分布式数据库的数据备份/恢复,这些你一定要了解
一、概述

二、存储引擎层的备份恢复
- 物理备份恢复方法
1. 前期准备
|
IP |
Hostname |
SequoiaDB用户 |
备注 |
|
192.168.1.3 |
sdb03 |
sdbadmin |
|
|
192.168.1.4 |
sdb04 |
sdbadmin |
|
|
192.168.1.5 |
sdb05 |
sdbadmin |
备份磁盘(挂载目录/sdbdata/backup) |
[root@sdb05 ~]# cat /etc/exports /sdbdata/backup *(insecure,rw,sync,no_wdelay,insecure_locks,no_root_squash) [root@sdb03 ~]# mount -t nfs -o rw,bg,hard,nointr,tcp 192.168.1.5:/sdbdata/backup /sdbdata/backup [root@sdb03 ~]# chown -R sdbadmin:sdbadmin_group /sdbdata/backup [root@sdb04 ~]# mount -t nfs -o rw,bg,hard,nointr,tcp 192.168.1.5:/sdbdata/backup /sdbdata/backup [root@sdb04 ~]# chown -R sdbadmin:sdbadmin_group /sdbdata/backup [root@sdb04 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/centos-root 15G 4.4G 11G 29% / /dev/vdb 985G 129G 806G 14% /sdbdata /dev/vda1 497M 172M 326M 35% /boot /dev/vda3 50G 13G 38G 26% /opt 192.168.1.5:/sdbdata/backup 985G 129G 807G 14% /sdbdata/backu
2. 全量备份
[sdbadmin@sdb05 ~]#cat backup_full.sh
#!/bin/bash
date
/opt/sequoiasql/mysql/bin/mysqldump --login-path=mysql -A -d > /sdbdata/backup/full/create`date +%y%m%d%H`.sql
/opt/sequoidb/bin/sdblist -l -m list > /sdbdata/backup/full/sdblist`date +%y%m%d%H`.sql
/opt/sequoiadb/bin/sdb 'db=new Sdb()'
/opt/sequoiadb/bin/sdb 'db.backup ( { Name : "cluster_backup", Path : "/sdbdata/backup/full/%g", Overwrite : true, Description : "full_backup" } ) ;'
date
db.backup()备份常用参数说明
Name:备份名称,缺省则以当前时间格式命名,如“2016-01-01-15:00:00”,格式为“YYYY-MM-DD-HH:mm:ss”。
Description:备份用户描述信息。
Path:本次备份的指定路径,缺省为配置参数“bkuppath”中指定的路径。
EnsureInc:备份方式,true 表示增量备份,false 表示全量备份,缺省为 false。
OverWrite:对于同名备份是否覆盖,true 表示覆盖,false 表示不覆盖,如果同名则报错;缺省为 false。
GroupName:对指定组进行备份,缺省为对全系统备份,当需要对多个组进行备份可以指定为数组类型,如:["datagroup1", "datagroup2"]。
![]()

![]()

![]()

3. 增量备份
[sdbadmin@sdb05 ~]#cat backup_incre.sh
#!/bin/bash
date
/opt/sequoiasql/mysql/bin/mysqldump --login-path=mysql -A -d > /sdbdata/backup/full/create`date +%y%m%d%H`.sql
/opt/sequoidb/bin/sdblist -l -m list > /sdbdata/backup/full/sdblist`date +%y%m%d%H`.sql
/opt/sequoiadb/bin/sdb 'db=new Sdb();'
/opt/sequoiadb/bin/sdb 'db.backup ( { Name : "cluster_backup", Path : "/sdbdata/backup/full/%g", EnsureInc : true } );'
date


4. 全量恢复
(1)配置单向ssh 免密服务
[sdbadmin@sdb05 ~]#ssh-keygen -t rsa
[sdbadmin@sdb05 ~]#ssh-copy-id sdbadmin@sdb03
[sdbadmin@sdb05 ~]#ssh-copy-id sdbadmin@sdb04
[sdbadmin@sdb05 ~]#ssh-copy-id sdbadmin@sdb05
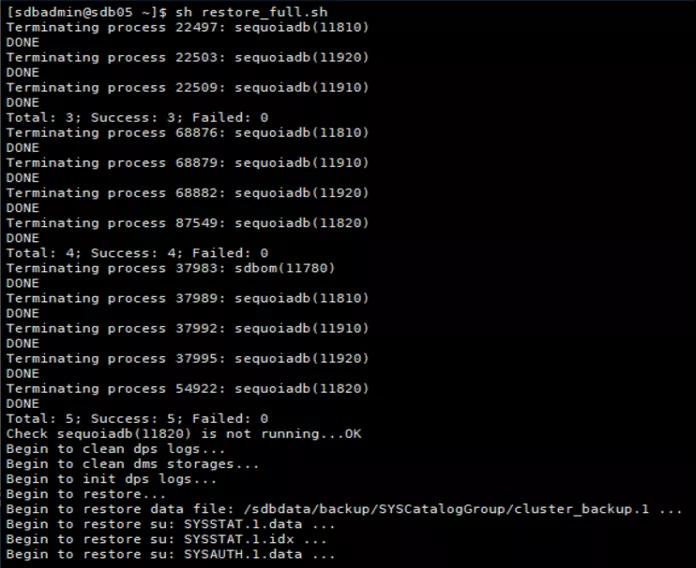
(2)恢复脚本
[sdbadmin@sdb05 ~]#cat restore_full.sh
#!/bin/bash
#停止集群
for hostname in {sdb03,sdb04,sdb05}
do
ssh $hostname /opt/sequoiadb/bin/sdbstop -t all
done
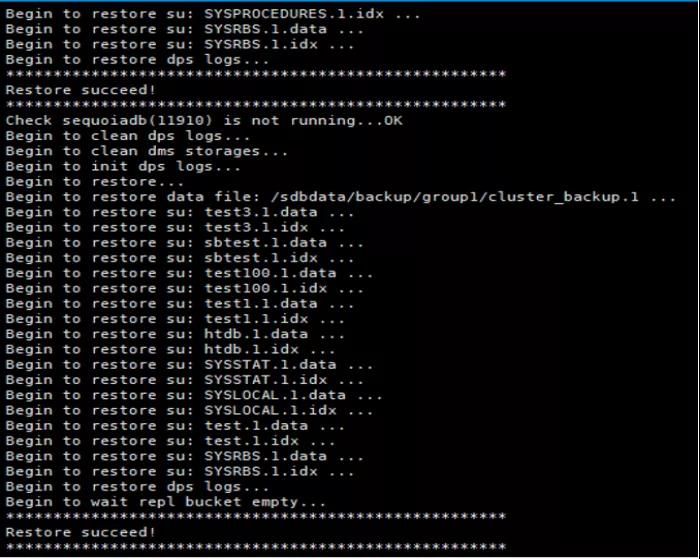
#全量恢复一份完整的副本数据
for groupname in `cat /sdbdata/backup/full/sdblist20200717.sql | awk '{print $8}' | grep -Evi "GroupName|SYSCoord" `
do
/opt/sequoiadb/bin/sdbrestore -p /sdbdata/backup/full/$groupname/ -n cluster_backup -b 0 -i 0
done
#删除另外2台服务器之前的副本数据,scp拷贝全量恢复的副本数据
for hostname in {sdb03,sdb04}
do
for dbpath in `cat /sdbdata/backup/full/sdblist20200717.sql | awk '{print $10}'| grep -Evi "dbpath|*11810"`
do
ssh -t sdbadmin@$hostname "rm -rf "$dbpath*
scp -pr $dbpath* $hostname:$dbpath &
done
done
#启动集群
/bin/read -p " Do you want to start SequoiaDB(yes or no)? " Do
while [[ "$Do" != "no" ]] && [[ "$Do" != "yes" ]]
do
/bin/read -p "Do you want to start SequoiaDB(yes/no)?" Do
done
if [ "$Do" == "yes" ]
then
for hostname in {sdb03,sdb04,sdb05}
do
ssh $hostname /opt/sequoiadb/bin/sdbstart -t all
done
elif [ "$Do" == "no" ]
then
echo "please start SequoiaDB by hand"
fi
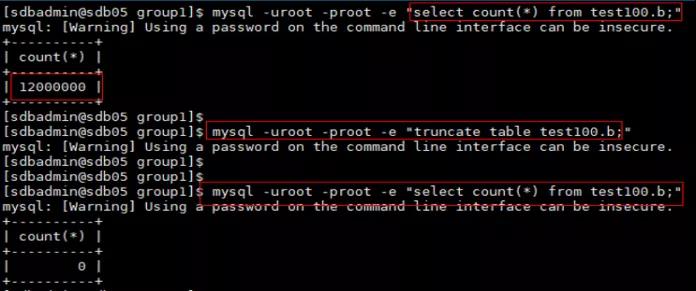
sdbrestore数据恢复常用参数:
--bkpath -p:备份源数据所在路径。
--increaseid -i:需要恢复到第几次增量备份,缺省恢复到最后一次 ( -1 )。
--beginincreaseid -b:需要从第几次备份开始恢复,缺省由系统自动计算 ( -1 )。
--bkname -n:需要恢复的备份名。
--action -a:恢复行为,“restore”表示恢复,“list”表示查看备份信息,缺省为“restore”。
--diaglevel -v:恢复工具自身的日志级别,缺省为 WARNING ( 3
![]()
![]()

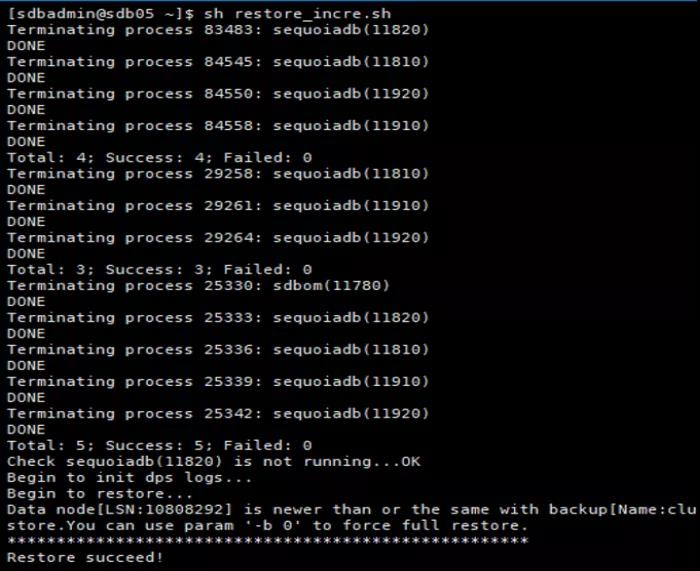
5. 增量恢复
[sdbadmin@sdb05 ~]#cat restore_incre.sh
#!/bin/bash
#停止集群
for hostname in {sdb03,sdb04,sdb05}
do
ssh $hostname /opt/sequoiadb/bin/sdbstop -t all
done
#增量恢复副本数据
for groupname in `cat /sdbdata/backup/full/sdblist20200717.sql | awk '{print $8}' | grep -Evi "GroupName|SYSCoord"`
do
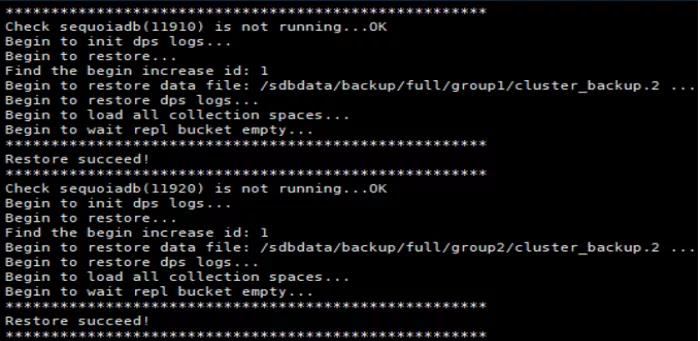
/opt/sequoiadb/bin/sdbrestore -p /sdbdata/backup/full/$groupname/ -n cluster_backup -b -1
done
#启动集群
/bin/read -p " Do you want to start SequoiaDB(yes or no)? " Do
while [[ "$Do" != "no" ]] && [[ "$Do" != "yes" ]]
do
/bin/read -p "Do you want to start SequoiaDB(yes/no)?" Do
done
if [ "$Do" == "yes" ]
then
for hostname in {sdb03,sdb04,sdb05}
do
ssh $hostname /opt/sequoiadb/bin/sdbstart -t all
done
elif [ "$Do" == "no" ]
then
echo "please start SequoiaDB by hand"
fi
![]()
![]()

逻辑备份恢复方法
1. sdbexprt 工具使用

(1)导出集合sbtest.sbtest1 的数据 sdbexprt \ --hostname "localhost" \ --svcname "11810" \ --user "sdbadmin" \ --password "sdbadmin" --type 'json' \ --csname 'sbtest' \ --clname 'sbtestl' \ --file '/tmp/sbtest.sbtest1.json' (2)导出集合空间sbtest下,所有集合的数据 sdbexprt \ --hostname "localhost" \ --svcname "11810" \ --user "sdbadmin" \ --password "sdbadmin" --type 'json' \ --cscl 'sbtest' \ --dir '/tmp'
2. sdbimprt工具使用
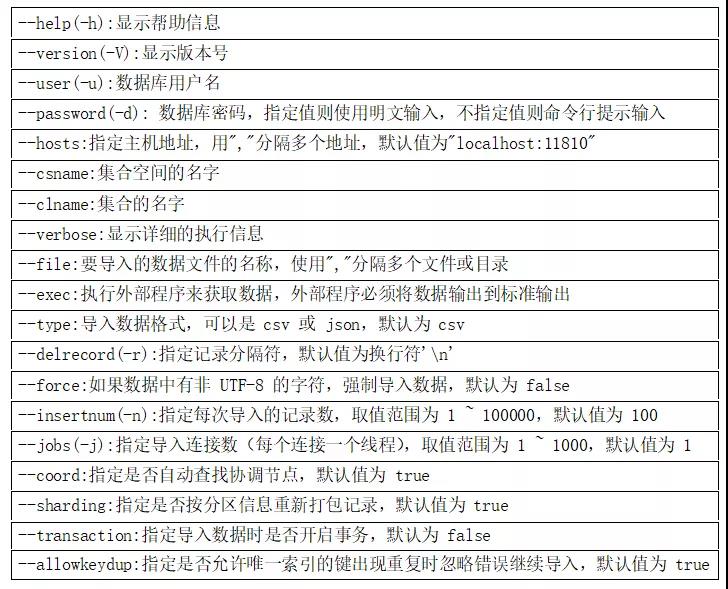
sdbimprt \ --hosts 'localhost:11810' \ --user 'sdbadmin' \ --password 'sdbadmin' \ --csname 'sbtest' \ --clname 'sbtest1' \ --insertnum 10000 \ --jobs 20 \ --type 'json' \ --file '/tmp/sbtest.sbtest1.json' --coord false \ --ignorenull true \ --verbose true \ --force false \ --errorstop true \ --sharding true \ --transaction false \ --allowkeydup true
三、SQL 实例层的备份操作
1. mysqldump 工具使用

(1)备份所有库: mysqldump -h 192.168.3.6 -P 3306 -u root -p root123456 -A > /backup/all.sql (2)备份几个库: mysqldump --h 192.168.3.6 -P 3306 -u root -p root123456 -B 库名1 库名2 > /backup/database.sql (3)备份单个库某几个表(表名用空格隔开即可) Mysqldump -h 192.168.3.6 -P 3306 -u root -p root123456 库名 表名1 表名2> /backup/table.sql (4)mysqldump恢复 mysql -h 192.168.3.6 -P 3306 -u root -p root123456 < /backup/all.sql; 或者 MySQL>source /backup/all.sql
2. mydumper&myloader工具使用

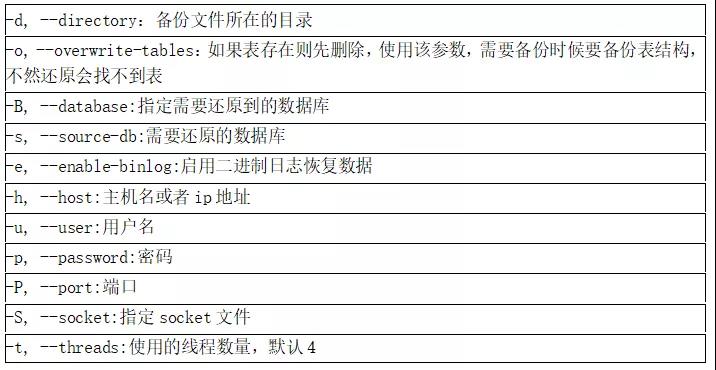
$time mydumper -h 192.168.3.6 -P 3306 -u root -p root123456 -t 6 -c -e -B sbtest -o /home/data/ $time myloader -h 192.168.3.6 -P 3306 -u root -p root123456 -t 6 -B sbtest -o -d /home/data
- 小结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号