【论文笔记】(2015,防御蒸馏)Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks
有关蒸馏 (Distillation)的论文:
- (2006)Model Compression
- (2014)Do Deep Nets Really Need to be Deep?--- 论文笔记
- (2015)Distilling the Knowledge in a Neural Network--- 论文笔记
摘要
本文提出了防御蒸馏(defensive distillation),主要思想为:使用从DNN中提取的知识来降低生成对抗样本时的梯度,如果这个对抗梯度很高,那么扰动很大,DNN的输出不稳定;为了抵抗这种扰动,需要减少输入周围的变化,即使用防御蒸馏来平滑训练得到的模型,提高模型的泛化能力,从而令模型对对抗样本具有高弹性。此外,作者还理论推导+实验证明了防御蒸馏的有效性。
本文是较早的对抗文章,作者十分详细的介绍了神经网络、对抗样本、对抗攻击、对抗训练、蒸馏等基本概念,此笔记不过多重复叙述这些基础知识。
1. Defending DNNs using distillation
A)防御对抗样本
1)在本文中,作者认为具有对抗鲁棒性的模型应该具有以下能力:
- 对训练集内外的数据都应有高准确率;
- 很平滑(smooth),即对给定样本附近(neighborhood)的输入进行相对一致的分类。
这里的neighborhood是根据合适的范数所定义,neighborhood范围越大,模型的鲁棒性越高。
2)防御对抗扰动的设计要求:
- 对网络结构影响小
- 保持网络的准确率
- 保持网络的计算速度
- 防御与训练数据相对接近的对抗样本(很远的样本与安全性无关)
B)蒸馏用作防御
防御蒸馏与传统蒸馏的区别在于:使用相同的模型结构来训练原来的网络和蒸馏网络。防御蒸馏的概述如图1所示。
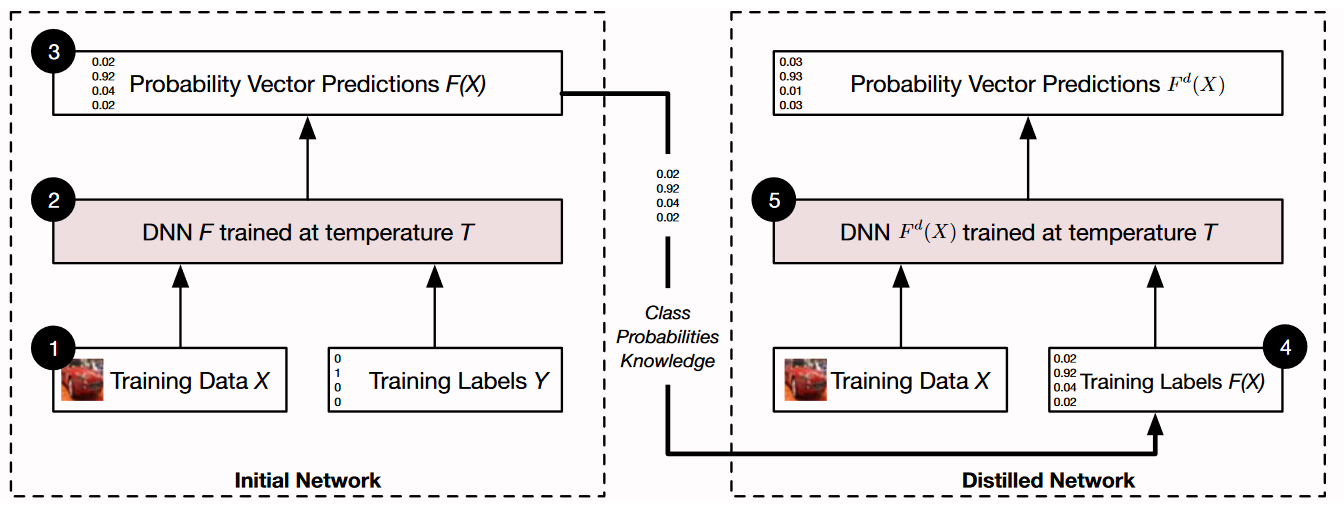
图1. 防御蒸馏的概述:首先在数据 \(X\) 上使用硬标签训练一个初始网络 \(F\),softmax 的 temperature 为 \(T\)。然后使用概率向量 \(F(X)\)作为软标签,以在相同数据 \(X\) 和相同的 \(T\) 训练蒸馏网络 \(F^d\)。
2. Analysis of defensive distillation
分析分为三个方面研究 (1) 网络训练(2) 模型敏感度(sensitivity)(3) 网络的泛化能力
A)网络训练
1)考虑模型 \(F\),数据集为 \(\mathcal{X}\),给定一组带正确标签的样本 \(\{(X,Y(X))|X\in \mathcal{X}\}\),即\(Y(X)\)为\(X\)的正确标签向量(硬标签),训练目标为(最小化负对数似然):
\(\theta_F\) 为模型的参数集合,\(Y_i\) 是 \(Y\) 的第 \(i\) 个元素,\(F_i(X)\) 是 \(F(X)\) 的第 \(i\) 个元素,即表示 \(X\) 是第 \(i\) 个类别的概率。优化的目标是调整模型参数 \(\theta_F\)。
由于\(Y(X)\)为\(X\)的正确标签向量,即one-hot向量,只有正确类别的元素才是1,其余都为0,所以公式(1)可以简化为:
其中 \(t(X)\) 是向量 \(Y(X)\) 中唯一等于 1 的元素的索引。
2)引入对抗蒸馏后,蒸馏模型记为 \(F^d\),训练的数据集仍为 \(\mathcal{X}\),但样本 \(X \in \mathcal{X}\) 的标签变为 \(F(X)\)(软标签),训练目标变为:
同样的,\(F_i^d\) 是 \(F^d\) 的第 \(i\) 个元素。 对于一个包含了两个或多个类别特征的样本,网络有时会十分自信的预测出一个类别,作者认为,上述的蒸馏训练能避免这种情况,从而提高网络的泛化能力。
训练目标实际就是令 \(F^d = F\),也就是最小化交叉熵。
B)模型敏感度
模型对输入变化的敏感度由其Jacobian矩阵计算,在 temperature\(=T\) 时,模型 \(F\) 的 Jacobian矩阵的第 \((i,j)\) 元素为:
其中 \(z_0,...,z_{N-1}\) 是logits 层的输出。公式(4)说明了,当 \(z_0,...,z_{N-1}\) 不变时,增加 \(T\) 的值会降低Jacobian矩阵内所有元素的绝对值,从而降低了模型对其输入的微小变化的敏感度。
作者认为,使用较高的 \(T\) 进行训练,可以将这种敏感度信息编码在模型参数中,因此在测试时,令\(T=1\),仍可以保持其敏感性。
C)泛化能力
Shalev-Schwartz等人证明了 learnability 和 stability 之间的联系:考虑一个学习问题 \((Z=X\times T, \mathcal{H},l)\),其中 \(X\) 是输入空间,\(Y\) 是输出空间,\(\mathcal{H}\) 是假设空间,\(l\) 是将 \((w,z) \in \mathcal{H}\times Z\) 映射为一个正实数的损失函数。对于给定的一组训练集 \(S=\{z_i: i\in[n]\}\),定义一个经验损失(empirical loss) \(L_S(w)=\frac{1}{n}\sum_{i\in[n]} l(w,z_i)\),将最小经验风险记为 \(L_S^* = \min_{w\in \mathcal{H}}L_S(w)\)。现在给出以下两个定义和一个定理:
定义1 Asymptotic Empirical Risk Minimizer:a learning rule \(A\) is an asymptotic empirical risk minimizer, if there is a rate function \(\varepsilon (n)\) (means a function that non-increasingly vanishes to 0 as n grows) such that for every training set \(S\) of size \(n\),
定义2 Stability:we say that a learning rule \(A\) is \(\varepsilon (n)\) stable if for every two training sets \(S\), \(S′\) that only differ in one training item, and for every \(z \in Z\),
其中 \(h=A(S)\) 是 \(A\) 在训练集 \(S\) 上的输出,\(l(A(S),z)=l(h,z)\) 是损失函数。
定理1 If there is a learning rule \(A\) that is both an asymptotic empirical risk minimizer and stable, then \(A\) generalizes, which means that the generalization error \(L_D(A(S))\) converges to \(L^∗_D =\min_{ h\in \mathcal{H}} L_D(h)\) with some rate \(\varepsilon (n)\) independent of any data generating distribution \(D\).
根据这个定理可以知道,通过适当的设置 \(T\),对于任何数据集 \(S\) 和 \(S'\),新生成的训练集 \((X,F^S(X))\) 和 \((X,F^{S'}(X))\) 满足很强的稳定性条件。反过来就是,对于任意的 \(X\in \mathcal{X}\),\(F^S(X)\) 和 \(F^{S'}(X)\) 在统计上是接近的。可以看出,防御蒸馏训练满足上述定义的稳定性条件。
此外,从防御蒸馏的目标函数可以推出,该方法将经验风险降至最低。将这两个结论与定理1结合可以得出:本文的蒸馏模型具有很好地泛化能力。
3. Evaluation
对防御蒸馏进行试验评估:
数据集:使用 MNIST 和 CIFAR10,每个数据集对应一个网络结构,即两个DNN,前者网络的准确率为 99.51%,后者的诶80.95%;
攻击策略:JSMA;
Temperature:\(T=20\),蒸馏之后,MNIST的准确率为99.05%,CIFAR为81.39%,测试时\(T=1\),也就是不使用temperature。
主要评估了以下方面:
- 防御蒸馏是否在保持分类准确的同时,提升了网络对对抗样本的防御力?
蒸馏将第一个网络的攻击成功率从 95.89% 降低到 0.45%,将第二个网络从 87.89% 降低到 5.11%。自然样本上的准确率只比原本的网络低1.37%,可忽略不计。 - 防御蒸馏是否能降低 DNN 对输入的敏感性?
降低了,实验表明,在高\(T\)时进行蒸馏可以使对抗梯度的幅度降低\(10^{30}\)倍。 - 防御蒸馏是否使DNN更鲁棒?
防御蒸馏提高了第一个网络的鲁棒性790%,第二个网络的鲁棒性556%(这里的鲁棒性指的是为生成对抗而扰动的输入特征的平均最小百分比)。
其他的实验包括temperature取值对攻击成功率的影响、对模型准确率的影响、对对抗梯度的影响、对模型鲁棒性的影响等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号