Python日常实践(1)——SQL Prompt的Snippets批量整理
引言
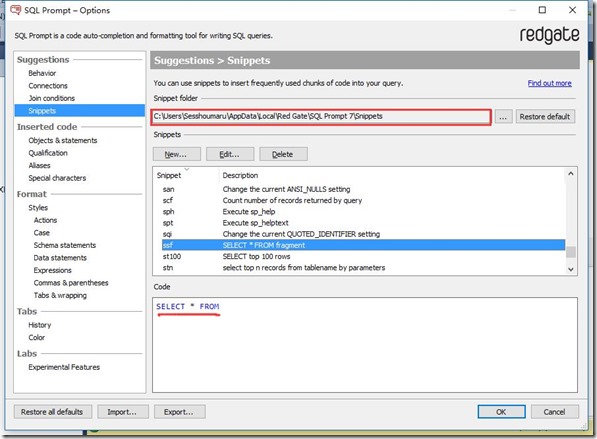
个人平时在写sql脚本的时候会使用到SQL Prompt这款插件,除了强大的智能提示和格式化sql语句功能,我还喜欢使用Snippets代码段功能。比如我们可以在查下分析器输入ssf后按Tab键,SQL Prompt就可以帮我们快速的输入SELECT * FROM 。
但是个人不习惯看大写的sql代码,所以就想捣鼓着将代码段输出的代码变成小写。打开代码段管理界面,发现管理工具提供了编辑代码段的功能,但是如果要一个个的编辑,自行转换成小写,再保存,那显然不是咱的风格。可以看到SQL Prompt存放代码段的路径:
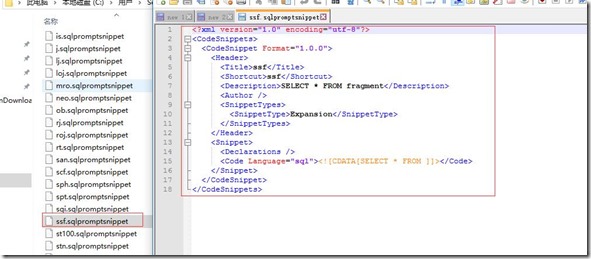
找到路径中的文件打开可以看到,代码段文件是一个扩展名为sqlpromptsnippet的xml文件。
所以想着使用python来批量的将代码段文件中的代码转换成小写。
一. xml操作——找到Code节点并获取代码段的sql语句
1. xml格式文件节点类型详细介绍可以参考 W3School教程
2. python中读写xml文件可以使用mxl.dom.minidom模块,查找Code节点代码如下:
import xml.dom.minidom snippet = xml.dom.minidom.parse('ssf.sqlpromptsnippet') root = snippet.documentElement print(root.nodeType,root.nodeName,root.nodeValue) code = snippet.getElementsByTagName('Code')[0] print(code.nodeType,code.nodeName,code.nodeValue)snippet = xml.dom.minidom.parse('ssf.sqlpromptsnippet') :表示打开当前路径中名为'ssf.sqlpromptsnippet'的xml文件,并把xml文件对象赋值给snippet对象。
root = snippet.documentElement :表示获取snippet对象的文档元素(根节点),并把获得的对象给root。
code = snippet.getElementsByTagName('Code')[0] :表示查找root根节点下面所有名为Code的子元素,并将第一个子元素赋值给code对象。
执行结果:
1 CodeSnippets None 1 Code None因为CodeSnippets和Code节点都不是文本节点,所有其nodeValue属性为None。Code节点为1个 CDATASection节点,其有以下属性:
所以找到Code节点并获取代码段的sql语句的正确语句如下:
import xml.dom.minidom snippet = xml.dom.minidom.parse('ssf.sqlpromptsnippet') root = snippet.documentElement #print(root.nodeType,root.nodeName,root.nodeValue) code = snippet.getElementsByTagName('Code')[0] #print(code.nodeType,code.nodeName,code.nodeValue) statement = code.firstChild.data # code的第1个(也是唯一的)子元素才是CDATASection节点 print (statement)执行结果:
SELECT * FROM
二. sql代码转换操作——大写转小写
1. sql语句大写转小写,可以直接使用str类的lower函数即可:
statementlower = statement.lower() print (statementlower)执行结果:
select * from2. SQL Prompt中有部分代码段是含有占位符的,占位符的格式为”$CURSOR$”,而且其是区分大小写的,所以占位符不能转换成小写。所以需要先将代码段中个sql语句中的占位符全部找出来,并存储起来,在sql语句转换成小写之后替换回去。
因为占位符都是以“$”开头,也以“$”结尾,所以我们可以很方便的使用正则表达式来查找sql语句中的所有占位符。查找出来之后先将占位符和其小写形式使用dict存储起来。
import xml.dom.minidom import re snippet = xml.dom.minidom.parse('ct.sqlpromptsnippet') root = snippet.documentElement #print(root.nodeType,root.nodeName,root.nodeValue) code = snippet.getElementsByTagName('Code')[0] #print(code.nodeType,code.nodeName,code.nodeValue) statement = code.firstChild.data # code的第1个(也是唯一的)子元素才是CDATASection节点print (statement) print (statement) # 输出原语句 # 正则查找所有的占位符 keylist = re.findall("\$\w+\$",statement) # 将占位符和其小写形式存储成字典 placeholds = dict() for key in keylist: placeholds[key] = key.lower() print(placeholds) # 先将语句转换成小写 statementlower = statement.lower() # 循环占位符字典,替换回占位符 for k,v in placeholds.items(): statementlower = statementlower.replace(v,k) print (statementlower)执行结果:
CREATE TABLE $table_name$ ( $CURSOR$ ) {'$table_name$': '$table_name$', '$CURSOR$': '$cursor$'} create table $table_name$ ( $CURSOR$ )
三. xml操作——将转换代码写回xml文件
xml写操作使用的是writexml文件,具体代码如下:
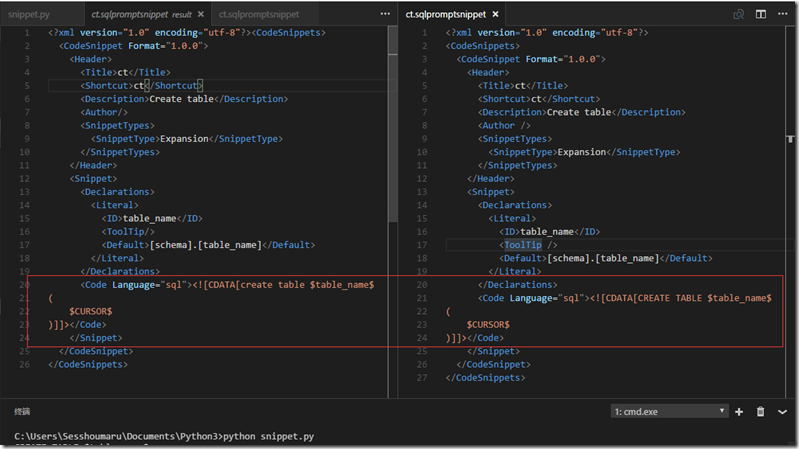
import xml.dom.minidom import re snippet = xml.dom.minidom.parse('ct.sqlpromptsnippet') root = snippet.documentElement #print(root.nodeType,root.nodeName,root.nodeValue) code = snippet.getElementsByTagName('Code')[0] #print(code.nodeType,code.nodeName,code.nodeValue) statement = code.firstChild.data # code的第1个(也是唯一的)子元素才是CDATASection节点print (statement) keylist = re.findall("\$\w+\$",statement) placeholds = dict() for key in keylist: placeholds[key] = key.lower() statementlower = statement.lower() for k,v in placeholds.items(): statementlower = statementlower.replace(v,k) #更新XML对象 code.firstChild.data = statementlower # 打开文件对象,再写入 f = open('result\ct.sqlpromptsnippet', 'w',encoding = 'utf-8') snippet.writexml(f, addindent='', newl='',encoding='utf-8') f.close()执行结果生成文件对比:
四. 批量操作——循环代码段文件批量处理
1. 循环目录下的文件,使用的是os模块的listdir方法。
>>> import os >>> os.listdir() ['DLLs', 'Doc', 'include', 'Lib', 'libs', 'LICENSE.txt', 'NEWS.txt', 'python.exe', 'python3.dll', 'python35.dll', 'pythonw.exe', 'README.txt', 'Scripts', 'tcl', 'Tools', 'vcruntime140.dll']2. 先将单个转换封装成方法sqllower,再循环读取目录下的代码段文件即可完成批量处理,完整代码如下:
import xml.dom.minidom import re import os def sqllower(name): snippet = xml.dom.minidom.parse(name) root = snippet.documentElement #print(root.nodeType,root.nodeName,root.nodeValue) code = snippet.getElementsByTagName('Code')[0] #print(code.nodeType,code.nodeName,code.nodeValue) statement = code.firstChild.data # code的第1个(也是唯一的)子元素才是CDATASection节点print (statement) #print (statement) keylist = re.findall("\$\w+\$",statement) placeholds = dict() for key in keylist: placeholds[key] = key.lower() #print(placeholds) statementlower = statement.lower() for k,v in placeholds.items(): statementlower = statementlower.replace(v,k) #print (statementlower) #更新XML对象 code.firstChild.data = statementlower f = open('result\\' + name, 'w',encoding = 'utf-8') snippet.writexml(f, addindent='', newl='',encoding='utf-8') f.close() # 循环进行转换 for f in os.listdir(): if f.endswith('.sqlpromptsnippet'): print('正在转换'+ f) sqllower(f) print ('所有转换完成。')
五. 总结
本文从日常使用中提取出sql代码段大小写转换的需求,将其使用Python实现。使用到了如下的模块:
1. xml.dom.minidom模块,用来读写xml文件。
2. re模块,使用了正则表达式,查询所有的占位符。
3. os模块,使用listdir方法来循环目录中个文件。