MVCC 多版本并发控制
引言
MVCC全称为Multiversion concurrency control多版本并发控制,我们清楚Mysql的默认隔离级别是可重复读,而Mysql实现可重复读就是使用的MVCC多版本并发控制,通过每条数据的版本号(也可以叫做事务id)来实现不同事务之间的并发访问,有点类似乐观锁,并不需要对每条数据都加锁,而是通过版本号去控制。
脏读、不可重复读、幻读
在数据库事务的并发访问中,可能就会带来脏读、不可重复读、幻读等问题。
脏读
脏读就是指读到别人未提交的事务,也就是别人修改了数据,但是没有进行事务提交,而自己能够读到别人修改过的数据
举个例子:假设有两个人A,B,
1.首先B修改了A的账户余额由1000元修改成2000元,但是并没有提交
2.此时A去读取自己的账户余额,发现变成了2000元,非常高兴
3.之后B发现自己修改的余额有问题,又将事务进行回滚,那么A账户的余额又变成1000元。
以上,步骤2中A读取的2000元就是脏数据,读到了别人还没有提交的数据
不可重复读
不可重复读是指在同一个事务中,多次读取同一数据的结果不一样。
举个例子:
1.在事务1中,A账户读取到自己的账户余额为1000元
2.在事务2中,B将A账户的余额由1000元修改成2000元并提交事务
3.还是在事务1中,A账户再次去读取自己的账户余额变成了2000元
以上,在同一个事务中,A账户两次去读同一批数据,发现读到的结果不一样,这就发生了不可重复读
幻读
幻读是指一个事务对表中的数据进行了修改,同时,第二个事务新增了一条数据。那么此时,第一个事务去查发现自己表中还有没有修改的数据行,也就是第二个事务新增的那条数据没有被修改,出现了幻觉一样
举个例子:
1.在事务1中,读取到所有员工的工资为1000元,有10条数据
2.事务1,并对10条数据进行修改,修改成2000元。此时,事务2新增一个员工信息,工资为1000元并提交
3.此时事务1中,读到所有员工的工资,会发现有10条工资为2000元的,一条工资还是1000元的
以上,明明自己修改了所有的数据,但是发现新增一条没有被修改,出现幻觉一样
有人会觉得不可重复读和幻读有点类似,但是不可重复读强调的是修改操作,也就是别人修改了数据,导致自己两次读出来的结果不一样,而幻读则强调的是数据的新增或删除操作,也就是第 1 次和第 2 次读出来的记录数不一样
事务隔离级别
为了解决上面所提到的脏读、不可重复读、幻读问题,Mysql提供了四种隔离级别:读未提交(Read uncommit), 读已提交(Read commit)、可重复读(Repeatable Read)、串行化(Serializable)
读未提交(Read uncommit)
该隔离级别,并没有解决任何问题,是指即使事务修改了数据,没有进行提交,其他事务也能查看得到,这样的话就会读到脏数据,
读已提交(Read commit)
该隔离级别,能保证我们读到的数据都是已经提交的数据,未提交的数据读不到,但是这样虽然能解决脏读问题,但是会引起不可重复读。在同一个事务中,第一次去读同一数据,过一会儿,其他事务修改这批数据并提交事务,这时候我们再去读同一数据,发现结果已经不一样了,就是两次读取的结果不同,这种现象称之为不可重复读
可重复读(Repeatable Read)
可重复读能保证在同一个事务中,多次查询同一数据结果一样。也就是解决了不可重复读,但是无法解决幻读。后面再详细讲解Mysql是怎么实现可重复读的,怎样解决不可重复读,为什么不能解决幻读??
串行化(Serializable)
串行化跟它的名字一样,每个事务将会被串行执行,也就不存在在自己的事务中,数据被其他事务所影响,因为同一时刻只有一个事务在执行,虽然这样,脏读、不可重复读、幻读问题都能得到解决,但是会严重降低执行效率,所以这种隔离级别很少别采用
我们可以看到,四个隔离级别在解决问题是依次递进的,而Mysql默认采用的隔离级别是可重复读,下一节来重点分析下Mysql是怎样利用MVCC机制实现可重复读的
MVCC 多版本并发控制
通常我们在并发的场景中,有时候读操作会读到写操作还没完全写完的数据,也就会出现数据不一致问题,碰到这种场景,我们通常会想到通过加锁操作来解决,来读操作必须等待写操作完全写完后再能读取数据,通过加锁操作确实能够得到解决,但是加锁操作所带来的效率问题将不是很高。而MVCC机制使用了一种不同的手段,通过给每条记录加上版本号,来控制读写的并发执行。

首先看一下图中有一条记录,后面三列是InnoDB的内部实现中为每一行数据增加了三个隐藏列用于实现MVCC,其中跟MVCC版本控制有关的是DB_TRX_ID和DB_ROLL_PTR两列
DB_TRX_ID:数据行的创建版本号,也可以叫做系统事务编号
DB_ROLL_PTR:数据行的删除版本号,里面包括回滚指针,需要通过该指针找到历史数据
DB_ROW_ID:行标识(隐藏单调自增id)
下面通过几个事务中的sql来讲解MVCC是怎么通过版本号来实现可重复读的。注意一点:begin/start transaction命令并不是事务的起点,这时候还不会向Mysql申请事务id,只有执行了第一个sql语句,才会向mysql申请事务id,mysql内部也是按照事务的启动顺序来分配事务id的

假设数据库的初始数据是这条,后面两个null依次为创建版本号,删除版本号(回滚指针)
当执行查询sql时会生成一致性视图read-view(可以成为快照),这个视图由所有查询时已经开启了事务但是没有进行提交(未提交)的事务id数组(数组里最小的taxId为min_id)和已经创建的最大事务taxId(max_id)组成,有了这个视图我们可以再根据undo日志中的数据跟视图做比对得到符合条件的数据,最后得出来的结果就是我们sql查询的结果

每次执行sql查询就会生成如上图一样的一致性视图,
假设在当前事务sql执行查询时,前面已经开启了2个事务,2个事务都未进行提交,并且它们的编号分别是100,200. 当前事务编号为300,这时min_id为100,因为min_id=100(未提交的事务id中的最小的一个事务id),而max_id=300(已经创建的事务中最大的一个事务id,不管是已经提交过的还是未提交的都算,最大的事务id),那么生成的read-view视图为:[100, 200, 300] ,[100, 200, 300]所组成的数组所表示的是图中红色的部分
假设还是两个事务,编号不变,其中编号为100的事务已经提交,而200的事务未提交,那么min_id=200(因为min_id是未提交的最小事务id),max_id=300(还是不变),这样生成的read-view:100 [200, 300],100所表示的就是绿色的部分,已提交的事务,因为小于min_id,而[200, 300]所组成的数组所表示的中间红色的部分
假设还是两个事务,编号不变,而现在是编号为200的事务已经提交,而100的事务未提交,那么min_id=100,max_id=300,所组成的read-view: [100, 300] 200,
[100, 300]所组成的数组是未提交的事务,而200是已提交的事务,[100, 300] 200所表示的就是中间红色的部分,即包括未提交事务,也包括提交事务
版本比对规则:
1. 如果数据的创建版本号tax_id<min_id的话,也就是落在绿色部分,表示这个数据就是已经被提交的数据,那么这个数据是对其它事务是可见的。
2. 如果落在黄色部分(tax_id>max_id),表示这个版本是未开始事务的,这个是不太可能的,是肯定不可见的
3. 如果落在红色部分(min_id<=tax_id<=max_id),那么包括两种情况
a: 如果查找的row的tax_id在min_id和max_id组成的数组中,表示这个版本是由还没提交的事务生成的,对其它事务来说是不可见的,当是对产生这条数据row的事务tax_id是可见的
b:如果查找的row的tax_id不在数组中,则表示这个row的版本是已经提交的版本,是对其它事务可见的
版本规则的比对非常重要,当我们掌握了版本的规则比对,那么只要拿着undo中的数据日志,跟一致性视图去比对,按照规则进行筛选进行
还需要注意一点的就是:在同一个事务中,后面的sql语句查询都会复用事务第一次执行的查询sql所创建的一致性视图read-view,这样的话就能保证后面的sql语句跟第一次查询的sql语句查出来的结果一致,保证可重复读
下面通过几个例子来加深一下:
假设有四个事务A,B,C,编号分别为100,200,300。
事务A首先开启事务,并执行update user set age = 100 where id = 1, 并不进行提交事务,那么事务A产生的undo日志为
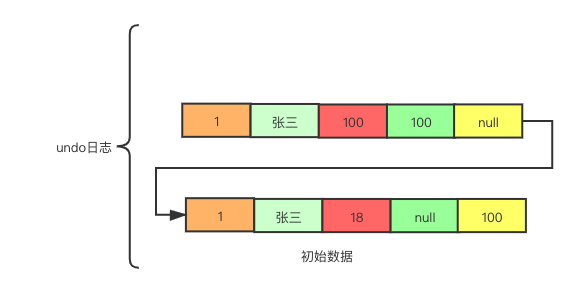
最低下一条是初始数据,而上面一条执行了update语句会复制出一条,创建的版本号为该事务A的事务编号100,删除版本号中的回滚指针则指向历史数据,而初始数据的删除版本号则表示删除该数据的事务id,也就是100。注意一点:在undo日志中update语句是会复制一条新数据,并不会直接在原数据上做修改,而原数据则表示删除,具有删除版本号
接下来事务B也进行update语句,update user set age = 200 where id = 1,但是跟事务A不同的是,事务B进行事务提交,所产生的undo日志:
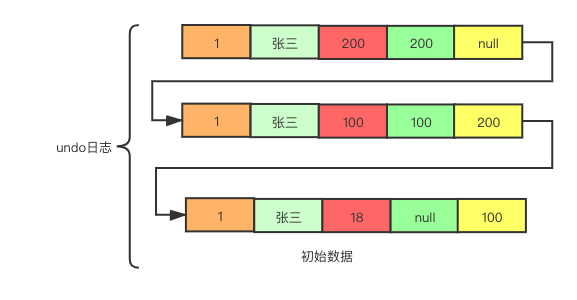
可以看到事务B产生了最新的一条数据,age被修改成了200,并且该row的事务tax_id为200.
最后,事务C执行select语句,这里有两种情况,如果事务C执行select语句是在事务B提交之后执行,那么事务C所产生的一致性视图read-view那么就会是:[100, 300] 200,min_id=100是事务A未进行提交,最小未提交的事务id。max_id=300是所创建的最大事务id,也就是事务C的tax_id。我们看一下事务C执行select * from user where id = 1会找到undo日志中哪一条数据。首先MVCC会从undo中的最新一条记录开始比对,最新一条数据是age=200,tax_id=200,根据版本比对规则,发现tax_id落在一致性视图中的[100, 300]区间内,但是tax_id=200并不在min_id和max_id所组建的数组中,[100, 300]不包括200,根据规则3中的b,说明这条数据是对其它事务可见,那么就会返回age=200这条数据
前面我们分析的是事务C执行select语句是在事务Bcommit提交后,假设一下如果事务C执行select语句是在事务B执行update语句之后,commit之前,那么事务C所产生的一致性视图就会不同了,read-view: [100, 200, 300],min_id=100, max_id=300, 首先MVCC还是从undo日志中查找到最新的,age=200,tax_id=200的数据row,发现row的tax_id落在了区间[100, 200, 300]中,并且200在该数组中,那么根据规则3中的a,表示这个版本是对其它事务不可见的,后面接下来查找到age=100, tax_id=100。发现还是在区间[100, 200, 300]中,并且100在该数组中,也是不可见的,最后就会找到初始数据,初始数据的tax_id是要小于100的,根据规则1,落在绿色部分,是已提交的数据。如果事务B在事务C执行select语句后,执行了commit操作,也就是事务编号200进行了提交,理论上产生的一致性视图read-view为[100, 300] 200,但是前面我们讲过,在同一个事务中,后续的select语句会复用第一个select语句所产生的read-view,也就是事务C的read-view还是[100, 200, 300]这样就保证后续执行select语句结果还是一样,如果read-view变成了[100, 300] 200那么所查询出来的结果肯定是不一样的,也就是没有保证可重复读
上面我只是列举了一个简单的例子,来讲解MVCC通过版本号控制事务中数据的读写。网友可以列举一些复杂的例子来进行验证,通过上面的版本比对规则,看是否满足我们的猜想
MVCC机制只能解决可重复读问题,不能完全的解决幻读问题,为什么不能完全解决幻读问题,首先mysql中分为快照读和当前读,快照读也就是我们所执行的select语句,MVCC机制能够解决select快照读的幻读。当前读是指我们所执行的update, delete, insert语句,假设要update一条记录,但是在另一个事务中已经delete掉这条数据并且commit了,如果update就会产生冲突,所以在update的时候需要知道最新的数据。所以update也会把最新数据也更新掉
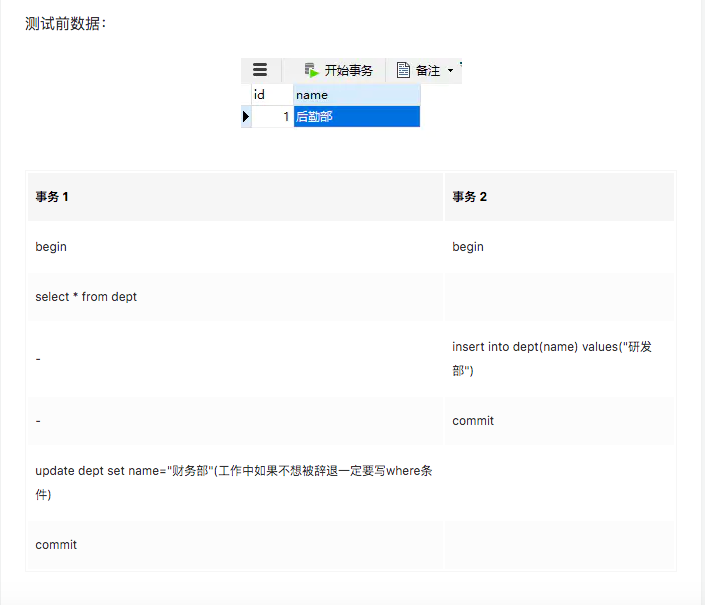
我们希望的结果是事务1只需要将后勤部更新为财务部就行,但是结果却是:研发部也会被我们更新为财务部,两条数据都被修改了。这种结果告诉我们其实在MySQL可重复读的隔离级别中并不是完全解决了幻读的问题,而是解决了读数据情况下的幻读问题。而对于修改的操作依旧存在幻读问题,就是说MVCC对于幻读的解决时不彻底的。
如何解决幻读
如果需要彻底解决幻读的话,也有两个办法:
1. 一个是使用串行化隔离级别
2. MVCC+next-key locks:next-key locks由record locks(索引加锁) 和 gap locks(间隙锁,每次锁住的不光是需要使用的数据,还会锁住这些数据附近的数据)
实际上很多的项目中是不会使用到上面的两种方法的,串行化读的性能太差,而且其实幻读很多时候是我们完全可以接受的
总结
前面大概讲述了事务并发执行所带来的问题,mysql为了解决这些问题所设置的隔离级别,默认隔离级别是可重复读,重点讲解了MVCC机制,怎样通过版本去实现可重复读的,一致性快照。最后列举了一下幻读

 浙公网安备 33010602011771号
浙公网安备 33010602011771号