Serverless 实战:如何结合 NLP 实现文本摘要和关键词提取?
对文本进行自动摘要的提取和关键词的提取,属于自然语言处理的范畴。提取摘要的一个好处是可以让阅读者通过最少的信息判断出这个文章对自己是否有意义或者价值,是否需要进行更加详细的阅读;而提取关键词的好处是可以让文章与文章之间产生关联,同时也可以让读者通过关键词快速定位到和该关键词相关的文章内容。
文本摘要和关键词提取都可以和传统的 CMS 进行结合,通过对文章 / 新闻等发布功能进行改造,同步提取关键词和摘要,放到 HTML 页面中作为 Description 和 Keyworks。这样做在一定程度上有利于搜索引擎收录,属于 SEO 优化的范畴。
关键词提取
关键词提取的方法很多,但是最常见的应该就是tf-idf了。
通过jieba实现基于tf-idf关键词提取的方法:
jieba.analyse.extract_tags(text, topK=5, withWeight=False, allowPOS=('n', 'vn', 'v'))
文本摘要
文本摘要的方法也有很多,如果从广义上来划分,包括提取式和生成式。其中提取式就是在文章中通过TextRank等算法,找出关键句然后进行拼装,形成摘要,这种方法相对来说比较简单,但是很难提取出真实的语义等;另一种方法是生成式,通过深度学习等方法,对文本语义进行提取再生成摘要。
如果简单理解,提取式方式生成的摘要,所有句子来自原文,而生成式方法则是独立生成的。
为了简化难度,本文将采用提取式来实现文本摘要功能,通过 SnowNLP 第三方库,实现基于TextRank的文本摘要功能。我们以《海底两万里》部分内容作为原文,进行摘要生成:
原文:
这些事件发生时,我刚从美国内布拉斯加州的贫瘠地区做完一项科考工作回来。我当时是巴黎自然史博物馆的客座教授,法国政府派我参加这次考察活动。我在内布拉斯加州度过了半年时间,收集了许多珍贵资料,满载而归,3 月底抵达纽约。我决定 5 月初动身回法国。于是,我就抓紧这段候船逗留时间,把收集到的矿物和动植物标本进行分类整理,可就在这时,斯科舍号出事了。
我对当时的街谈巷议自然了如指掌,再说了,我怎能听而不闻、无动于衷呢?我把美国和欧洲的各种报刊读了又读,但未能深入了解真相。神秘莫测,百思不得其解。我左思右想,摇摆于两个极端之间,始终形不成一种见解。其中肯定有名堂,这是不容置疑的,如果有人表示怀疑,就请他们去摸一摸斯科舍号的伤口好了。
我到纽约时,这个问题正炒得沸反盈天。某些不学无术之徒提出设想,有说是浮动的小岛,也有说是不可捉摸的暗礁,不过,这些个假设通通都被推翻了。很显然,除非这暗礁腹部装有机器,不然的话,它怎能如此快速地转移呢?
同样的道理,说它是一块浮动的船体或是一堆大船残片,这种假设也不能成立,理由仍然是移动速度太快。
那么,问题只能有两种解释,人们各持己见,自然就分成观点截然不同的两派:一派说这是一个力大无比的怪物,另一派说这是一艘动力极强的“潜水船”。
哦,最后那种假设固然可以接受,但到欧美各国调查之后,也就难以自圆其说了。有哪个普通人会拥有如此强大动力的机械?这是不可能的。他在何地何时叫何人制造了这么个庞然大物,而且如何能在建造中做到风声不走漏呢?
看来,只有政府才有可能拥有这种破坏性的机器,在这个灾难深重的时代,人们千方百计要增强战争武器威力,那就有这种可能,一个国家瞒着其他国家在试制这类骇人听闻的武器。继夏斯勃步枪之后有水雷,水雷之后有水下撞锤,然后魔道攀升反应,事态愈演愈烈。至少,我是这样想的。
通过 SnowNLP 提供的算法:
from snownlp import SnowNLP
text = " 上面的原文内容,此处省略 "
s = SnowNLP(text)
print("。".join(s.summary(5)))
输出结果:
自然就分成观点截然不同的两派:一派说这是一个力大无比的怪物。这种假设也不能成立。我到纽约时。说它是一块浮动的船体或是一堆大船残片。另一派说这是一艘动力极强的“潜水船”
初步来看,效果并不是很好,接下来我们自己计算句子权重,实现一个简单的摘要功能,这个就需要jieba:
import re
import jieba.analyse
import jieba.posseg
class TextSummary:
def __init__(self, text):
self.text = text
def splitSentence(self):
sectionNum = 0
self.sentences = []
for eveSection in self.text.split("\n"):
if eveSection:
sentenceNum = 0
for eveSentence in re.split("!|。|?", eveSection):
if eveSentence:
mark = []
if sectionNum == 0:
mark.append("FIRSTSECTION")
if sentenceNum == 0:
mark.append("FIRSTSENTENCE")
self.sentences.append({
"text": eveSentence,
"pos": {
"x": sectionNum,
"y": sentenceNum,
"mark": mark
}
})
sentenceNum = sentenceNum + 1
sectionNum = sectionNum + 1
self.sentences[-1]["pos"]["mark"].append("LASTSENTENCE")
for i in range(0, len(self.sentences)):
if self.sentences[i]["pos"]["x"] == self.sentences[-1]["pos"]["x"]:
self.sentences[i]["pos"]["mark"].append("LASTSECTION")
def getKeywords(self):
self.keywords = jieba.analyse.extract_tags(self.text, topK=20, withWeight=False, allowPOS=('n', 'vn', 'v'))
def sentenceWeight(self):
# 计算句子的位置权重
for sentence in self.sentences:
mark = sentence["pos"]["mark"]
weightPos = 0
if "FIRSTSECTION" in mark:
weightPos = weightPos + 2
if "FIRSTSENTENCE" in mark:
weightPos = weightPos + 2
if "LASTSENTENCE" in mark:
weightPos = weightPos + 1
if "LASTSECTION" in mark:
weightPos = weightPos + 1
sentence["weightPos"] = weightPos
# 计算句子的线索词权重
index = [" 总之 ", " 总而言之 "]
for sentence in self.sentences:
sentence["weightCueWords"] = 0
sentence["weightKeywords"] = 0
for i in index:
for sentence in self.sentences:
if sentence["text"].find(i) >= 0:
sentence["weightCueWords"] = 1
for keyword in self.keywords:
for sentence in self.sentences:
if sentence["text"].find(keyword) >= 0:
sentence["weightKeywords"] = sentence["weightKeywords"] + 1
for sentence in self.sentences:
sentence["weight"] = sentence["weightPos"] + 2 * sentence["weightCueWords"] + sentence["weightKeywords"]
def getSummary(self, ratio=0.1):
self.keywords = list()
self.sentences = list()
self.summary = list()
# 调用方法,分别计算关键词、分句,计算权重
self.getKeywords()
self.splitSentence()
self.sentenceWeight()
# 对句子的权重值进行排序
self.sentences = sorted(self.sentences, key=lambda k: k['weight'], reverse=True)
# 根据排序结果,取排名占前 ratio% 的句子作为摘要
for i in range(len(self.sentences)):
if i < ratio * len(self.sentences):
sentence = self.sentences[i]
self.summary.append(sentence["text"])
return self.summary
这段代码主要是通过tf-idf实现关键词提取,然后通过关键词提取对句子尽心权重赋予,最后获得到整体的结果,运行:
testSummary = TextSummary(text)
print("。".join(testSummary.getSummary()))
可以得到结果:
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/yb/wvy_7wm91mzd7cjg4444gvdjsglgs8/T/jieba.cache
Loading model cost 0.721 seconds.
Prefix dict has been built successfully.
看来,只有政府才有可能拥有这种破坏性的机器,在这个灾难深重的时代,人们千方百计要增强战争武器威力,那就有这种可能,一个国家瞒着其他国家在试制这类骇人听闻的武器。于是,我就抓紧这段候船逗留时间,把收集到的矿物和动植物标本进行分类整理,可就在这时,斯科舍号出事了。同样的道理,说它是一块浮动的船体或是一堆大船残片,这种假设也不能成立,理由仍然是移动速度太快
我们可以看到,整体效果要比刚才的好一些。
发布 API
通过 Serverless 架构,将上面代码进行整理,并发布。
代码整理结果:
import re, json
import jieba.analyse
import jieba.posseg
class NLPAttr:
def __init__(self, text):
self.text = text
def splitSentence(self):
sectionNum = 0
self.sentences = []
for eveSection in self.text.split("\n"):
if eveSection:
sentenceNum = 0
for eveSentence in re.split("!|。|?", eveSection):
if eveSentence:
mark = []
if sectionNum == 0:
mark.append("FIRSTSECTION")
if sentenceNum == 0:
mark.append("FIRSTSENTENCE")
self.sentences.append({
"text": eveSentence,
"pos": {
"x": sectionNum,
"y": sentenceNum,
"mark": mark
}
})
sentenceNum = sentenceNum + 1
sectionNum = sectionNum + 1
self.sentences[-1]["pos"]["mark"].append("LASTSENTENCE")
for i in range(0, len(self.sentences)):
if self.sentences[i]["pos"]["x"] == self.sentences[-1]["pos"]["x"]:
self.sentences[i]["pos"]["mark"].append("LASTSECTION")
def getKeywords(self):
self.keywords = jieba.analyse.extract_tags(self.text, topK=20, withWeight=False, allowPOS=('n', 'vn', 'v'))
return self.keywords
def sentenceWeight(self):
# 计算句子的位置权重
for sentence in self.sentences:
mark = sentence["pos"]["mark"]
weightPos = 0
if "FIRSTSECTION" in mark:
weightPos = weightPos + 2
if "FIRSTSENTENCE" in mark:
weightPos = weightPos + 2
if "LASTSENTENCE" in mark:
weightPos = weightPos + 1
if "LASTSECTION" in mark:
weightPos = weightPos + 1
sentence["weightPos"] = weightPos
# 计算句子的线索词权重
index = [" 总之 ", " 总而言之 "]
for sentence in self.sentences:
sentence["weightCueWords"] = 0
sentence["weightKeywords"] = 0
for i in index:
for sentence in self.sentences:
if sentence["text"].find(i) >= 0:
sentence["weightCueWords"] = 1
for keyword in self.keywords:
for sentence in self.sentences:
if sentence["text"].find(keyword) >= 0:
sentence["weightKeywords"] = sentence["weightKeywords"] + 1
for sentence in self.sentences:
sentence["weight"] = sentence["weightPos"] + 2 * sentence["weightCueWords"] + sentence["weightKeywords"]
def getSummary(self, ratio=0.1):
self.keywords = list()
self.sentences = list()
self.summary = list()
# 调用方法,分别计算关键词、分句,计算权重
self.getKeywords()
self.splitSentence()
self.sentenceWeight()
# 对句子的权重值进行排序
self.sentences = sorted(self.sentences, key=lambda k: k['weight'], reverse=True)
# 根据排序结果,取排名占前 ratio% 的句子作为摘要
for i in range(len(self.sentences)):
if i < ratio * len(self.sentences):
sentence = self.sentences[i]
self.summary.append(sentence["text"])
return self.summary
def main_handler(event, context):
nlp = NLPAttr(json.loads(event['body'])['text'])
return {
"keywords": nlp.getKeywords(),
"summary": "。".join(nlp.getSummary())
}
编写项目serverless.yaml文件:
nlpDemo:
component: "@serverless/tencent-scf"
inputs:
name: nlpDemo
codeUri: ./
handler: index.main_handler
runtime: Python3.6
region: ap-guangzhou
description: 文本摘要 / 关键词功能
memorySize: 256
timeout: 10
events:
- apigw:
name: nlpDemo_apigw_service
parameters:
protocols:
- http
serviceName: serverless
description: 文本摘要 / 关键词功能
environment: release
endpoints:
- path: /nlp
method: ANY
由于项目中使用了jieba,所以在安装的时候推荐在 CentOS 系统下与对应的 Python 版本下安装,也可以使用我之前为了方便做的一个依赖工具:
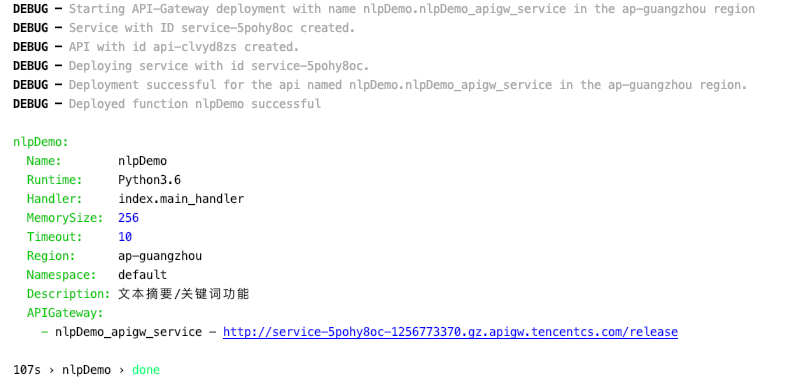
通过sls --debug进行部署:
部署完成,可以通过 PostMan 进行简单的测试:
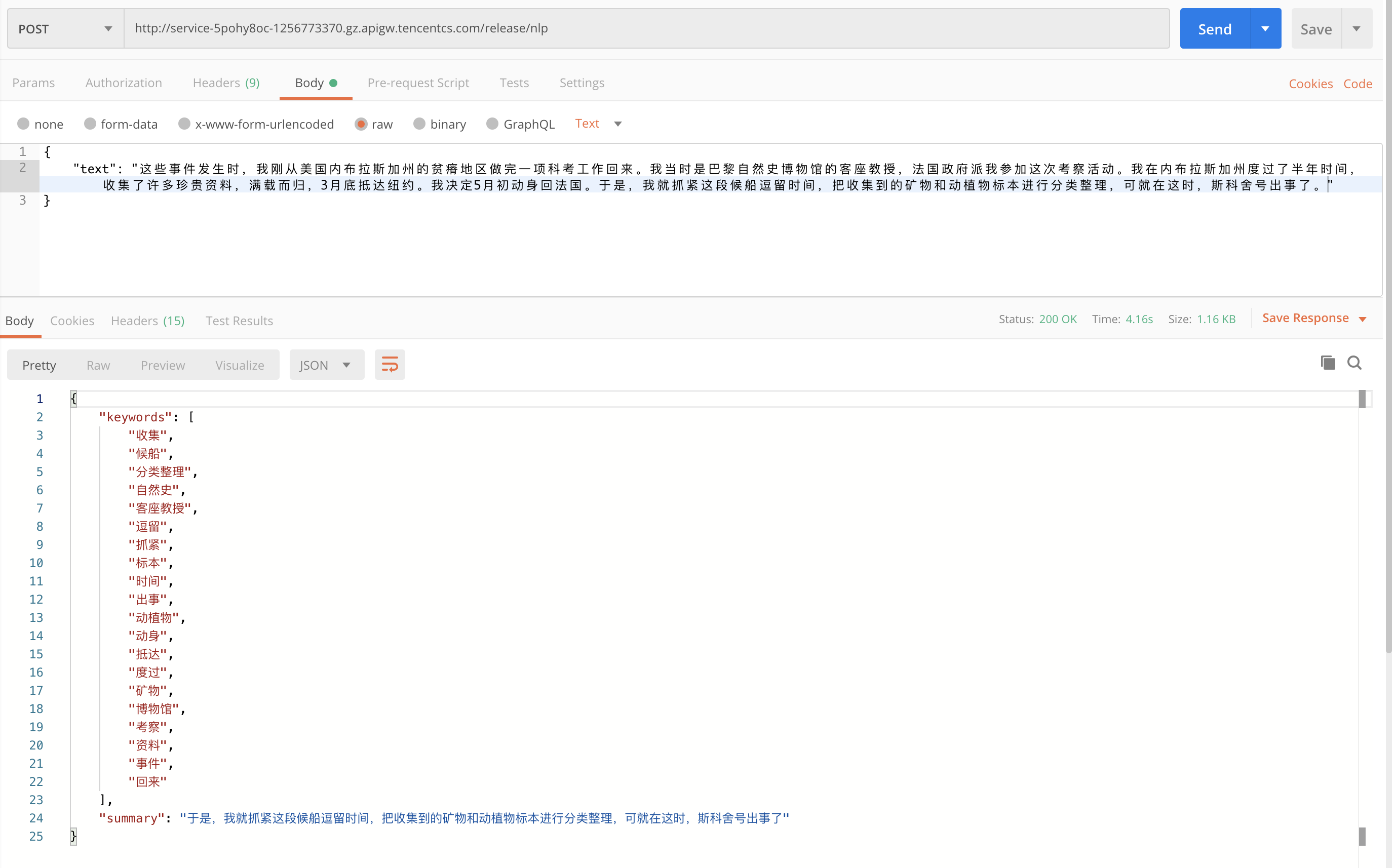
从上图可以看到,我们已经按照预期输出了目标结果。至此,文本摘要 / 关键词提取的 API 已经部署完成。
总结
相对来说,通过 Serveless 架构做 API 是非常容易和方便的,可实现 API 的插拔行,组件化,希望本文能够给读者更多的思路和启发。
我们诚邀您来体验最便捷的 Serverless 开发和部署方式。在试用期内,相关联的产品及服务均提供免费资源和专业的技术支持,帮助您的业务快速、便捷地实现 Serverless!
One More Thing
3 秒你能做什么?喝一口水,看一封邮件,还是 —— 部署一个完整的 Serverless 应用?
复制链接至 PC 浏览器访问:https://serverless.cloud.tencent.com/deploy/express
3 秒极速部署,立即体验史上最快的 Serverless HTTP 实战开发!
传送门:
- GitHub: github.com/serverless
- 官网:serverless.com
欢迎访问:Serverless 中文网,您可以在 最佳实践 里体验更多关于 Serverless 应用的开发!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号