
eBPF开发指南
0x1:技术背景
bpf:
BPF 的全称是 Berkeley Packet Filter,是一个用于过滤(filter)网络报文(packet)的架构。(例如tcpdump),目前称为Cbpf(Classical bpf)
Ebpf:
eBPF全称 extended BPF,Linux Kernel 3.15 中引入的全新设计, 是对既有BPF架构进行了全面扩展,一方面,支持了更多领域的应用,比如:内核追踪(Kernel Tracing)、应用性能调优/监控、流控(Traffic Control)等;另一方面,在接口的设计以及易用性上,也有了较大的改进。
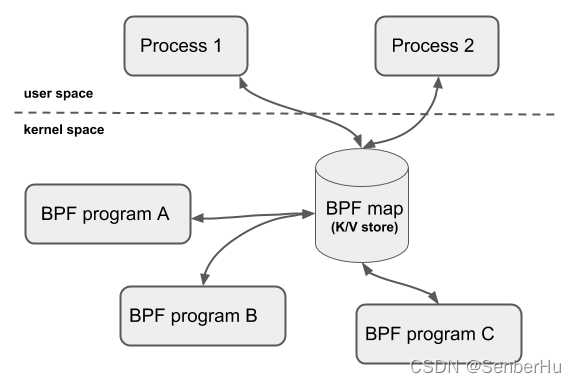
eBPF 支持在用户态将 C 语言编写的一小段“内核代码”注入到内核中运行,注入时要先用 llvm 编译得到使用 BPF 指令集的 ELF 文件,然后从 ELF 文件中解析出可以注入内核的部分,最后用 bpf_load_program() 方法完成注入。 用户态程序和注入到内核中的程序通过共用一个位于内核的 eBPF MAP 实现通信。为了防止注入的代码导致内核崩溃,eBPF 会对注入的代码进行严格检查,拒绝不合格的代码的注入。
- eBPF prog load的严格的verify机制
- eBPF访问内核资源需借助各种eBPF 的helper func,helper func函数能在最坏的情况下保证安全
- 现在,Linux 内核只运行 eBPF,内核会将加载的 cBPF 字节码 透明地转换成 eBPF 再执行
0x2:技术对比
| 优劣 | eBPF | 源码开发 | 热补丁 |
|---|---|---|---|
| 优势 | 1.安全,不会引起宕机 2.自主,可控 2.热加载(良好的加载/卸载流程) 3.开启CO-RE后,移植性高,适配量小 4.可以在注入的代码中写入业务逻辑,优化hids性能 5.开发难度低,上手快 |
1.体积小 2.自由度高 3.性能高 4.功能强大 |
1.体积小 2.自由度高 3.性能高 4.热加载,不需要重启 |
| 缺点 | 1.功能受限(验证器) 2.强依赖于内核版本 3.不支持内核函数调用 4.单函数最大512byte栈空间,通过尾调用扩展到8K 5.性能不如其他两者 |
1.需要重新编译内核 2.需要重启业务主机 3.需要开发者熟悉内核 4.适配工作量巨大 5.netlink上发数据有性能瓶颈 |
1.需要开发者熟悉内核 2.适配工作量大 |
0x3:运行流程

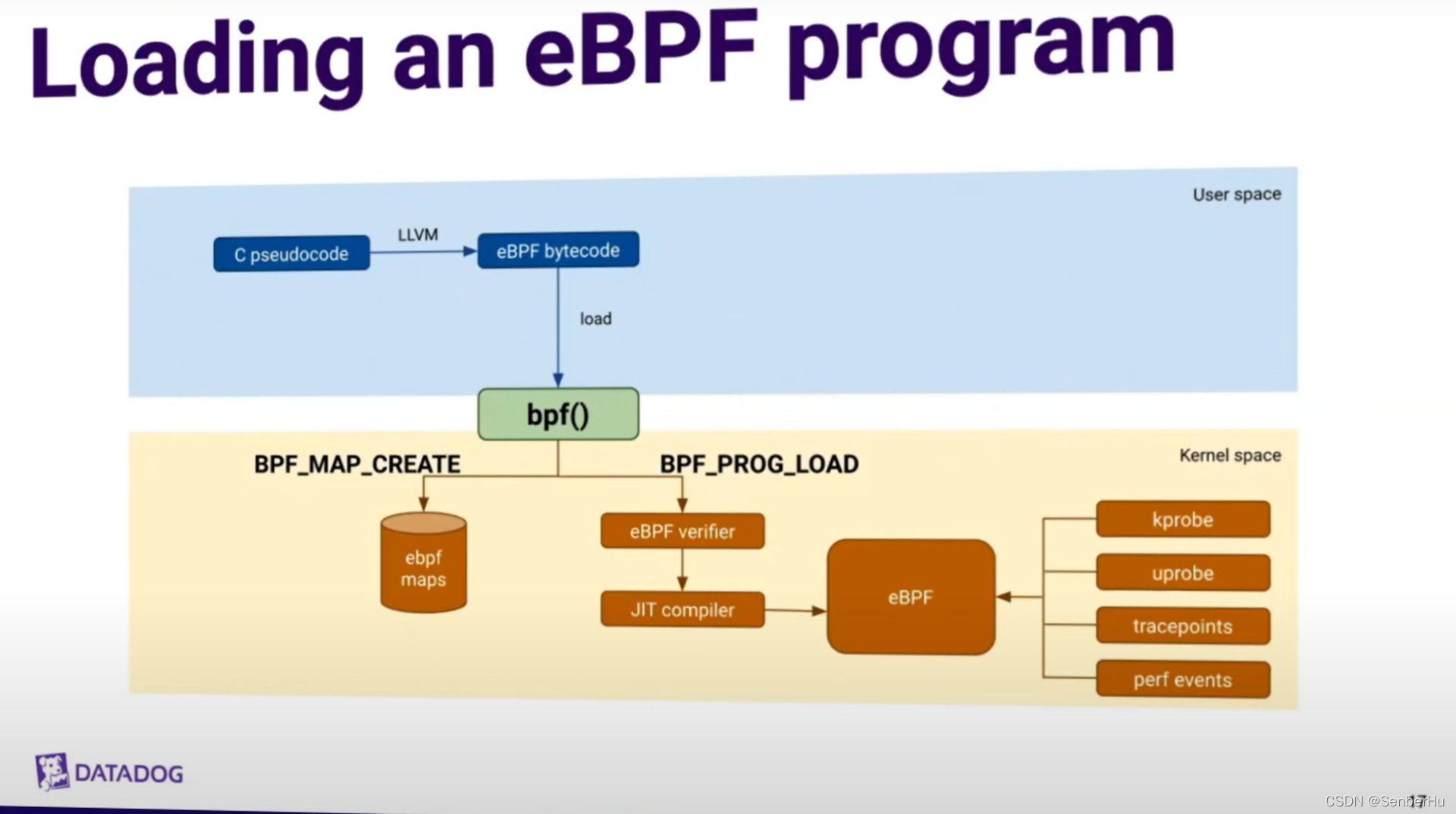
用 C 编写 BPF 程序
用 LLVM 将 C 程序编译成对象文件(ELF)
用户空间 BPF ELF 加载器(例如 libbpf)解析对象文件
加载器通过 bpf() 系统调用将解析后的对象文件注入内核
内核验证 BPF 指令,然后对其执行即时编译(JIT),返回程序的一个新文件描述符
利用文件描述符 attach 到内核子系统(例如网络子系统)
某些子系统还支持将 BPF 程序 offload 到硬件(例如网卡)。
0x4:库选型
| bcc | libbpf | ebpfgo | cilium eBPF | |
|---|---|---|---|---|
| https://github.com/iovisor/bcc | https://github.com/libbpf/libbpf | https://github.com/aquasecurity/libbpfgo | https://github.com/cilium/ebpf | |
| 优势 | 1.开发活跃 2.示例多 |
1.linux官方提供,可靠 2.支持CO-RE |
1.Go库,符合技术栈 2.支持CO-RE |
1.纯Go库,大厂背书 2.开发活跃 3.部分支持CO-RE |
| 缺点 | 1.需要在目标机器编译,对业务影响大 |
1.前端语言为C |
1.需要开启CGO |
1.对CO-RE支持的不全面 |
0x5:BTF & CO-RE
当eBPF被用来做信息收集功能时,就得和内核中各种结构体打交道,众所周知,linux内核改动一向比较随(keng)意(die),不会像windows那样还考虑兼容性,所以我们得自己解决不同内核版本直接字段不一致问题。
常规内核代码写法是通过宏定义来判断内核版本,在编译的时候走不同的代码分支,解决差异性,方法虽然不难,但是适配却非常费劲,当需要支持的内核版本多时,光是适配就得耗费大量精力。
static __always_inline u32 get_task_ns_pid(struct task_struct *task)
{
#if LINUX_VERSION_CODE < KERNEL_VERSION(4, 19, 0)
// kernel 4.14-4.18:
return task-> [PIDTYPE_PID].pid->numbers[task->nsproxy->pid_ns_for_children->level].nr;
#else
// kernel 4.19 onwards:
return task->thread_pid->numbers[task->nsproxy->pid_ns_for_children->level].nr;
#endif
}
这也就是BTF出现之前的很长一段时间里, bcc + clang + llvm 被人们诟病的地方,程序在运行的时候,才进行编译,目标机器还得安装clang llvm kernel-header头文件,同时编译也会消耗大量cpu资源,这在某些高负载机器上是不能被接受的。
因此BTF & CO-RE横空出现,BTF可以理解为一种debug符号描述方式,此前传统方式debug信息会非常巨大,linux内核一般会关闭debug符号,btf的出现解决了这一问题,大幅度减少debug信息的大小,使得生产场景内核携带debug信息成为可能。
CO-RE正是基于这一技术开发的,原理类似于pe/elf结构中的重定位表,核心思想就是采用非硬编码形式对成员在结构中的偏移位置进行描述,解决不同版本间结构体差异性。
可喜的是通过运用这项技术,确实可以帮助开发者节省大量精力在版本适配上,但是这项技术目前还是在开发中,还有许多处理不了的场景,比如结构体成员被迁入子结构体中,这时候还是需要手动解决问题,BTF的开发者也写了一篇文章,讲解不同场景的处理方案 bpf-core-reference-guide
tips:目前cilium提供的eBPF库对CO-RE的支持也不全面,等待社区持续更新。
0x6:开发流程
考虑到自身业务技术栈,因此选用cilium提供的go库作为前端库,同时默认开启btf,增强程序可移植性。
开发环境:
Mac + Vscode(安装remote develop插件) 强烈推荐
ubuntu 20.10 server(5.8之后开启BTF的内核都可以)
OS:
建议安装最新5.16内核版本且开启BTF,不喜欢折腾就直接安装ubuntu20.10 server版本,默认开启了BTF
应用层:
无特殊要求,引入 github.com/cilium/ebpf 库即可。
内核层:
- 安装libbpf库
- 安装clang llvm
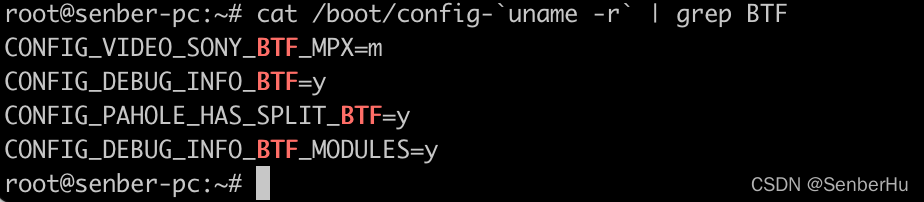
- 检查是否开启btf
cat /boot/config-uname -r| grep BTF 其中CONFIG_DEBUF_INFO_BTF开启即可,未开启则需要重新编译内核,开启BTF。
- 生成vmlinux.h文件(CO-RE)核心。
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h - 编写eBPF c代码
#include "vmlinux.h" //linux内核头文件大集合
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <bpf/bpf_core_read.h>
#include <bpf/bpf_tracing.h>
//包含这些头文件,就可以用CORE编程了
(这里没啥好说的,就和写内核代码一样,只是注意能用的函数比较少,同时如果遇到编译问题,请参考笔者踩坑记录【eBPF开发记录】)
- 使用bpf_printk进行代码调试即可
cat /sys/kernel/debug/tracing/trace_pipe 输出在这里 - 创建一个Makefile,核心就是用clang对上一个步骤的c文件进行编译即可。
方法一:手动编写,自主可控,实现
TARGETS := kern/sec_socket_connect
TARGETS += kern/tcp_set_state
TARGETS += kern/dns_lookup
TARGETS += kern/udp_lookup
# Generate file name-scheme based on TARGETS
KERN_SOURCES = ${TARGETS:=_kern.c}
KERN_OBJECTS = ${KERN_SOURCES:.c=.o}
LLC ?= llc
CLANG ?= clang
EXTRA_CFLAGS ?= -O2 -emit-llvm -g
linuxhdrs ?= /lib/modules/`uname -r`/build
LINUXINCLUDE = \
-I$(linuxhdrs)/arch/x86/include \
-I$(linuxhdrs)/arch/x86/include/generated \
-I$(linuxhdrs)/include \
-I$(linuxhdrs)/arch/x86/include/uapi \
-I$(linuxhdrs)/arch/x86/include/generated/uapi \
-I$(linuxhdrs)/include/uapi \
-I$(linuxhdrs)/include/generated/uapi \
-I/usr/include \
-I/home/cfc4n/download/linux-5.11.0/tools/lib
all: $(KERN_OBJECTS) build
@echo $(shell date)
.PHONY: clean
clean:
rm -rf kern/*.o
rm -rf user/bytecode/*.o
rm -rf network-monitoring
$(KERN_OBJECTS): %.o: %.c
$(CLANG) $(EXTRA_CFLAGS) \
$(LINUXINCLUDE) \
-include kern/chim_helpers.h \
-Wno-deprecated-declarations \
-Wno-gnu-variable-sized-type-not-at-end \
-Wno-pragma-once-outside-header \
-Wno-address-of-packed-member \
-Wno-unknown-warning-option \
-fno-unwind-tables \
-fno-asynchronous-unwind-tables \
-Wno-unused-value -Wno-pointer-sign -fno-stack-protector \
-c $< -o -|$(LLC) -march=bpf -filetype=obj -o $(subst kern/,user/bytecode/,$@)
build:
go build .
方法二:采用cilium提供的bpf2go库
- 在main.go中加入 //go:generate go run github.com/cilium/ebpf/cmd/bpf2go -cc clang ProcInfo src/procinfo.bpf.c -- -nostdinc -I/usr/include 这里面的ProcInfo是上一步c文件的名字,自己手动修改即可
- 编写如下makefile
all:
go generate
go build
clean:
-rm *_bpfe*.o
-rm *_bpfe*.go
-rm eBPF-*
0x7:新特性&内核要求

以下信息来自笔者查看Linux Kernel Release文档总结得出 Kernel Release Note
4.7 支持tracepoint
4.16 且 LLVM 6.0 不再使用宏always_inline 修饰函数,支持bpf程序调用非bpf程序
4.18 支持btf jit支持32位cpu
5.1 Add __sk_buff->sk, struct bpf_tcp_sock, BPF_FUNC_sk_fullsock and BPF_FUNC_tcp_sock | 增强btf能力 | 指令数量从4096提高到100w条
5.2 支持全局变量
5.3 支持有限for循环
5.5 Add probe_read_user, probe_read_kernel and probe_read_user_str, probe_read_kernel_str | 支持 BPF_CORE_READ
5.7 加入bpf-lsm框架 (selinux appamor)
5.8 加入CAP_BPF and CAP_PERFMON | 引入Ring buffer
5.10 支持尾调用(long jump)和普通函数调用(func call)混用
总结:内核组能支持的越新越好,如果能支持Ring buffer那就能解决数据乱序问题,且传输性能优于Perf Buffer。
0x8:eBPF限制
- 一个BPF程序的代码数量不能超过BPF_MAXINSNS (4K),它的总运行步数不能超过32K (4.9内核中这个值改成了96k);
- BPF代码只支持有限循环,这也是为了保证出错时不会出现死循环来hang死内核。一个BPF程序总的可能的分支数也被限制到1K;(支持有限循环)
- 为了限制它的作用域,BPF代码不能访问全局变量,只能访问局部变量。一个BPF程序只有512字节的堆栈。在开始时会传入一个ctx指针,BPF程序的数据访问就被限制在ctx变量和堆栈局部变量中;
- 如果BPF需要访问全局变量,它只能访问BPF map对象。BPF map对象是同时能被用户态、BPF程序、内核态共同访问的,BPF对map的访问通过helper function来实现;
- 旧版本BPF代码中不支持BPF对BPF函数的调用,所以所有的BPF函数必须声明成always_inline。在Linux内核4.16和LLVM 6.0以后,才支持BPF to BPF Calls;
- BPF虽然不能函数调用,但是它可以使用Tail Call机制从一个BPF程序直接跳转到另一个BPF程序。它需要通过BPF_MAP_TYPE_PROG_ARRAY类型的map来知道另一个BPF程序的指针。这种跳转的次数也是有限制的,32次(8k栈空间)
- 内核还可以通过一些额外的手段来加固BPF的安全性(Hardening)。主要包括:把BPF代码映像和JIT代码映像的page都锁成只读,JIT编译时把常量致盲(constant blinding),以及对bpf()系统调用的权限限制;
0x9:Perf Buffer & Ring Buffer
Perf Buffer
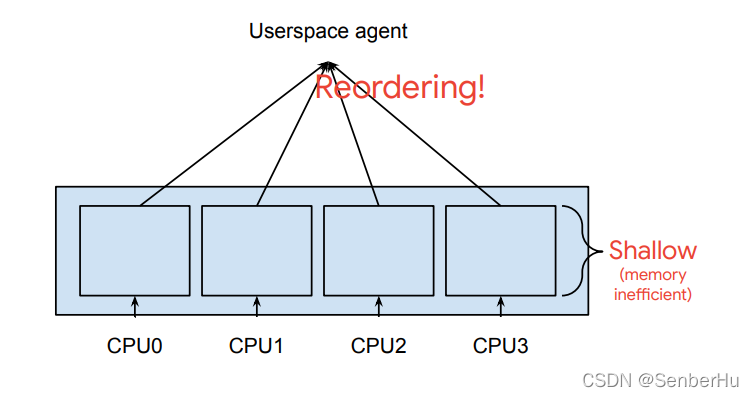
Ring Buffer
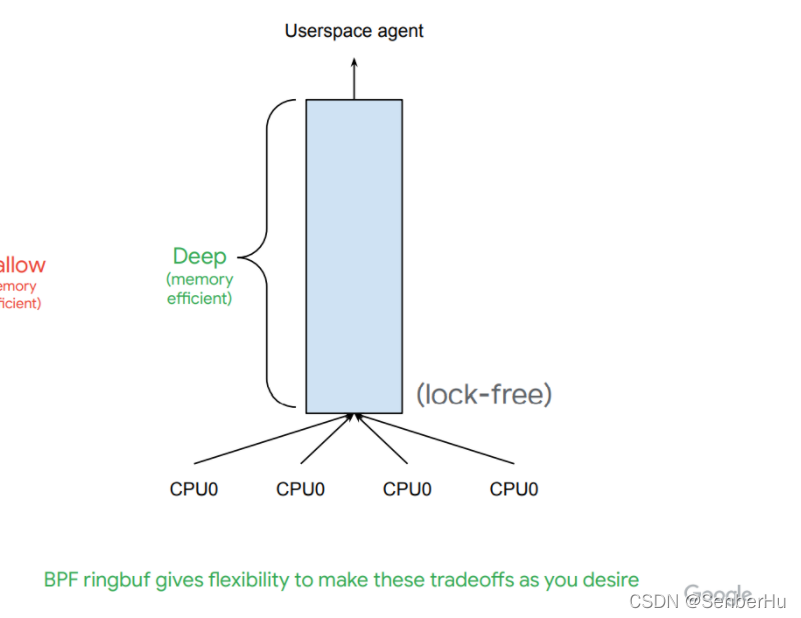
总结:
共同点:
- Perf/Ring Buffer相对于其他种类map(被动轮询)来说,提供专用api,通知应用层事件就绪,减少cpu消耗,提高性能。
- 采用共享内存,节省复制数据开销。
- Perf/Ring Buffer支持传入可变长结构。
差异: - Perf Buffer每个CPU核心一个缓存区,不保证数据顺序(fork exec exit),会对我们应用层消费数据造成影响。Ring Buffer多CPU共用一个缓存区且内部实现了自旋锁,保证数据顺序。
- Perf Buffer有着两次数据拷贝动作,当空间不足时,效率低下。 Ring Buffer采用先申请内存,再操作形式,提高效率。
- perfbuf 的 buffer size 是在用户态定义的,而 ringbuf 的 size 是在 bpf 程序中预定义的。
- max_entries 的语义, perfbuf 是 buffer 数量(社区推荐设置为cpu个数),ringbuf 中是单个 buffer 的 size。
- Ring Buffer性能强于Perf Buffer。参考patch 【ringbuf perfbuf 性能对比】
Perf/Ring Buffer用法请参考另一篇km【Perf/Ring buffer用法 & 性能对比】
0x10:eBPF配置
1.加固
/proc/sys/net/core/bpf_jit_harden 设置为 1 会为非特权用户( unprivileged users)的 JIT 编译做一些额外的加固工作。比如常量致盲,损失部分性能。
2.限制系统调用
/proc/sys/kernel/unprivileged_bpf_disabled 设置为1会禁止非特权用户使用 bpf(2) 系统调用,将它设为 1,就没有办法再改为 0 了,除非重启内核。一旦设置为 1 之后,只有初始命名空间中有 CAP_SYS_ADMIN 特权的进程才可以调用 bpf(2) 系统调用 。 Cilium 启动后也会将这个配置项设为 1
3.eBPF需要开启的编译参数(不包含BTF相关)
CONFIG_CGROUP_BPF=y
CONFIG_BPF=y
CONFIG_BPF_SYSCALL=y
CONFIG_NET_SCH_INGRESS=m
CONFIG_NET_CLS_BPF=m
CONFIG_NET_CLS_ACT=y
CONFIG_BPF_JIT=y
CONFIG_LWTUNNEL_BPF=y
CONFIG_HAVE_EBPF_JIT=y
CONFIG_BPF_EVENTS=y
CONFIG_TEST_BPF=m
本文由博客一文多发平台 OpenWrite 发布!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号