
使用selesium和pytesseract识别验证码,达到登录网页目的
2017-10-11 16:15 yongchin 阅读(675) 评论(1) 收藏 举报关于验证码问题,大多可以在网上了解到目前有四种解决方案:
1、开发注释验证码
2、开发开一个“后门”,设置一个万能码,输入万能码则通过
3、通过cookies绕过验证码
4、图形识别技术
前三种是比较快速也是比较简单的,如果条件允许或者跟开发沟通得当,尽量用前三种
下面来说一下本文的重点也就是第四种方法,我们采用selesium自动化工具和pytesseract模块在前端来实现(也可以在爬虫实现,用requests,urllib等,主要就是pytesseract的图形识别技术)
首先pytesseract依赖PIL、Tesseract
所以请先下好,PIL是python的图像处理库,Tesseract是谷爹的OCR识别引擎,关于PIL和Tesseract资料有很多,如果感兴趣,请自行百度了解,这里不再赘述。
当以上东西都安装好后,最后再执行pip install pytesseract安装我们的主力pytesseract
![]()
下面直接上代码,我是用自己公司的页面来进行测试的:
# /usr/bin/python # coding=utf-8 import pytesseract from PIL import Image from selenium import webdriver import time def getcode(imgurl): """识别图片""" image = Image.open(imgurl) vcode = pytesseract.image_to_string(image) return vcode def imgprocess(imgurl): """截图处理""" img = Image.open(imgurl) region = (516, 373, 614, 422) cropImg = img.crop(region) # 切割图片 cropImg.save(imgurl) chromepath = 'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe' browser = webdriver.Chrome(chromepath) browser.get('http://192.168.6.52:8090/') time.sleep(2) # 等待验证码加载完成 temp_img = 'C:\Users\YangQ\Desktop\getImg.png' # 图片存放位置 browser.get_screenshot_as_file(temp_img) # 截图 imgprocess(temp_img) code = getcode(temp_img) browser.find_element_by_name("authCode").send_keys(code)
解释一下,因为session关系,目前我想到的方法就是通过selesium截屏来抠出验证码进行分析识别。如果有更好的方法,以后我会更新
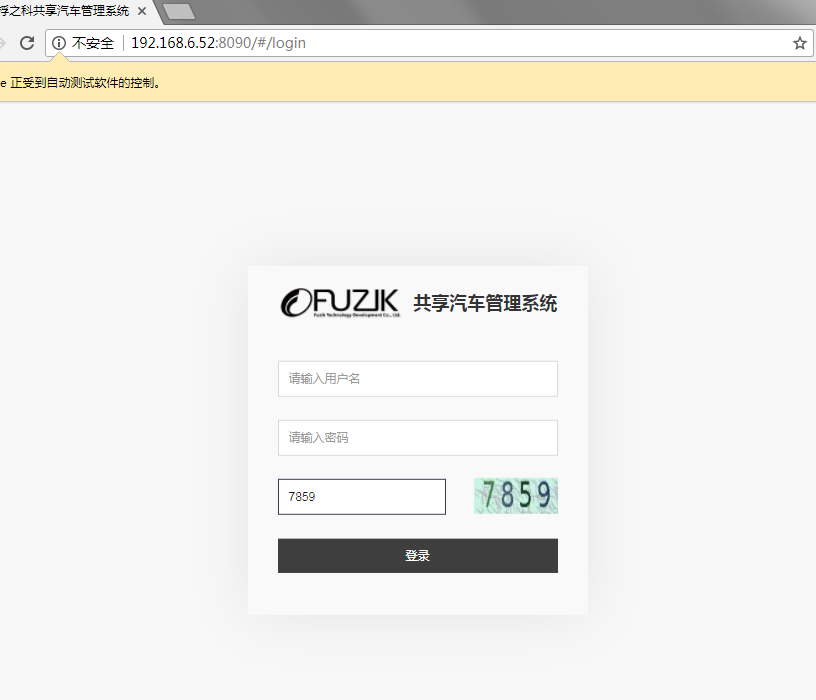
可以看到当程序执行后,成功识别到验证码并填写正确。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号