

python中lxml库与Xpath语法(含实例)
Xpath表达式:
/ 描述:从根节点选取
// 描述:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置
. 描述:选取当前节点
.. 描述:选取当前节点的父节点
@ 描述:选取属性
定位目标标签思路:“先抓大再抓小”,先找到循环节点,再细分
给出一个简单例子如下:
from lxml import etree import requests headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36' } url = 'http://a.qidian.com/?page=1' res = requests.get(url,headers=headers) selector = etree.HTML(res.text) #print(res.text) ''' str=selector.xpath('/html/body/div[1]/div[5]/div[2]/div[2]/div/ul/li[1]/div[2]/p[1]/a[1]/text()')#通过/text()可以获得标签中的文字信息 print(str) ''' infos = selector.xpath('//ul[@class="all-img-list cf"]/li') print(infos) for info in infos: author = info.xpath('div[2]/p[1]/a[1]/text()')[0] print(author)
网站:
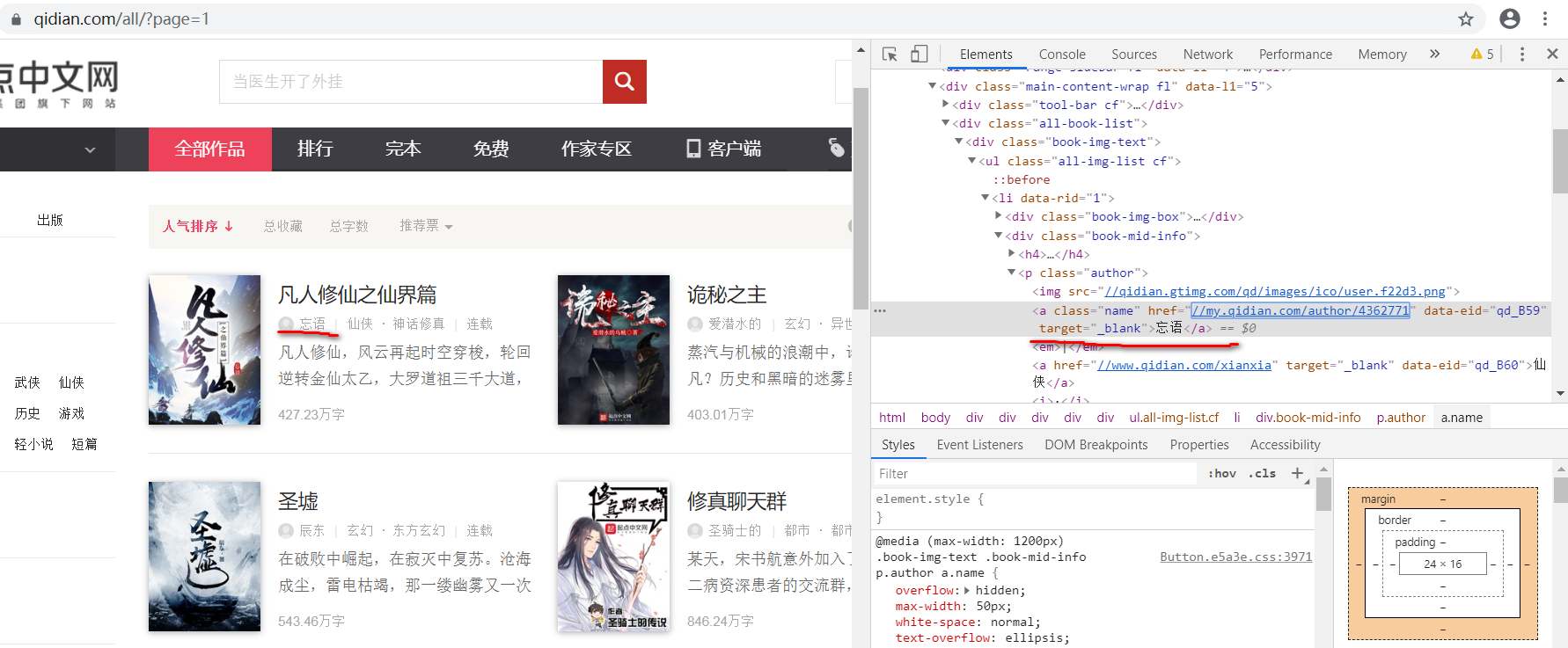

错误点:
author = info.xpath('/div[2]/p[1]/a[1]/text()')[0]
开始的时候,一直多加了一个单斜杠,找了好久这个错才找出来,一直以为我找的Xpath路径出错了。
正确:
author = info.xpath('div[2]/p[1]/a[1]/text()')[0]

