
MSD_radix_sort
一、这次是在上一次尝试基础上进行的,预期是达到上次性能的9倍。
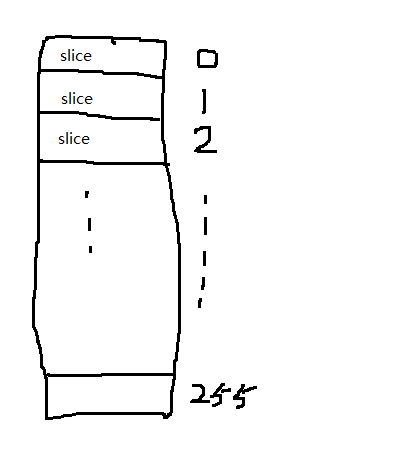
MSD的基本手法就是不断切片。
每一步都是把整体数据切割成256片,如上图所示,实际情况切片未必均匀,有的slice内可能一个元素也没有。
接下来对于每个切片怎么办呢?
答案是继续切,对于特殊数据来讲,切片过程可以很快结束,这样就可以实现比LSD更快的速度。
这里面最困难的地方就是如何存储每个slice的头和尾。
如果采用下述方式,应该是行不通的。
这个方式需要做数组元素插入,还要跟踪中间数据,因此没具体考虑。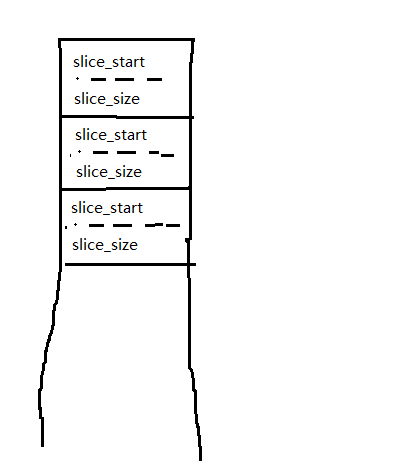
我真正采用的是下表:
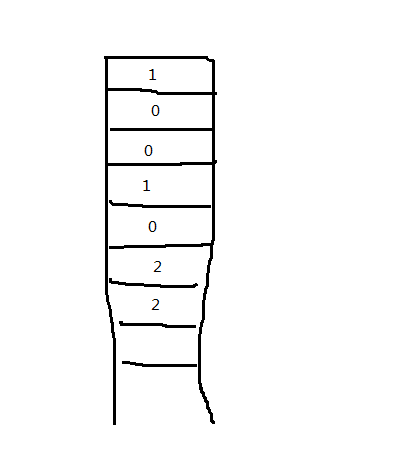
表中第一项表示第一个元素开启一个类别,紧跟的0表示此元素和上面的1是同一类。
至于2表明在切片过程中是一个孤立的元素,后续就没必要再切片了。
这个方式可以大大简化编码。
二、伪代码。
for each slice if slice-tag == 2 continue; if slice-tag == 1 slice it; update bookkeeping
int main(){ HANDLE heap = NULL; Bucket bucket[BUCKETSLOTCOUNT]; PageList * pageListPool; int plpAvailable = 0; int * pages = NULL; int * pagesAvailable = NULL; int * objIdx; unsigned short * s; __int8 * classifier = NULL; time_t timeBegin; time_t timeEnd; heap = HeapCreate(HEAP_NO_SERIALIZE|HEAP_GENERATE_EXCEPTIONS, 1024*1024, 0); if (heap != NULL){ pages = (int * )HeapAlloc(heap, 0, (TFSI/PAGEGRANULAR + BUCKETSLOTCOUNT + 8) * PAGEAMOUNT); pageListPool = (PageList *)HeapAlloc(heap, 0, (TFSI/PAGEGRANULAR + 8) * sizeof(PageList)); s = (unsigned short *)HeapAlloc(heap, 0, TFSI*sizeof(unsigned short)); objIdx = (int *)HeapAlloc(heap, 0, TFSI * sizeof(int)); classifier = (__int8 *)HeapAlloc(heap, 0, (TFSI+8)*sizeof(__int8)); } MakeSure(pages != NULL && pageListPool != NULL && objIdx != NULL && classifier != NULL); for(int i=0; i<TFSI; i++) objIdx[i]=i; timeBegin = clock(); for (int i=0; i<TFSI; i++) s[i] = rand(); timeEnd = clock(); printf("\n%f(s) consumed in generating numbers", (double)(timeEnd-timeBegin)/CLOCKS_PER_SEC); SecureZeroMemory(classifier, TFSI*sizeof(__int8)); classifier[0] = 1; classifier[TFSI] = 1; timeBegin = clock(); bool no_need_further_processing = false; for (int t=sizeof(short)-1; t>=0; t--){ int bucketIdx; int slice_pointer = 0; int slice_base = 0; int flagCounter = 0; if (no_need_further_processing) break; //classifier: 1 new catagory //classifier: 2 completed catagory process while (slice_pointer < TFSI){ if (classifier[slice_pointer] == 2){ slice_base = slice_pointer; classifier[slice_base] = 0; while (classifier[slice_pointer] == 0){ slice_pointer++; flagCounter++; } classifier[slice_base] = 2; if (flagCounter == TFSI) no_need_further_processing = true; continue; } if (classifier[slice_pointer] == 1){ FillMemory(pages, (TFSI/PAGEGRANULAR + BUCKETSLOTCOUNT + 8) * PAGEAMOUNT, 0xff); SecureZeroMemory(pageListPool, (TFSI/PAGEGRANULAR + 8) * sizeof(PageList)); pagesAvailable = pages; plpAvailable = 0; for(int i=0; i<256; i++){ bucket[i].currentPagePtr = pagesAvailable; bucket[i].offset = 0; bucket[i].pl.PagePtr = pagesAvailable; bucket[i].pl.next = NULL; pagesAvailable += PAGEGRANULAR; bucket[i].currentPageListItem = &(bucket[i].pl); } slice_base = slice_pointer; classifier[slice_base] = 0; while (classifier[slice_pointer] == 0){ //for each slice element, push_back to pages; unsigned char * cell = (unsigned char *)&s[objIdx[slice_pointer]]; bucketIdx = cell[t]; //save(bucketIdx, objIdx[i]); bucket[bucketIdx].currentPagePtr[ bucket[bucketIdx].offset ] = objIdx[slice_pointer]; bucket[bucketIdx].offset++; if (bucket[bucketIdx].offset == PAGEGRANULAR){ bucket[bucketIdx].currentPageListItem->next = &pageListPool[plpAvailable]; plpAvailable++; bucket[bucketIdx].currentPageListItem->next->PagePtr = pagesAvailable; bucket[bucketIdx].currentPageListItem->next->next = NULL; bucket[bucketIdx].currentPagePtr = pagesAvailable; bucket[bucketIdx].offset = 0; pagesAvailable += PAGEGRANULAR; bucket[bucketIdx].currentPageListItem = bucket[bucketIdx].currentPageListItem->next; } slice_pointer++; } classifier[slice_base] = 1; //update classifier; //update objIdx index int start = slice_base; for (int i=0; i<256; i++){ PageList * p; p = &(bucket[i].pl); //classifier: 1 new catagory //classifier: 2 complete catagory process classifier[start] = 1; int counters = 0; while (p){ for (int t=0; t<PAGEGRANULAR; t++){ int idx = p->PagePtr[t]; if (idx != TERMINATOR){ objIdx[start] = idx; start++; counters++; } if (idx == TERMINATOR) break; } p = p->next; } if (counters == 1) classifier[start-1] = 2; } //update objIdx index } //if (classifier[slice_pointer] == 1) } //while (slice_pointer < TFSI) } //for (int t=sizeof(short)-1; t>=0; t--) timeEnd = clock(); printf("\n%f(s) consumed in generating results", (double)(timeEnd-timeBegin)/CLOCKS_PER_SEC); //for(int i=0; i<TFSI; i++) printf("%d\n", s[objIdx[i]]); HeapFree(heap, 0, pages); HeapFree(heap, 0, pageListPool); HeapFree(heap, 0, s); HeapFree(heap, 0, objIdx); HeapFree(heap, 0, classifier); HeapDestroy(heap); return 0; }
三、测试
1024*1024*100 个短整型。
时间 5.438s
看到这里就知道杯具了,比LSD还慢。
如果应用到二维表,会更惨不忍睹。试了下果然如此。
四、讨论
如果哪位有更好的方法,欢迎讨论。
或者,基数排序只是一个花瓶?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号