
巨杉Tech|SequoiaDB 巨杉数据库高可用容灾测试
数据库的高可用是指最大程度地为用户提供服务,避免服务器宕机等故障带来的服务中断。数据库的高可用性不仅仅体现在数据库能否持续提供服务,而且也体现在能否保证数据的一致性。
SequoiaDB 巨杉数据库作为一款100%兼容 MySQL 的国产开源分布式数据库,它在高可用方面的表现如何?它的高可用性是如何实现的?本文将详细描述SequoiaDB巨杉数据库的高可用性原理,并进行测试验证。
01 巨杉分布式集群架构SequoiaDB 巨杉数据库采用计算与存储分离架构,SequoiaSQL-MySQL 是 SQL 计算层,存储层由协调节点、编目节点和数据节点组成。

图1 SequoiaDB分布式架构
如图1所示是最简单的 SequoiaDB 分布式数据库集群架构图,由1个协调节点,1个编目节点,3个数据节点和 SequoiaSQL-MySQL 构成。其中数据节点在三个服务器上,包括三个数据复制组1、2、3,每个数据复制组由3个完全相同的数据副本组成,数据副本之间通过日志同步保持数据一致。
A, A1, A2组成数据复制组1,三者是完全相同数据副本。数据复制组2、3类似于数据复制组1。在 SequoiaDB 分布式集群中,每个复制组最多支持 7 个数据副本。
本文的高可用测试环境采用图1所示的分布式集群架构,其中主节点有读写功能,两个备副本可以执行读操作或备份。
02 巨杉数据库高可用实现SequoiaDB 高可用采用 Raft 算法实现,多副本之间通过日志同步保持数据一致性。

图2 三个节点之间保持连接
如图2所示,SequoiaDB 集群三个副本之间通过心跳保持连接。
数据组副本之间通过共享心跳信息 sharing-beat 进行状态共享。如图3所示,sharing-beat 心跳信息结构包括心跳 ID、自身开始LSN、自身终止LSN、时间戳、数据组版本号、自身当前的角色和同步状态。

图3 心跳状态信息结构
每个节点都维护一张 status-sharing table 表,用来记录节点状态。sharing-beat 每2秒发送一次,采集应答信息,若连续N秒未收到应答信息,则认为节点宕机。
集群中只有一个节点作为主节点,其他节点为备节点。如果出现多主或者双主,需要根据 LSN 对比进行降备,保证集群中只有一个主节点。
Note:1)当主节点宕机时,需要从备节点中选举出一个新的节点作为新的主节点。 2)当备节点宕机时,主节点不受影响,等备节点恢复后,通过日志同步继续与主节点保持数据一致即可。
下面介绍当主节点宕机时,选举新主节点的过程。选举条件满足下面2个条件可以被选举成为主节点:1. 多数备节点投票通过2. 该节点LSN最大
选举过程1)当主节点A宕机时,A自动降为备节点,关闭协调节点的业务连接。

图4 集群中主节点挂掉
2)A1和A2都会判断自身是否具备升为主节点的条件,若符合即发起选举请求。条件内容:
-
自己不是主节点
-
剩下的备节点占半数以上
-
自己的LSN比其它备节点的LSN新
3)其它备节点会把被投票节点的 LSN 与自己的 LSN 做对比,若比自己的 LSN 新,则投赞成票,否则投反对票。4)若赞成票超过(n/2+1),则支持该节点为主节点,选举成功。否则保持备节点角色,选举失败。5)选举成功后,通过心跳状态信息共享数据组信息给其它节点。
03 高可用容灾验证一般分布式数据库 POC 测试包含功能测试、性能测试、分布式事务测试、高可用容灾测试和兼容性测试等。下面将对 SequoiaDB 巨杉数据库的高可用性进行验证测试。
测试环境说明

本文测试环境采用分布式集群,包含1个 SequoiaSQL-MySQL,3个数据节点,1个编目节点,1个协调节点,搭建集群方式具体可参考巨杉官网虚拟机镜像搭建教程。在 kill 掉主节点进程之后,我们对分布式数据库集群进行读写操作,来验证高可用性。
-
查看服务器集群状态
# service sdbcm status ..... Main PID: 803 (sdbcm) Tasks: 205 (limit: 2319) CGroup: /system.slice/sdbcm.service ├─ 779 sdbcmd ├─ 803 sdbcm(11790) ├─1166 sequoiadb(11840) D ├─1169 sequoiadb(11810) S ├─1172 sequoiadb(11830) D ├─1175 sdbom(11780) ├─1178 sequoiadb(11820) D ├─1181 sequoiadb(11800) C 1369 /opt/sequoiadb/plugins/SequoiaSQL/bin/../../../java/jdk/bin/java -jar /opt/sequoiadb/plugins/SequoiaSQL .....
-
SequoiaDB 分布式集群中数据节点端口在11820,11830,11840;编目节点11800,协调节点在11810
sdbadmin@sequoiadb:~$ ps -ef|grep sequoiadb sdbadmin 1166 1 0 Aug20 ? 00:02:23 sequoiadb(11840) D sdbadmin 1169 1 0 Aug20 ? 00:01:43 sequoiadb(11810) S sdbadmin 1172 1 0 Aug20 ? 00:02:24 sequoiadb(11830) D sdbadmin 1178 1 0 Aug20 ? 00:02:33 sequoiadb(11820) D sdbadmin 1181 1 0 Aug20 ? 00:04:01 sequoiadb(11800) C
-
kill 掉11820的主节点,执行查询和写入sql
sdbadmin@sequoiadb:~$ kill 1178 sdbadmin@sequoiadb:~$ ps -ef|grep sequoiadb sdbadmin 1166 1 0 Aug20 ? 00:02:24 sequoiadb(11840) D sdbadmin 1169 1 0 Aug20 ? 00:01:43 sequoiadb(11810) S sdbadmin 1172 1 0 Aug20 ? 00:02:24 sequoiadb(11830) D sdbadmin 1181 1 0 Aug20 ? 00:04:01 sequoiadb(11800) C sdbadmin 1369 1 0 Aug20 ? 00:01:33 /opt/sequoiadb ....
-
执行查看 sql,查看插入操作之前数据为121
mysql> select * from news.user_info; +------+-----------+ | id | unickname | +------+-----------+ | 1 | test1 | ........ | 119 | test119 | | 120 | test120 | | 121 | test121 | +------+-----------+ 121 rows in set (0.01 sec)
-
执行写入 sql,查看插入是否成功
mysql> insert into news.user_info(id,unickname)values(122,"s uccess"); Query OK, 1 row affected (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.01 sec) mysql> select * from news.user_info; +------+-----------+ | id | unickname | +------+-----------+ | 1 | test1 | ......... | 120 | test120 | | 121 | test121 | | 122 | success | +------+-----------+ 122 rows in set (0.00 sec)
数据(122, “success”)数据插入成功,在其中一个主节点挂掉情况下,读写都没有受到影响,数据读写保持一致,高可用性得到验证。
现在执行导入1000w数据写入脚本 imprt.sh,在执行过程中 kill 掉主数据节点,模拟主节点故障场景,在巨杉数据库图形化监控界面 SAC 上查看集群读写变化。
Note: 如果需要获取 imprt.sh 脚本,关注“巨杉数据库”公众号回复 “imprt” 即可获取。
-
执行导入数据脚本
./imprt.sh 协调节点主机 协调节点端⼝ 次数./imprt.sh 192.168.1.122 11810 100
-
如图5所示,在执行导入数据时刻,kill 掉主数据节点,insert 写入下降,之后集群恢复高可用
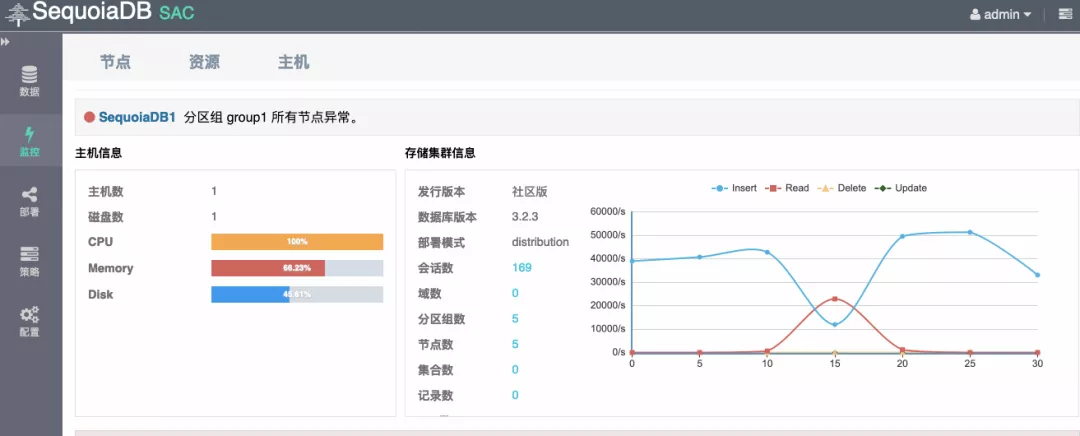
图5 SAC监控界面集群读写变化示意图
图6 SAC查看tpcc写入数据量示意图
从 SAC 可视化界面中可以看到,当主数据节点在我们执行插入1000w数据操作的过程中出现故障,数据读写受到影响的持续时间很短。最后通过使用 imprt.sh 脚本重新导入插入失败的数据,则可以保证数据最终一致性。
04 总结SequoiaDB
分布式集群具备较好的高可用性,集群可以设置多个数据复制组,每个数据复制组由多个完全相同的副本构成,副本之间通过 Raft 算法和日志同步方式保持数据一致性。最后,本文也验证了在执行千万级数据写操作时,若集群主数据节点宕机,分布式集群可以正常读写数据,并且数据保持最终一致,高可用性得到验证。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号