volatile实现原理
在Java中我们都知道synchronized是一个重量级的锁,尽管JVM对synchronized关键字做出了许多优化,但是在多线程的情况下,synchronized的并发效率还是低下,而volatile是synchronized的轻量级的实现,在多线程编程中,能用volatile关键字解决的问题不用synchronized去解决。
如果要讲volatile的实现原理,必须要从两个两个方面进行分析,一个是可见性(跟Java内存模型有关),另外一个是有序性(跟指令重排序有关)
在Java并发编程中,存在三大特性:原子性,可见性,有序性
原子性
这里的原子性其实跟我们数据库中的原子性有点类似,表示所有的操作要么全部执行,全部不执行。我们来看一个操作i++,表面上看就是一个自增操作,其实里面包含了三个指令操作,先从内存中read读操作,再+1赋值(assign)操作,最后写(write)操作写回内存中,原子性指这三个操作要么全部执行,要么全部不执行。
可见性
在内存中,线程A修改了共享变量的值,那么线程B能够立即得知这个共享变量的修改,能够获得最新的值,这就表示对其他线程是可见的。
有序性
程序按照我们所编码的先后顺序执行这就叫做有序性。但是,在JVM中,存在一种指令优化的技术即指令重排序技术,会使得程序不一定按照代码的顺序执行。比如:int a = 1; int b = 2; int c = a + b;那么int a = 1一定会在int b = 2;代码前执行吗,不一定,因为JVM认为a先执行和b先执行对线程结果没有影响,会存在指令优化,所以可能会是b先执行,但是c一定是在a和b的执行后面。
volatile保证了三大特性中的可见性,有序性。但是不保证其原子性,还是会存在并发问题。
我们先看volatile如何解决可见性问题,看一张Java内存模型图:

主内存:堆区 + 方法区。存放共享变量的地方,每次线程需要读取共享变量的值都会先从主内存中读取。
总线:也就是负责主内存和CPU之间的数据传输工作,就是我们拆开主机后备箱一根一根线。
工作内存:虚拟机栈。每个线程执行时,都会创建一个属于自己的工作内存,每次从主内存读取共享变量,便会放到自己的工作内存创建一个工作副本,线程对变量进行了修改,修改的也是自己工作内存中的变量副本,并不会立即同步到主内存中。
我们再来看一下主内存,总线,CPU之间的一个数据交互图:
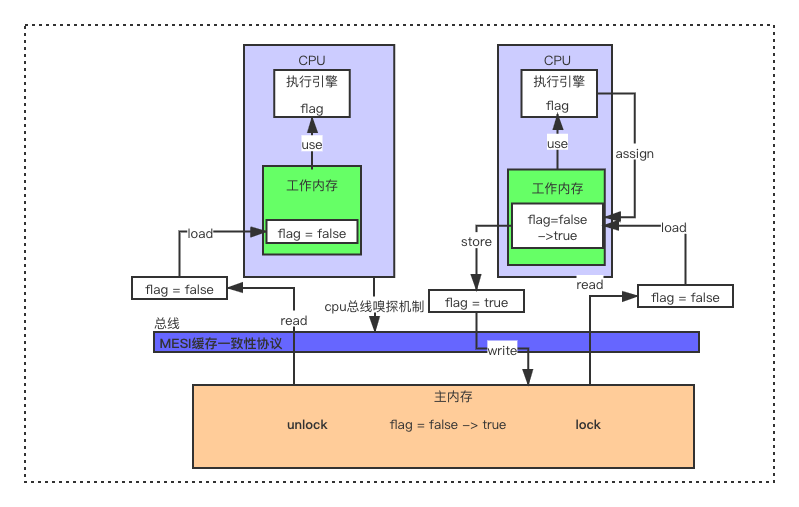
首先主内存中存在一个共享变量:flag = false;
(1).然后图上面有两个CPU表示有两个线程都从主内存中进行read操作,read操作表示把主内存中的值传输到线程的工作内存中,以便后续的load操作。
(2).read操作过后,load(载入)操作把read操作读取到的主内存变量值放入工作内存的变量副本。
(3).这时工作内存中已经存在变量副本,可以进行use(使用)操作了,use操作将工作内存变量值传递给执行引擎,给执行引擎进行使用。
(4).执行引擎修改了变量值后,需要通过assign(赋值)操作将修改后的值赋值给工作内存的变量副本。
(5).这是工作变量副本已经被修改,通过store(存储)操作将工作内存变量的值传送到主内存中,以便后续的write操作使用。
(6).store操作过后,write(写入)操作将store操作得到的变量值写入到主内存的变量中
以上(1)~(6)操作是主内存,工作内存之间的数据交互步骤。图中的右边的CPU修改了flag的值,并写入了主内存中,左边的CPU是如何读取到修改后的值了。
我们可以看到左边的CPU有一个箭头叫做cpu总线嗅探机制,也就是监听着总线上的数据变化,这个箭头是变量加了volatile修饰才有的。其实有很多都会采用这种监听机制来监控数据的变化,像我们的zookeeper注册中心,客户端都会有一个线程去监听注册中心上服务的变化。
当右边的CPU发现write操作,这时cpu总线嗅探机制便会感觉到数据发现变化,会使自己的工作内存中的变量副本失效,重新从主内存中读取。这就保证了变量的可见性,一个线程修改了共享变量,对其他线程是可见的。
这里又有个小问题,细心的网友会发现如果左边的CPU重新读操作在右边的CPU写操作前面,那左边的CPU又会读到旧值。其实不会,看我们图中有个lock(锁定操作)表示一个变量被一个线程所独占。也就是我们右边的CPU去write操作时,左边的cpu并不能进行读取。直到unlock(解锁)操作
下面再来看下volatile是如何解决特性中的有序性问题
首先用volatile修饰的变量会禁止指令重排序优化,也就是会在指令加一层内存屏障,指令排序时不能把后面的指令排序到内存屏障之前的位置,也就是禁止了指令的重排序。
首先看几个语义:
as-if-serial: 单线程运行下不允许改变执行结果
happens-before: 如果线程B的执行结果会影响到线程A的执行结果,那么线程B和线程A之间就存在happens-before原则,线程B happens-before 线程A
我们首先看一张加和没加volatile关键字变量生成的字节码:
加了volatile关键字生成的字节码

没加volatile关键字生成的字节码
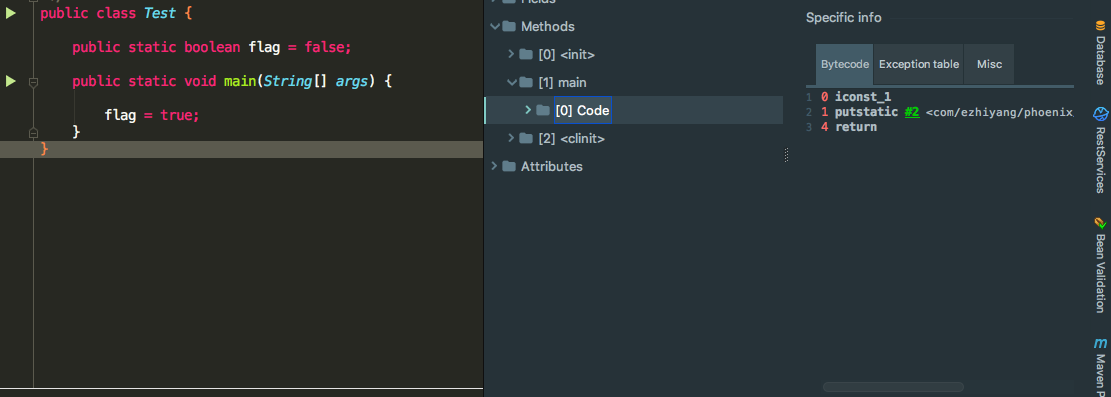
发现它们所生成的字节码是一样的,说明Java不是在编译阶段解决指令重排的,而是在运行期加上Lock汇编指令去完成指令重排的
我们来看一段代码编译成的汇编指令:
public class Test {
private static volatile Boolean flag = false;
public static void main(String[] args) throws InterruptedException {
new Thread(new Runnable() {
@Override
public void run() {
while (!flag) {
}
System.out.println("结束了");
}
}).start();
Thread.sleep(2000);
new Thread(new Runnable() {
@Override
public void run() {
setFlag();
}
}).start();
System.out.println("123213");
}
public static void setFlag() {
flag = true;
}
}
这段代码部分汇编指令如下:
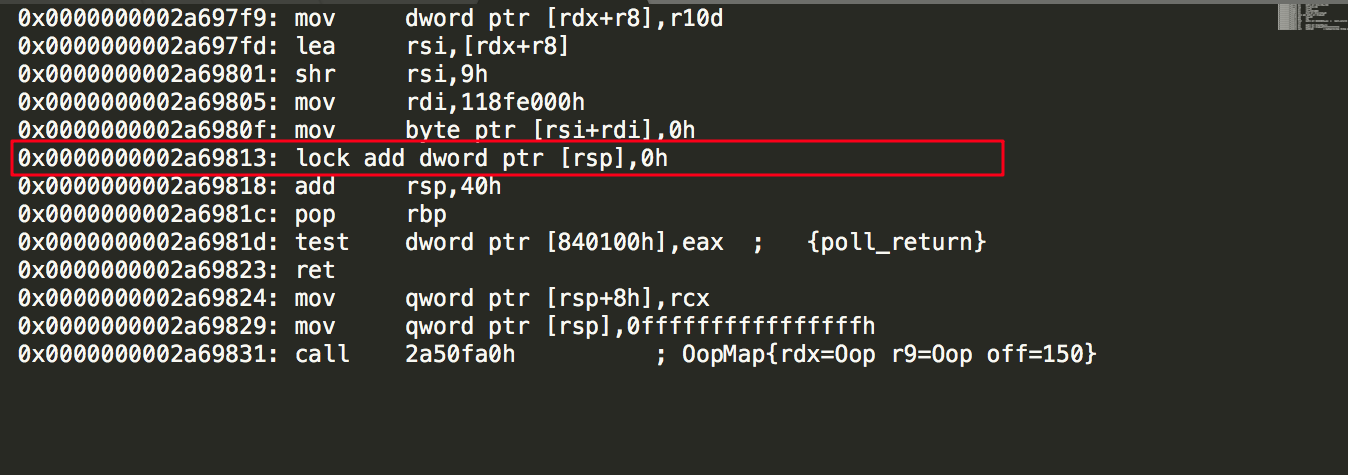
其中我们可以看到有一个lock汇编前缀指令,其实这个汇编lock指令就相当于一个内存屏障,防止后面的指令放到内存屏障之前的位置。Java代码要执行成汇编指令的话,可以去下载hsdis-amd64.dll文件,让我们的程序输出具体的汇编指令。这里不再具体讲解怎么操作了。
内存屏障又分为两种:Load Barrier(读屏障),Store Barrier(写屏障)
对于Load Barrier来说,在指令前插入Load Barrier强制从主内存加载数据
对于Store Barrier来说,在指令后插入Store Barrier能让写入的数据同步更新到主内存中,对其他线程可见
两种内存屏障又可以两两组合,最后形成四种组合方式:
LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
用volatile修饰的变量:
在这个变量写操作的时候,都会在写操作之前插入StoreStore屏障,在写操作后插入StoreLoad屏障
在这个变量读操作的时候,都会在读操作之前插入LoadLoad屏障,在读操作后插入LoadStore屏障
总结
volatile修饰的变量主要保证了可见性,有序性。但是不保证其原子性。还是有可能存在并发问题。能用volatile解决的并发问题尽可能不要去使用synchronize。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号