
Ubuntu16.04下Hadoop的本地安装与配置
一、系统环境
os : Ubuntu 16.04 LTS 64bit
jdk : 1.8.0_161
hadoop : 2.6.4
部署时使用的用户名为hadoop,下文中需要使用用户名的地方请更改为自己的用户名。
二、安装步骤
1、安装并配置ssh
1.1 安装ssh
输入命令: $ sudo apt-get install openssh-server ,安装完成后使用命令 $ ssh localhost 登录本机。首次登录会有提示,输入yes,接着输入当前用户登录电脑的密码即可。
1.2 配置ssh无密码登录
首先使用命令 $ exit 退出上一步的ssh,然后使用ssh-keygen生成密钥,最后将密钥加入授权即可,命令如下:
$ exit # 退出刚才的 ssh localhost
$ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
$ ssh-keygen -t rsa # 会有提示,都按回车就可以
$ cat ./id_rsa.pub >> ./authorized_keys # 加入授权
配置完成之后再使用 $ ssh localhost 登录就不需要密码了。
2、安装并配置java
2.1 安装java
去官方网站下载jdk-8u161-linux-x64.tar.gz ,使用如下命令解压并安装到/usr/local/目录下:
$ cd ~/下载
$ sudo tar -xzf jdk-8u161-linux-x64.tar.gz -C /usr/local
$ cd /usr/local
$ sudo mv jdk1.8.0_161/ java
2.2 配置环境变量
使用命令 $ vim ~/.bashrc 编辑文件~/.bashrc,在该文件开头添加以下内容:
export JAVA_HOME=/usr/local/java
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
最后使用命令 $ source ~/.bashrc 让环境变量生效。使用java -version检查是否配置正确,正确配置如下图:

3、hadoop的安装与配置
3.1 hadoop下载与安装
去hadoop官网下载hadoop-2.6.4.tar.gz ,使用以下命令安装到/usr/local/目录下:
$ sudo tar -xzf hadoop-2.6.4.tar.gz -C /usr/local $ cd /usr/local $ sudo mv hadoop-2.6.4/ hadoop $ sudo chown -R hadoop ./hadoop #前一个hadoop为用户名,更改为自己的用户名即可
将以下代码添加到~/.bashrc中:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=$PATH:$HADOOP_HOME/bin
然后使用命令 source ~/.bashrc 让环境变量生效,使用命令 hadoop version 检查环境变量是否添加成功,成功如下:

3.2 hadoop单机配置
安装后的hadoop默认为单机配置,无需其他配置即可运行。使用hadoop自带的单词统计的例子体验以下:
$ cd /usr/local/hadoop $ mkdir ./input $ cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件 $ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+' $ cat ./output/* # 查看运行结果
结果为:
1 dfsadmin
3.3 hadoop伪分布式配置
hadoop的配置文件存放在/usr/local/hadoop/etc/hadoop下,要修改该目录下的文件core-site.xml和hdfs-site.xml来达到实现伪分布式配置。
修改core-site.xml,将<configure></configure>修改为:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
修改hdfs-site.xml,将<configure></configure>修改为:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>
配置完成后在/usr/local/hadoop下使用命令 $ ./bin/hdfs namenode -format 实现namenode的格式化,成功后会有“successfully formatted”及“Exiting with status 0”的提示,如下图:
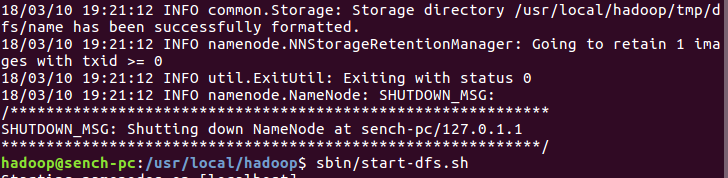
接着使用sbin/start-dfs.sh来开启namenode和datanode,开启后使用命令jps查看是否开启成功,如下图:
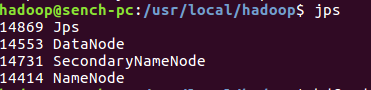
namenode和datanode都要出现才算成功。
4、配置yarn(非必须)
在/usr/local/hadoop下操作
$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
然后修改etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
修改etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
启动资源管理器
$ ./sbin/start-yarn.sh
$ ./sbin/mr-jobhistory-daemon.sh start historyserver #查看历史任务
启动成功后可以在http://localhost:8088/cluster访问集群资源管理器。
此时使用jps可以看到:
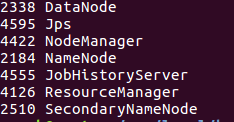
关闭资源管理器
$ ./sbin/stop-yarn.sh
$ ./sbin/mr-jobhistory-daemon.sh stop historyserver
三、参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号