Channel Coding Theorem 证明
防盗 https://www.cnblogs.com/setdong/p/17948414
对应于教材 Elements of Information Theory 的 8.7 章节.
在证明定理之前, 先复习一些背景知识, 包括 entropy, WLLN, AEP, joint AEP 和 DMC. 第二节为定理的声明和证明.
1. background
1.1 Entropies 熵
来自于书中的第二章
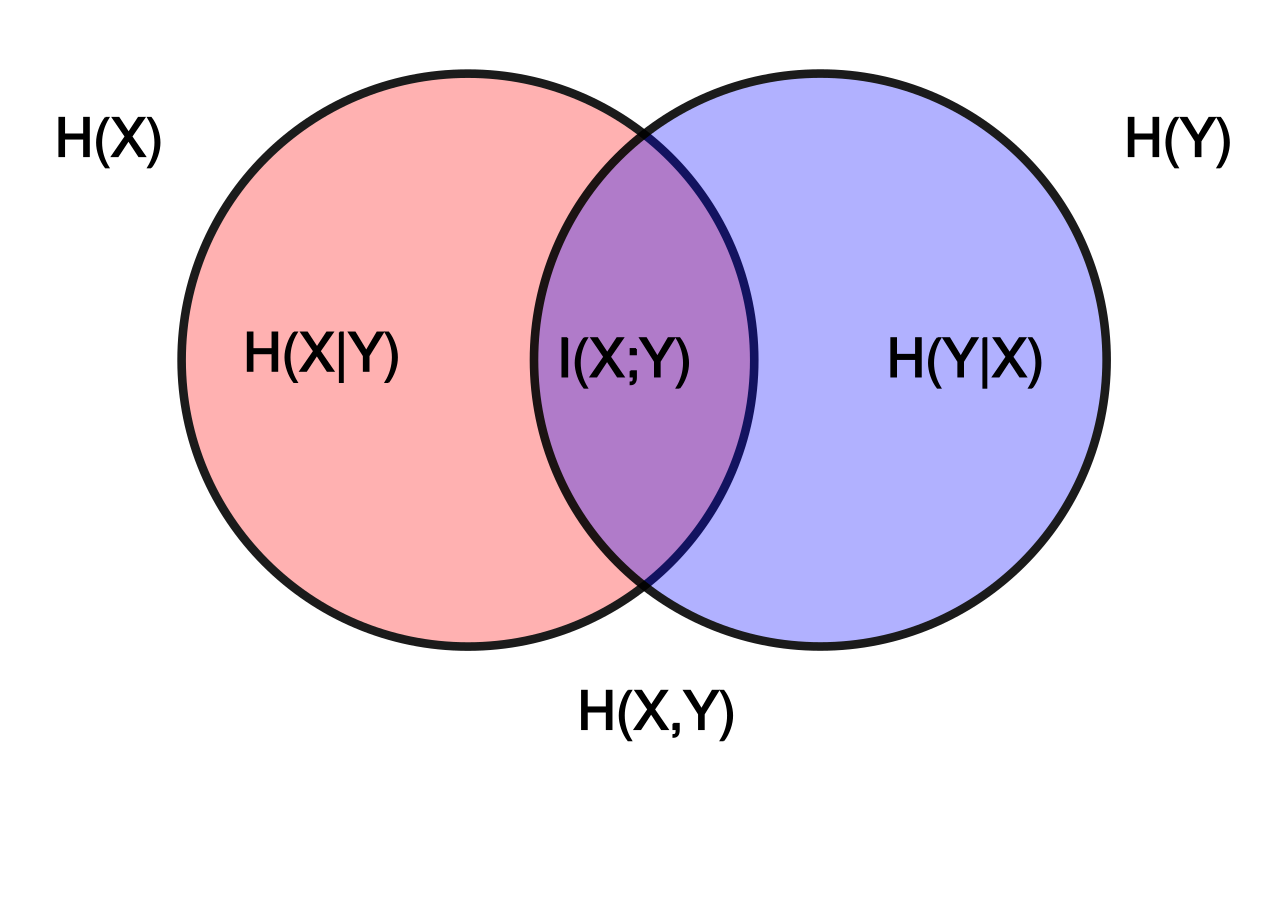
Entropy:
衡量了一个随机变量的不确定程度/随机性 (uncertainty/ randomness)
Joint entropy 联合熵:
同样地, \(H(X,Y)\) 衡量的是 \(X\) 和 \(Y\) 联合的随机性.
Conditional entropy 条件熵:
\(H(Y|X)\) 衡量的是给定 \(X\) 后, \(Y\) 的随机性.
Mutual information 互信息:
是 \(X\) 由于已知 \(Y\) 而减少的“信息量”
1.2 Weak Law of Large Number(WLLN)
\(X_1,...,X_n\) are i.i.d \(\sim p(x)\), then
即样本均值依概率收敛于期望值.
1.3 AEP: Asymptotic Equipartition Property
来自于书中的第3章
Thm. (AEP) If \(X_1,...,X_n\) are i.i.d \(\sim p(x)\), then
Typical set (典型集) 定义:
The typical set \(A_{\epsilon}^{(n)}\) with respect to \(p(x)\) is the set of sequences \((x_1,...,x_n)\in S_X^{(n)}\) with the property
Typical set 有以下性质:
- If \((x_1,...,x_n)\in A_{\epsilon}^{(n)}\), then \(H(X) - \epsilon\leq -\frac{1}{n} p(x_1,...,x_n)\leq H(X)+\epsilon\).
- \(\Pr\{A_{\epsilon}^{(n)}\}>1-\epsilon\) for \(n\) sufficiently large.
- \(|A_{\epsilon}^{(n)}|\leq 2^{n(H(X)+\epsilon)}\).
- \(|A_{\epsilon}^{(n)}|\geq (1-\epsilon)2^{n(H(X)-\epsilon)}\) for \(n\) sufficiently large.
1.4 Joint AEP
来自于书中的8.6章节
Joint typical set 定义:
The set \(A_{\epsilon}^{(n)}\) of jointly typical sequences \(\{(x^n,y^n)\}\) with respect to \(p(x,y)\) is the set of \(n\)-sequences with empirical entropies \(\epsilon\)-close to the true entropies:
where \(p(x^n,y^n)=\prod_{i=1}^{n} p(x_i,y_i)\).
Thm.(Joint AEP) Let \((X^n, Y^n)\) be sequences of length \(n\) drawn i.i.d. \(\sim p(x^n,y^n)=\prod_{i=1}^n p(x_i,y_i)\). Then,
- As \(n\rightarrow \infty\), \(\Pr \{(X^n, Y^n)\in A_\epsilon^{(n)}\}\rightarrow 1\)
- \(|A_\epsilon^{(n)}|\leq 2^{n(H(X,Y)+\epsilon)}\)
\(|A_\epsilon^{(n)}|\geq (1-\epsilon)2^{n(H(X,Y)-\epsilon)}\) for sufficiently large \(n\) - If \((\tilde{X}^n, \tilde{Y}^n)\sim p(x^n)p(y^n)\), then
\(\Pr \{(\tilde{X}^n, \tilde{Y}^n)\in A_\epsilon^{(n)}\}\leq 2^{-n(I(X;Y)-3\epsilon)}\)
\(\Pr \{(\tilde{X}^n, \tilde{Y}^n)\in A_\epsilon^{(n)}\}\leq (1-\epsilon)2^{-n(I(X;Y)+3\epsilon)}\) for sufficiently large $
1.5 Discrete Memoryless Channel (DMC) without feedback
来自于书中的8.5章节

一个消息 \(W\) 首先被编码成长度为 \(n\) 的序列 \(X^n\), \(X^n\) 是信道的输入, 信道是一概率转移矩阵 (probability transition matrix) \(p(y|x)\), 这里的随机性是由于噪声, 信道的输出是 \(Y^n\), \(Y^n\) 随即被解码成 \(\hat{W}\).
- Memoryless 表示 \(p(y_k|x^k, y^{k-1})=p(y_{k}|x_k)\), 即输出的概率分布只依赖于此时刻 (\(k\)) 的输入, 与之前的输入输出条件独立.
- W/O Feedback 表示 \(p(x_k|x^{k-1},y^{k-1})=p(x_k|x^{k-1})\), 即输入与之前的输出独立.
- 因此 channel transition function 可以化简为
接下来是一些重要的定义:
- An \((M,n)\) code for channel \((S_X,p(y|x), S_Y)\) consists of:
An index set \(\{1,2,...,M\}\),
An encoding function \(X^n:\{1,2,...,M\}\rightarrow S_X^n\), yielding codewords \(x^n(1), x^n(2),..., x^n(M)\). The set of codewords is called the codebook,
A decoding function \(g: S_{Y}^n \rightarrow \{1,2,...,M\}\), which is a deterministic function. - The information channel capacity:
- Conditional probability of error:
- The maximal probability of error \(\lambda^{(n)}\) for an \((M,n)\) code:
- The arithmetic average probability of error \(Pe^{(n)}\) for an \((M,n)\) code:
- The rate \(R\) for an \((M,n)\) code:
单位是 bits/ch. use
2. Channel Coding Theorem
来自于书中的8.7章节
For a discrete memoryless channel, all rates below capacity \(C\) are achievable. Specifically, for every rate \(R < C\), there exists a sequence of \((2^{nR}, n)\) codes with maximum probability of error \(\lambda^{(n)} \rightarrow 0\) as \(n\rightarrow \infty\).
Conversely, any sequence of \((2^{nR}, n)\) codes with \(\lambda^{(n)} \rightarrow 0\) must have \(R \leq C\).
针对 DMC, 定理说明了两件事: 1. Achievability: 如果 \(R\) 小于信道容量 \(C\), 那么存在一种编码技术使\(\lambda^{(n)}\)任意小, 也就是说接收端收到的错误达到任意小的数值; 2. Converse: 任何无错编码技术一定满足 \(R \leq C\).
2.1 证明 Achievability:
固定 \(p(x)\), 首先分析根据 \(p(x)\) 随机生成一个 \((M,n)\) code 的概率, 这等价于根据 \(p(x^n)=\prod_{i=1}^n p(x_i)\) 独立生成 \(2^{nR}\) 个 codewords, 这 \(2^{nR}\) 个 codewords即为 codebook \(B\). (编码簿)
如果把这个 codebook 写作一个 \(2^{nR} \times n\) 的矩阵:
每行即为 codewords, 如第一行为 \(x^n(1)\), 是消息 \(1\) 的 codeword, 且 \(p(x^n(1))=\prod_{i=1}^n p(x_i(1))\).
所以, 生成 \(B\) 的概率为
考虑以下事件:
- 根据上述概率公式生成一个随机的 codebook \(B\).
- 向发送端 Tx 和接收端 Rx 揭示 B, 假设 Tx 和 Rx 已知信道 \(p(y|x)\).
- (均匀)随机选择一个消息 \(w\):
- 通过信道传送 \(w\).
- 接收端 Rx 根据 \(p(y^n|x^n(w))=\prod_{i=1}^n p(y_i|x_i(w))\) 接收到长度为 n 的序列 \(Y^n\)
- 如果下列两个条件成立, 则接收端 Rx 输出 \(\hat{w}\):
a) \((x^n(\hat{w}), y^n)\in A_\epsilon^{(n)}\) .
b) 没有其他的 index \(k\) 满足 \((x^n(k), y^n)\in A_\epsilon^{(n)}\) .
如果不存在这样的 \(\hat{w}\) 或者不只有一个这样的 \(\hat{w}\), 那么报错. - 如果 \(\hat{w} \neq w\), 报错.
接下来分析报错的概率 \(\Pr(e)\):

令 \(E_i=\{(X^n(i), Y^n) \in A_\epsilon^{(n)}\}\), 其中 \(Y^n\) 为信道对\(X^n(1)\)的输出, 因为假设了传递的消息 \(w=1\).
根据6(a), 6(b) 和 7的描述可知, 当传递的codeword与接收到的序列不 jointly typical 时 (等价于 \(E_1^C\)), 或一个错误的 codeword与接收到的序列是 jointly typical 时(等价于 \(E_2 \cup E_2 \cup ... \cup E_{2^{nR}}\)), 错误产生. 所以:
根据union bound, 上式满足
根据 joint AEP 的第一条性质, 对于足够大的 n 有 \(\Pr(E_1^C|W=1)\leq \epsilon\).
根据 joint AEP 的最后一条性质, 对于足够大的 n 有 \(\Pr(E_i|W=1) \leq 2^{-n (I(X;Y)-3\epsilon)}\), 带入上式
当 n 足够大且 \(R< I(X;Y)-3\epsilon\) 时, 上式满足
目前已经证明了当\(R< I(X;Y)-3\epsilon\) 时, 我们可以选择合适的 \(n\) 和 \(\epsilon\) 令平均错误率 \(Pe^{(x)}\) 小于等于 \(2\epsilon\). 这里的平均是在所有的 codewords 和所有的 codebook 上的平均, 正如图片中的 sum over B 和 sum over w.
但是此时只得到了平均错误率的上界, 无法得出定理中的结论, 接下来推最大错误率 \(\lambda^{(n)}\) 的上界.
再次考虑以下事件:
- 选择 \(p(x)=p^*(x)\), \(p^*(x)\) 为令 \(I(X;Y)\) 最大的输入分布, 也就是 \(p^*(x)\) 是实现通道容量的那个分布.
所以上面的条件 \(R< I(X;Y) \Rightarrow R<C\) . - 选择一个平均错误率最小的 codebook \(B*\), 所以
- 移除 \(B^{*}\) 中最差的那半 codewords, 将剩余部分记为 \(B^{**}\), 由于平均错误率小于等于 \(2\epsilon\) 且 概率是非负的, 所以\(B^{**}\)的最大错误率一定小于等于\(4\epsilon\), 否则上一条中的不等式将不成立.
Achievability 证明完毕.
其中, 移除一半codewords 令 index set 减少一半, 即
速率 R 只减少了 \(\frac{1}{n}\), 且当 n 很大时, 对 R 几乎无影响.
2.2 证明 Converse:
来自于书中的8.8 - 8.10章节
未完待续

 浙公网安备 33010602011771号
浙公网安备 33010602011771号