mysql 设计规范
摘要
在我们的日常研发工作中,数据库表的设计是必不可少的。如何设计数据库表之间的关系也就决定着我们的代码业务如何写。如何设计数据库表也是我们需要掌握的技能之一。表如何设计字段的命名,数据类型,长度,索引的建立等都会对我们的代码开发,性能上带来影响,并且如果一个表毫无规范的去设计,还会被后面接手的程序员疯狂吐槽,后面的话大概先讲字段的命名,数据类型,长度怎样去设定,索引的建立原则,数据库SQL开发规范
数据库字段设计规范
1. 字段都必须采用小写字母并用下划线分割
2. 字段的命名尽量不要使用mysql保留的关键字
如果一定需要的话,使用的时候记得加上单引号括起来,还有就是像有些字段叫名字,我们一般定义成英文名name,我建议加上一个前缀便于区分,比如用户名定义成user_name,如果是企业的名字就定义成company_name,这样的话我们在单表或者联表查询的时候能够做到很好的区分,没必要担心这个表的叫name,而那个表叫company_name,全部做到统一
3. 主键建议一并采用id去命名,并且数据类型采用bigint去声明
因为这样能够方便我们去查询时,主键都是id,没必要再反过来看一下表的主键命名成什么样的了,如果是其它表引用表的主键,那么就给引用的字段加上一个前缀,就比如用户表引入了企业表的主键id,那么用户表的字段应该声明成company_id,这样就能明白这里是引用了company表的主键id
4. 整型数据类型的考虑,优先考虑符合存储需要的最小的数据类型,也就是能用tinyint类型达到存储要求的,不用int去储存
平常我们的表中常常会存在status,type这样的字段,而这种字段往往取值就是1,2,3这样的,对于这样的字段我们就完全可以声明成tinyint数据类型就能满足我们的需求,因为tinyint所占的字节最小。下面我们来看一张具体整型数据的对比图
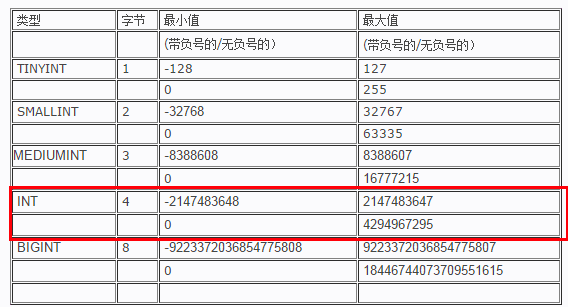
图中我们可以看到tinyint、smallint、mediumint、int、bigint所占的字节,所表示的范围,在这里很重要的一点就是:在我们选择这些数据类型的时候,其实他们所能储存的范围就已经确定了,跟我们后面所声明的长度是没有关系的

我们可以看到即使我讲status中的tinyint长度声明成1,但是它还是可以储存它的最大值127,所以后面声明的长度是跟储存长度是没有关系的,选择完数据类型后,能储存的范围也就确定了,而后面我们所声明的长度所表示的是显示长度,也就是我们去查看的时候,如果储存的数据长度没有达到我们所声明的显示长度,那么前面就会用0进行填补
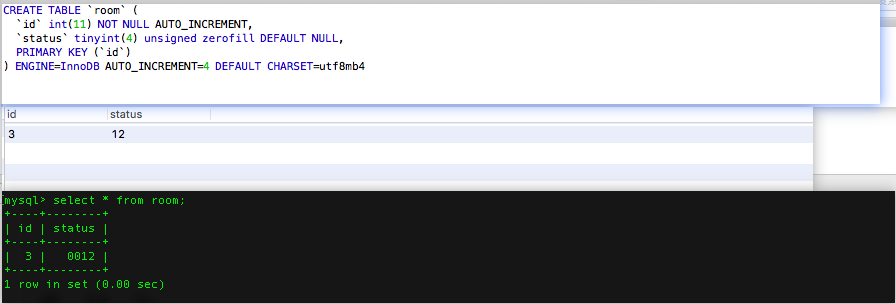
我们看到tinyint的显示长度被声明成4,但是储存的数据是12,没有达到显示的长度,所以前面会以0填充。如果想到看到这种效果则需要打开填充0的按钮,并且在navicat工具是看不到效果的,还有一种情况就是如果储存数据长度大于显示声明的长度,这个将不会收到影响,还是显示储存数据的长度
5. 如果能确定数值是没有负数的情况下,尽量将无符号钩上,也就是unsigned
前面我们看到一张整型范围表示图,其中就有有符号和无符号的范围区别,当我们将无符号钩选上,那么我们整数最大值所能表示的范围将是之前的2倍。这个虽然看起来好像对我们的程序会没什么太大的影响,还是需要养成一个良好的习惯
6. 字符串的char,varchar,text数据类型的选择
我们都知道char是固定长度的字符串,即使存储的数据没有达到所声明的长度,char还是会用空格进行填充,char一般来说也用的不是很多,如果有场景是字段的长度是固定比如年月202007这样的,那么可以将类型定义成char(6)。varchar类型是我们使用到最多的数据类型,它是char不同的是,储存的数据长度没有达到声明的长度,varchar也不会用空格进行填充,varchar(100)中的100表示最多储存100个字符,而不是字节数,当varchar达到万级别的长度时,并且一定要使用text数据类型进行储存,那么我们才考虑使用text数据长文本进行储存了,否则一般也不太使用到text数据类型,因为text数据对我们的性能会造成很大的影响,下一小节讲
7. 表中避免使用Text,Blob这样的数据类型,最常见的Text类型可以储存64K的数据
像Text,Blob这样的大数据类型,所对我们的表所占空间产生最大的影响,像一个表中如果声明了Text类型的字段,这个表有了几万的数据,这个表的所占的空间就会在几百兆之间,这个表后面再新增一些数据的话,那么就会导致这个表所占的空间越来越巨大,会对我们的查询产生巨大的影响。如果一定要使用这种大数据类型的话,建议把Text或者Blob这样的数据类型用单独的表进行储存,这样的话只有真正需要这些字段才会去单独的表查询,不会对查询其它字段产生影响
8. 与金额相关的数据类型一定要使用decimal类型
非精准浮点类型:float,double。如果用float和double去修饰金额的话,将会造成精度的缺失,在金额的计算方面,所造成的影响将会是不可原谅的。而Decimal类型为精准浮点数,在计算时不会丢失精度,占用的空间由定义的宽度决定
数据库表基本设计规范
1. 所有表的储存引擎尽量使用Innodb引擎
我们所建立的表应尽量采用Innodb引擎,除非有特殊情况要采用其它的储存引擎。mysql5.6以后默认使用的是Innodb引擎,但是在mysql5.5之前默认使用Myisam引擎。Innodb储存引擎支持事务,行级锁,支持崩溃恢复,高并发下性能更好
2. 数据表和字段的字符集统一使用utf8mb4, 排序规则采用utf8mb4_general_ci
都采用统一的编码集,可以避免由于字符集转换产生的乱码,不同的字符集字段之间进行连接查询会导致索引失效。之前字符集是建议我们采用utf8,但是utf8只能保存最多3个字节长度的utf-8字符,这种情形能满足我们大部分的文本存储,但是utf8字符集无法储存Emoji 表情(Emoji 是一种特殊的 Unicode 编码),因为emoji表情占到了4个字节,如果要储存emoji表情,就需要使用utf8mb4字符集。而utf8mb4又是utf8的超集。一开始声明为utf8mb4字符集,可以编码后面有emoji表情存入需要更新编码集,而排序规则采用utf8mb4_general_ci,因为utf8mb4_general_ci速度比较快
3. 所有表和字段必须要加上注释
相信这点是毋庸置疑的,这个是设计表和字段最基本的要求
4. 尽量控制单表的数据量大小在500万以内
mysql官方建议单表的数据量是控制在1千万以内,我们对表的数据量控制在500万以内的话对表的性能还能说的过去,如果一旦超过了500万以上的数据量对表的查询,修改表结构,备份和恢复都会有很大的问题
5. 尽量给表多添加两列create_date,update_date
可能有网友觉得这显得会有些多余,但是这两列在有些场景下能够起到意想不到的作用。而create_date,update_date的默认值设置成CURRENT_TIMESTAMP当前时间戳,并且update_date设置根据当前时间戳更新
6. 禁止在表中存储图片,文件等大的二进制数据
之前在学校做过的项目就是把有些文件和图片的二进制流存储到表中,因为那些没接触过oss, cos等文件服务器。当我们把二进制流存储到表中,保存和转出是非常麻烦的一件事,大数据量对表也是一个很大的影响。现在都是采用专门的文件服务器去保存,而表保存url就行
索引设计规范
1. 限制每张表的索引数量,建议单张表的索引数量不超过5个
在日常开发中,还真有人将表中的每一列都建立一个索引。索引并不是越多越好,索引越多,那么就会导致表的性能低,空间占比大。所以索引即能够提升效率也能降低效率,要建立合适的索引
2. 禁止给每一列都建立索引,选择合适的列建立索引
选择合适的列建立索引,当某些列经常被用来做条件查询的,关联的,区分度高的,可以给它建立索引,像有些列就好比type, status这些列建立索引毫无用处,因为这种列取值就那么几种,无法做到很好的区分。想id这种就有很大的区分度。如果一个表引用了其它表的主键,那么也适当的给这个列建立索引,因为这个列会被常用来做连接查询
3. 每个Innodb表必须建立一个自增的主键
尽量采用自增的id作为主键,不要使用UUID、MD5、HASH、字符串列作为主键(无法保证数据的顺序增长)
4. 索引类型尽量选择B +树
Innodb存储引擎提供了两种索引类型:B+和hash索引,hash索引其实跟Java里面的HashMap类似,采用hash表实现,访问度能达到O(1),但是hash索引的缺点就是无法支持范围查询,like的"xx%"索引查询。一旦我们查询条件中出现>= <这样的范围查询,那么hash索引就无法起到效果。而B+树能够支持,所以索引类型的建立尽量采用B+树索引
5. 避免建立冗余索引和重复索引
当我们建立联合索引时,要避免再建立冗余索引,而使用联合索引时,要注意最左匹配原则,条件一定要使用到最左边那一列,否则联合索引将不起效果。而联合索引最左边那一列应该是区分度高,使用最频繁的,字段长度尽量小的那一列。当一列被建立在联合索引的最左边时,没必要再给这一列建立单独的索引了,避免创建冗余索引
数据库SQL开发规范
1. 禁止使用select * from tables这样的查询语句
如果tables表中存在几百万数据,那么后果是很可怕的。还有一个问题就是查询字段使用了select *,这样会消耗更多的CPU和IO以网络带宽资源,应该采用SELECT <字段列表> 查询这样可以减少表结构变更带来的影响
2. 避免数据类型的隐式转换
隐式转换会导致索引失效。如:select name,phone from customer where id = '111';
3. 充分利用表中建立的索引
像sql语句中的like查询,如果条件是"%xxx%",这样将会导致索引失效,应该改为"xxx%"。使用联合索引时,要使用到联合索引的最左一列
4. 尽量避免使用子查询,将子查询优化成join操作
子查询的结果集将产生临时表,而临时表没有索引,所以查询性能会收到影响。对于返回结果集比较大的子查询,其对查询性能的影响也就越大
5. 禁止在索引上使用函数对列进行转换
对列进行函数转换或计算时会导致无法使用索引
6. 连接查询时尽量采用小表驱动大表,也就是左边是小表,右边是大表
7. 禁止大批量的数据一次性插入,应该分批次进行
总结
上面列举的一些规范并不代表着一定要按照这种规范来做,这只是自己平时开发设计时采用的一些意见而已,可能有些网友会不太认同,网友可以根据自己具体的业务需求去定义。只是数据库表的设计体现了一个开发人员的基本功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号