
深入学习Heritrix---解析Frontier(链接工厂)(转)
深入学习Heritrix---解析Frontier(链接工厂)
Frontier是Heritrix最核心的组成部分之一,也是最复杂的组成部分.它主要功能是为处理链接的线程提供URL,并负责链接处理完成后的一些后续调度操作.并且为了提高效率,它在内部使用了Berkeley DB.本节将对它的内部机理进行详细解剖.
在Heritrix的官方文档上有一个Frontier的例子,虽然很简单,但是它却解释Frontier实现的基本原理.在这里就不讨论,有兴趣的读者可以参考相应文档.但是不得不提它的三个核心方法:
(1)next(int timeout):为处理线程提供一个链接.Heritrix的所有处理线程(ToeThread)都是通过调用该方法获取链接的.
(2)schedule(CandidateURI caURI):调度待处理的链接.
(3)finished(CrawlURI cURI):完成一个已处理的链接.
整体结构如下:
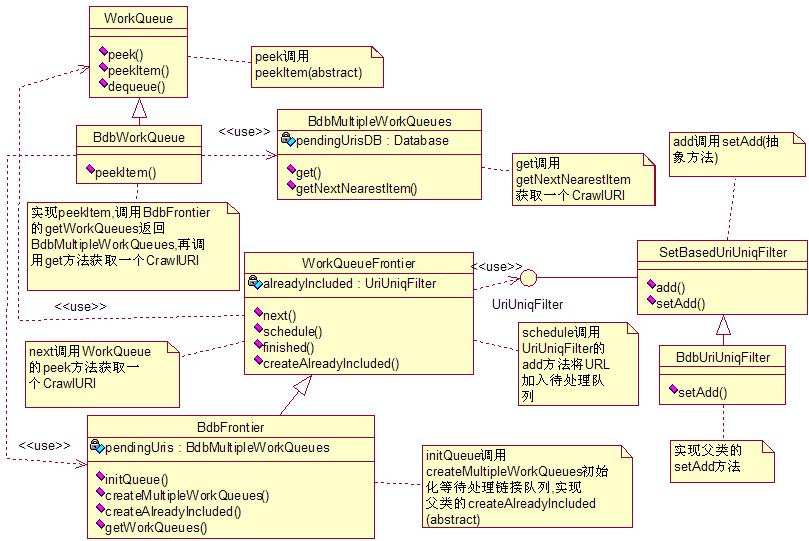
BdbMultipleWorkQueues:
它是对Berkeley DB的简单封装.在内部有一个Berkeley Database,存放所有待处理的链接.
 package org.archive.crawler.frontier;public class BdbMultipleWorkQueues
package org.archive.crawler.frontier;public class BdbMultipleWorkQueues  {
{ //存放所有待处理的URL的数据库 private Database pendingUrisDB = null; //由key获取一个链接 public CrawlURI get(DatabaseEntry headKey)
//存放所有待处理的URL的数据库 private Database pendingUrisDB = null; //由key获取一个链接 public CrawlURI get(DatabaseEntry headKey) throws DatabaseException { DatabaseEntry result = new DatabaseEntry(); // From Linda Lee of sleepycat: // "You want to check the status returned from Cursor.getSearchKeyRange // to make sure that you have OperationStatus.SUCCESS. In that case, // you have found a valid data record, and result.getData() // (called by internally by the binding code, in this case) will be // non-null. The other possible status return is // OperationStatus.NOTFOUND, in which case no data record matched // the criteria. " //由key获取相应的链接 OperationStatus status = getNextNearestItem(headKey, result); CrawlURI retVal = null; if (status != OperationStatus.SUCCESS) { LOGGER.severe("See '1219854 NPE je-2.0 " + "entryToObject
throws DatabaseException { DatabaseEntry result = new DatabaseEntry(); // From Linda Lee of sleepycat: // "You want to check the status returned from Cursor.getSearchKeyRange // to make sure that you have OperationStatus.SUCCESS. In that case, // you have found a valid data record, and result.getData() // (called by internally by the binding code, in this case) will be // non-null. The other possible status return is // OperationStatus.NOTFOUND, in which case no data record matched // the criteria. " //由key获取相应的链接 OperationStatus status = getNextNearestItem(headKey, result); CrawlURI retVal = null; if (status != OperationStatus.SUCCESS) { LOGGER.severe("See '1219854 NPE je-2.0 " + "entryToObject '. OperationStatus " + " was not SUCCESS: " + status + ", headKey " + BdbWorkQueue.getPrefixClassKey(headKey.getData())); return null;
'. OperationStatus " + " was not SUCCESS: " + status + ", headKey " + BdbWorkQueue.getPrefixClassKey(headKey.getData())); return null; } try { retVal = (CrawlURI)crawlUriBinding.entryToObject(result); } catch (RuntimeExceptionWrapper rw) { LOGGER.log( Level.SEVERE, "expected object missing in queue " + BdbWorkQueue.getPrefixClassKey(headKey.getData()), rw); return null; } retVal.setHolderKey(headKey); return retVal;//返回链接 } //从等处理列表获取一个链接 protected OperationStatus getNextNearestItem(DatabaseEntry headKey, DatabaseEntry result) throws DatabaseException { Cursor cursor = null; OperationStatus status; try { //打开游标 cursor = this.pendingUrisDB.openCursor(null, null); // get cap; headKey at this point should always point to // a queue-beginning cap entry (zero-length value) status = cursor.getSearchKey(headKey, result, null); if(status!=OperationStatus.SUCCESS || result.getData().length > 0) { // cap missing throw new DatabaseException("bdb queue cap missing"); } // get next item (real first item of queue) status = cursor.getNext(headKey,result,null); } finally { if(cursor!=null) { cursor.close(); } } return status; } /** * Put the given CrawlURI in at the appropriate place. * 添加URL到数据库 * @param curi * @throws DatabaseException */ public void put(CrawlURI curi, boolean overwriteIfPresent) throws DatabaseException { DatabaseEntry insertKey = (DatabaseEntry)curi.getHolderKey(); if (insertKey == null) { insertKey = calculateInsertKey(curi); curi.setHolderKey(insertKey); } DatabaseEntry value = new DatabaseEntry(); crawlUriBinding.objectToEntry(curi, value); // Output tally on avg. size if level is FINE or greater. if (LOGGER.isLoggable(Level.FINE)) { tallyAverageEntrySize(curi, value); } OperationStatus status; if(overwriteIfPresent) { //添加 status = pendingUrisDB.put(null, insertKey, value); } else { status = pendingUrisDB.putNoOverwrite(null, insertKey, value); } if(status!=OperationStatus.SUCCESS) { LOGGER.severe("failed; "+status+ " "+curi); } }
} try { retVal = (CrawlURI)crawlUriBinding.entryToObject(result); } catch (RuntimeExceptionWrapper rw) { LOGGER.log( Level.SEVERE, "expected object missing in queue " + BdbWorkQueue.getPrefixClassKey(headKey.getData()), rw); return null; } retVal.setHolderKey(headKey); return retVal;//返回链接 } //从等处理列表获取一个链接 protected OperationStatus getNextNearestItem(DatabaseEntry headKey, DatabaseEntry result) throws DatabaseException { Cursor cursor = null; OperationStatus status; try { //打开游标 cursor = this.pendingUrisDB.openCursor(null, null); // get cap; headKey at this point should always point to // a queue-beginning cap entry (zero-length value) status = cursor.getSearchKey(headKey, result, null); if(status!=OperationStatus.SUCCESS || result.getData().length > 0) { // cap missing throw new DatabaseException("bdb queue cap missing"); } // get next item (real first item of queue) status = cursor.getNext(headKey,result,null); } finally { if(cursor!=null) { cursor.close(); } } return status; } /** * Put the given CrawlURI in at the appropriate place. * 添加URL到数据库 * @param curi * @throws DatabaseException */ public void put(CrawlURI curi, boolean overwriteIfPresent) throws DatabaseException { DatabaseEntry insertKey = (DatabaseEntry)curi.getHolderKey(); if (insertKey == null) { insertKey = calculateInsertKey(curi); curi.setHolderKey(insertKey); } DatabaseEntry value = new DatabaseEntry(); crawlUriBinding.objectToEntry(curi, value); // Output tally on avg. size if level is FINE or greater. if (LOGGER.isLoggable(Level.FINE)) { tallyAverageEntrySize(curi, value); } OperationStatus status; if(overwriteIfPresent) { //添加 status = pendingUrisDB.put(null, insertKey, value); } else { status = pendingUrisDB.putNoOverwrite(null, insertKey, value); } if(status!=OperationStatus.SUCCESS) { LOGGER.severe("failed; "+status+ " "+curi); } }  }
}
BdbWorkQueue:
代表一个链接队列,该队列中所有的链接都具有相同的键值.它实际上是通过调用BdbMultipleWorkQueues的get方法从等处理链接数据库中取得一个链接的.
WorkQueueFrontier:
实现了最核心的三个方法.
BdbFrontier:
继承了WorkQueueFrontier,是Heritrix唯一个具有实际意义的链接工厂.
BdbUriUniqFilter:
实际上是一个过滤器,它用来检查一个要进入等待队列的链接是否已经被抓取过.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号