
Storm介绍及安装部署
Storm是Twitter开源的分布式实时大数据处理框架,最早开源于github,从0.9.1版本之后,归于Apache社区,被业界称为实时版Hadoop。随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易、股票)等等,大数据实时处理解决方案(流计算)的应用日趋广泛,目前已是分布式技术领域最新爆发点,而Storm更是流计算技术中的佼佼者和主流。
storm核心组件
- Nimbus:即Storm的Master,负责资源分配和任务调度。一个Storm集群只有一个Nimbus。
- Supervisor:即Storm的Slave,负责接收Nimbus分配的任务,管理所有Worker,一个Supervisor节点中包含多个Worker进程。
- Worker:工作进程,每个工作进程中都有多个Task。
- Task:任务,在 Storm 集群中每个 Spout 和 Bolt 都由若干个任务(tasks)来执行。每个任务都与一个执行线程相对应。
- Topology:计算拓扑,Storm 的拓扑是对实时计算应用逻辑的封装,它的作用与 MapReduce 的任务(Job)很相似,区别在于 MapReduce 的一个 Job 在得到结果之后总会结束,而拓扑会一直在集群中运行,直到你手动去终止它。拓扑还可以理解成由一系列通过数据流(Stream Grouping)相互关联的 Spout 和 Bolt 组成的的拓扑结构。
- Stream:数据流(Streams)是 Storm 中最核心的抽象概念。一个数据流指的是在分布式环境中并行创建、处理的一组元组(tuple)的无界序列。数据流可以由一种能够表述数据流中元组的域(fields)的模式来定义。
- Spout:数据源(Spout)是拓扑中数据流的来源。一般 Spout 会从一个外部的数据源读取元组然后将他们发送到拓扑中。根据需求的不同,Spout 既可以定义为可靠的数据源,也可以定义为不可靠的数据源。一个可靠的 Spout能够在它发送的元组处理失败时重新发送该元组,以确保所有的元组都能得到正确的处理;相对应的,不可靠的 Spout 就不会在元组发送之后对元组进行任何其他的处理。一个 Spout可以发送多个数据流。
- Bolt:拓扑中所有的数据处理均是由 Bolt 完成的。通过数据过滤(filtering)、函数处理(functions)、聚合(aggregations)、联结(joins)、数据库交互等功能,Bolt 几乎能够完成任何一种数据处理需求。一个 Bolt 可以实现简单的数据流转换,而更复杂的数据流变换通常需要使用多个 Bolt 并通过多个步骤完成。
- Stream grouping:为拓扑中的每个 Bolt 的确定输入数据流是定义一个拓扑的重要环节。数据流分组定义了在 Bolt 的不同任务(tasks)中划分数据流的方式。在 Storm 中有八种内置的数据流分组方式。
- Reliability:可靠性。Storm 可以通过拓扑来确保每个发送的元组都能得到正确处理。通过跟踪由 Spout 发出的每个元组构成的元组树可以确定元组是否已经完成处理。每个拓扑都有一个“消息延时”参数,如果 Storm 在延时时间内没有检测到元组是否处理完成,就会将该元组标记为处理失败,并会在稍后重新发送该元组。
Storm程序在Storm集群中运行的示例图如下:
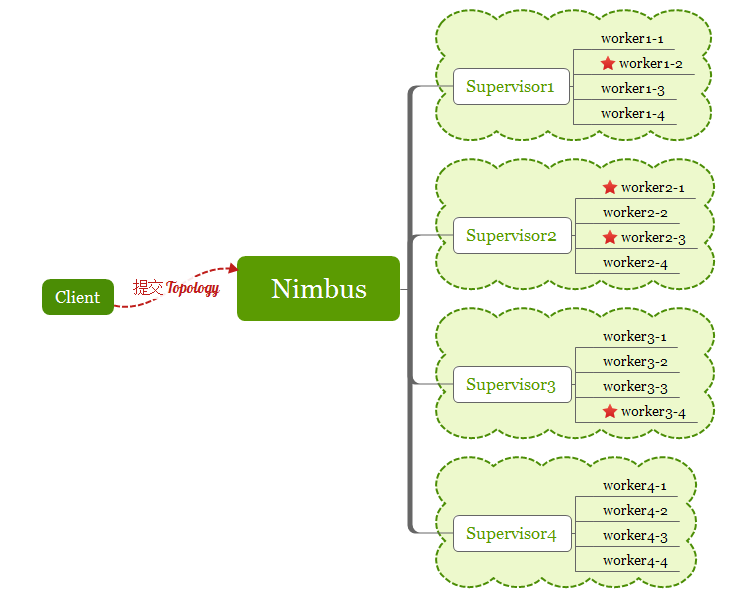
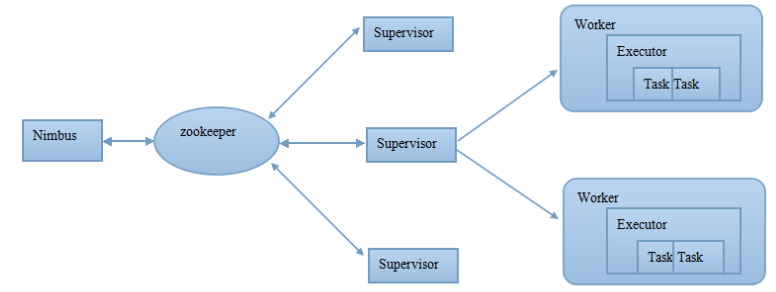
一个Zookeeper集群负责Nimbus和多个Supervisor之间的所有协调工作(一个完整的拓扑可能被分为多个子拓扑并由多个supervisor完成)
此外,Nimbus后台程序和Supervisor后台程序都是快速失败(fail-fast)和无状态的;所有状态维持在Zookeeper或本地磁盘。这意味着你可以kill -9杀掉nimbus进程和supervisor进程,然后重启,它们将恢复状态并继续工作,就像什么也没发生。这种设计使storm极其稳定。这种设计中Master并没有直接和worker通信,而是借助一个中介Zookeeper,这样一来可以分离master和worker的依赖,将状态信息存放在zookeeper集群内以快速恢复任何失败的一方
部署storm
| 主机名 | IP | zookeeper | 角色 | 版本 |
| c1.heboan.com | 192.168.48.128 | √ | Nimbus /UI | apache-storm-1.2.3.tar.gz |
| c2.heboan.com | 192.168.48.129 | √ | Supervisor | |
| c3.heboan.com | 192.168.48.130 | √ | Supervisor |
Storm使用zookeeper来协调集群,zookeeper不用于消息传递,因此Sorm对zookeeper的负载非常低。对于大多数情况,单节点zookeeper集群应该足够,但是如果要进行故障转移或者部署大型Storm集群,则可需要部署更大的Zookeeper集群。
这里在上面主机上部署3个节点的zk集群,部署方法点击我
下载Storm,并解压到部署目录
wget http://mirror.bit.edu.cn/apache/storm/apache-storm-1.2.3/apache-storm-1.2.3.tar.gz tar xf apache-storm-1.2.3.tar.gz -C /opt/service/ cd /opt/service/ ln -s apache-storm-1.2.3 storm
配置storm.yaml
conf/storm.yaml是 storm配置文件,storm.yaml会覆盖defaults.yaml中的任何内容
1)storm.zookeeper.servers:这是Storm集群的Zookeeper集群中的主机列表
storm.zookeeper.servers: - "c1.heboan.com" - "c2.heboan.com" - "c3.heboan.com"
2)storm.local.dir:Nimbus和Supervisor守护进程需要本地磁盘上的一个目录来存储少量状态(如jar,confs和类似的东西), 如果该目录不存在,会自动创建
storm.local.dir: "/opt/service/storm/status"
3) nimbus.seeds: 指定numbus主机
nimbus.seeds: ["c1.heboan.com"]
4)supervisor.slots.ports:对于每个工作者计算机,您可以使用此配置配置在该计算机上运行的工作程序数。每个工作人员使用单个端口接收消息,此设置定义哪些端口可以使用。如果您在此处定义了五个端口,那么Storm将分配最多五个工作人员在此计算机上运行。如果您定义了三个端口,Storm最多只能运行三个端口。默认情况下,此设置配置为在端口6700,6701,6702和6703上运行4个工作程序, 可以根据实际情况增加或减少,例如:
supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
5)配置web ui监听的端口
ui.port: 8888
6)jvm配置, 根据实际情况进行配置
nimbus.childopts: "-Xmx4096m" supervisor.childopts: "-Xmx4906m" worker.childopts: "-Xmx8096m" ui.childopts: "-Xmx1024m"
配置完成了,把程序拷贝到其他两个节点
scp -r storm 192.168.48.129:/opt/service/ scp -r storm 192.168.48.130:/opt/service/
启动集群
c1.heboan.com启动Nimbus和ui
cd /opt/service/storm/bin ./storm nimbus >/dev/null 2>&1 & ./storm ui >/dev/null 2>&1 &
c2和c3启动supervisor
cd /opt/service/storm/bin ./storm supervisor >/dev/null 2>&1 &
访问ui: http://192.168.48.128:8888

如果要启动supervisor日志,则在supervisor节点执行
./storm logviewer >/dev/null 2>&1 &


 浙公网安备 33010602011771号
浙公网安备 33010602011771号