
分布式缓存--系列1 -- Hash环/一致性Hash原理
当前,Memcached、Redis这类分布式kv缓存已经非常普遍。从本篇开始,本系列将分析分布式缓存相关的原理、使用策略和最佳实践。
我们知道Memcached的分布式其实是一种“伪分布式”,也就是它的服务器结点之间其实是相互无关联的,之间没有网络拓扑关系,由客户端来决定一个key是存放到哪台机器。
具体来讲,假设我有多台memcached服务器,编号分别为m0,m1,m2,…。对于一个key,由客户端来决定存放到哪台机器,那最简单的hash公式就是 key % N,其中N是机器的总数。
但这有个问题,一旦机器数变少,或者增加机器,N发生变化,那之前存放的数据就全部无效了。因为你按照新的N值取模计算出的机器编号,和当时按旧的N值取模算出的机器编号肯定是不等的,也就意味着绝大部分缓存会失效。
这个问题的解决办法就是用1种特别的Hash函数,尽可能使得,增加机器/减少机器时,缓存失效的数目降到最低,这就是Hash环,或者叫一致性Hash。
有兴趣朋友可以关注公众号“架构之道与术”, 获取最新文章。
或扫描如下二维码:

Hash环
上面说的Hash函数,只经过了1次hash,即把key hash到对应的机器编号。
而Hash环有2次Hash:
(1)把所有机器编号hash到这个环上
(2)把key也hash到这个环上。然后在这个环上进行匹配,看这个key和哪台机器匹配。
具体来讲,如下:
假定有这样一个Hash函数,其值空间为(0到2的32次方-1) ,也就是说,其hash值是个32位无整型数字 ,这些数字组成一个环。
然后,先对机器进行hash(比如根据机器的ip),算出每台机器在这个环上的位置; 再对key进行hash,算出该key在环上的位置,然后从这个位置往前走,遇到的第一台机器就是该key对应的机器,就把该(key, value) 存储到该机器上。
如下图所示:
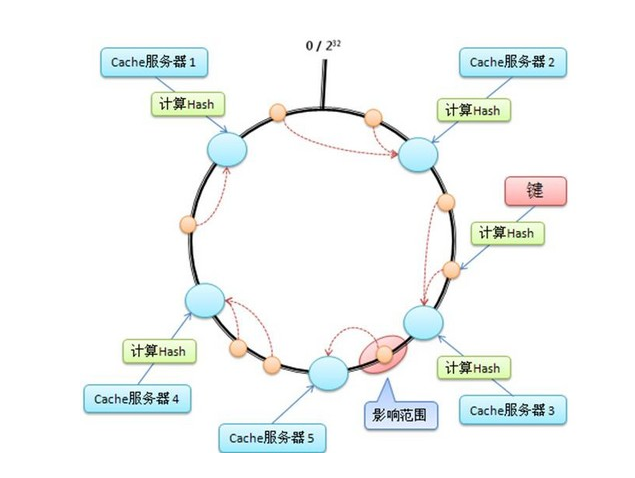
首先计算出每台Cache服务器在环上的位置(图中的大圆圈);然后每来一个(key, value),计算出在环上的位置(图中的小圆圈),然后顺时针走,遇到的第1个机器,就是其要存储的机器。
这里的关键点是:当你增加/减少机器时,其他机器在环上的位置并不会发生改变。这样只有增加的那台机器、或者减少的那台机器附近的数据会失效,其他机器上的数据都还是有效的。
数据倾斜问题
当你机器不多的时候,很可能出现几台机器在环上面贴的很近,不是在环上均匀分布。这将会导致大部分数据,都会集中在某1台机器上。
为了解决这个问题,可以引入“虚拟机器”的概念,也就是说:1台机器,我在环上面计算出多个位置。怎么弄呢? 假设用机器的ip来hash,我可以在ip后面加上几个编号, ip_1, ip_2, ip_3, .. 把1台物理机器生个多个虚拟机器的编号。
数据首先映射到“虚拟机器上”,再从“虚拟机器”映射到物理机器上。因为虚拟机器可以很多,在环上面均匀分布,从而保证数据均匀分布到物理机器上面。
ZK的引入
上面我们提到了服务器的机器增加、减少,问题是客户端怎么知道呢?
一种笨办法就是手动的,当服务器机器增加、减少时候,重新配置客户端,重启客户端。
另外一种,就是引入ZK,服务器的节点列表注册到ZK上面,客户端监听ZK。发现结点数发生变化,自动更新自己的配置。
当然,不用ZK,用一个其他的中心结点,只要能实现这种更改的通知,也是可以的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号