基于FPGA的CNN算法移植(二)硬件架构
这次我们来谈谈硬件架构,其实没啥好说的,就是科普的东西。因为这个玩意儿真的没啥新意
第一款:google的TPU 架构
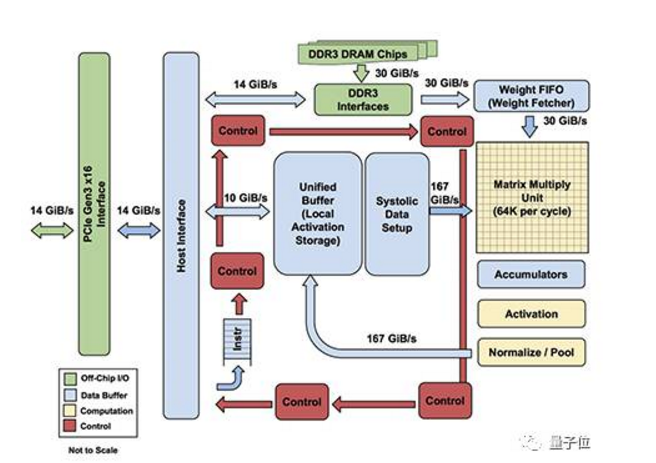
图中DDR3仅仅是用来传送数据量小的权重,因为DDR3的速度实在是跟不上啊。而激活值采用167GiB/S 的速度传入和传出,中间那个矩阵乘法器是65536个 ,运算力相当野蛮吧。中间就是一些控制逻辑——不同层控制不同,还有就是一些为了保障速度的辅助逻辑。
第二款: 深鉴科技的DPU
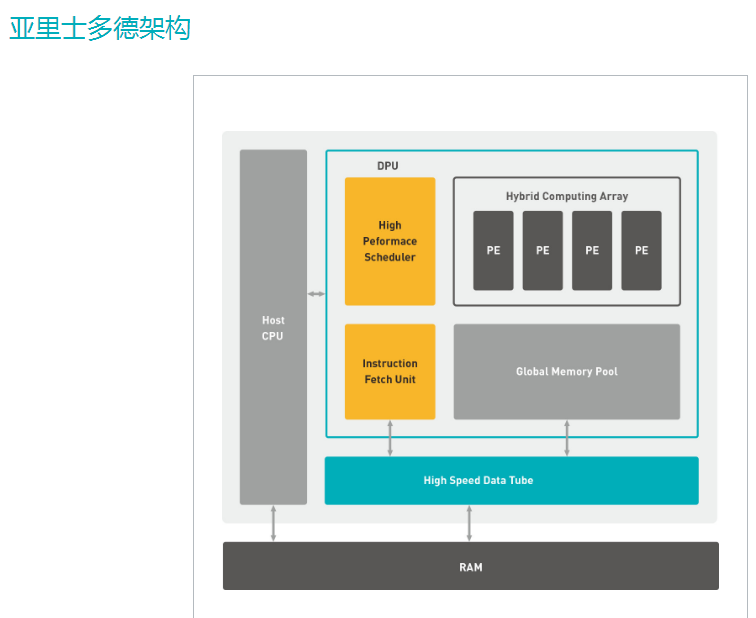
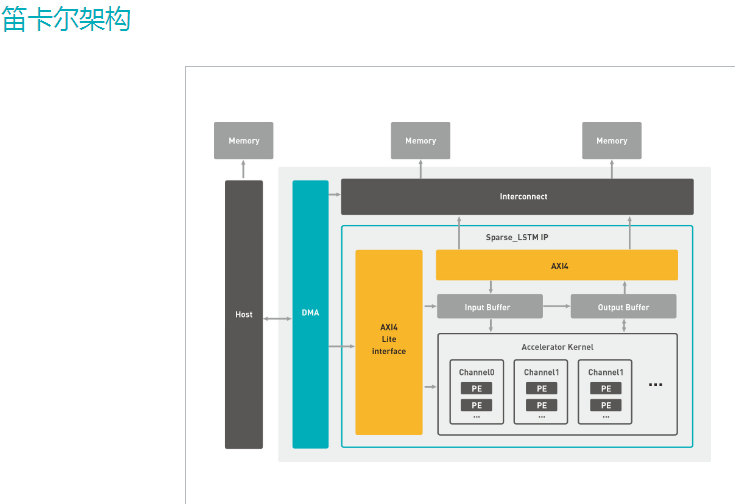
由上面的TPU过渡到下面的DPU 感觉如何,上一博文中说了,就是input buffer, 处理,output buffer ,然后看这两个buffer里面的数据怎么来最快,怎么去的最快。over。有多少资源就设计多大的处理器,资源决定了你流水多少。如此,你的latency的出来了,嗯,于是你的整个项目性能就大概出来了。
第三款:某公司用ZC706做的项目架构
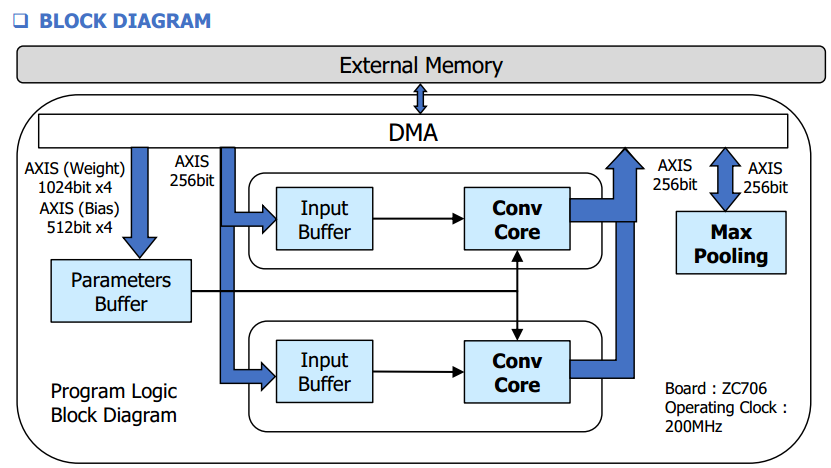
呵呵,上面都说完了,这个图的文案我都不知道扯啥了。
哦,这个是用HLS 做的,应该是卷积和pooling是两个独立IP ,没有合并起来,所以对AXI总线多了两次操作,或许可以合并的呢
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
作者:清霜一梦
欢迎加入: FPGA广东交流群:162664354

 浙公网安备 33010602011771号
浙公网安备 33010602011771号