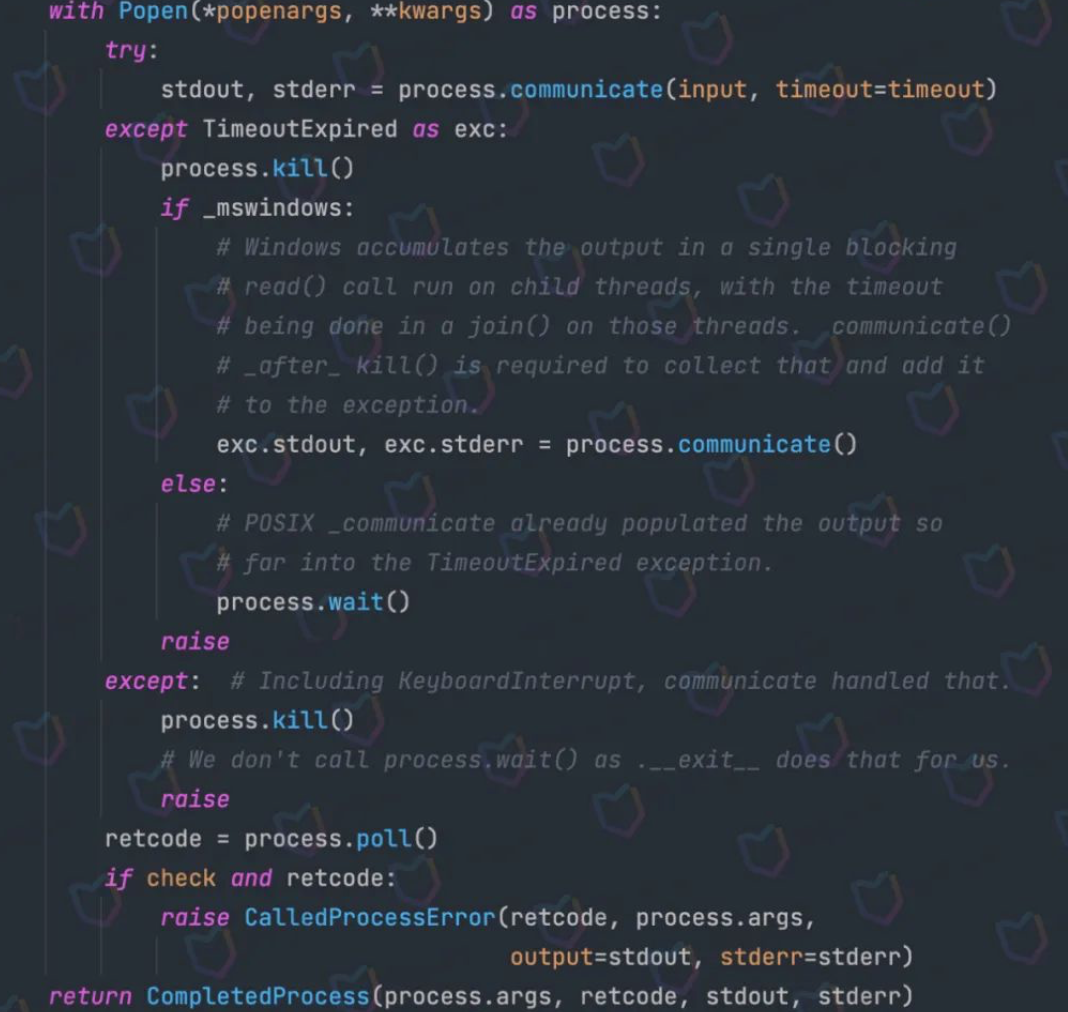
总结
为了实现某个功能,我们最常见方式就是在网上搜出来一些代码,然后不经思考就直接粘贴复制到我们的项目中,但这可能会隐藏很多难以发现的问题。这时候最好的方式就是确定好代码中的每一个方法有没有问题,尤其是对于不熟悉的方法,好好看看官方的文档,或许会有意想不到收获。
参考
[*] Python官方文档 https://docs.python.org/zh-cn/3.7/library/subprocess.html
来源:
https://mp.weixin.qq.com/s/CJK-_yMo_VN1_yIUiO787w

 浙公网安备 33010602011771号
浙公网安备 33010602011771号