MySQL日志文件与分析
1.查询日志、慢查询日志、二进制日志对比
| 查询日志 | general_log |
会记录用户的所有操作,其中包含增删查改等 | 可以指定输出为表 |
| 慢查询日志 | slow_log |
只要超过定义时间的所有操作语句都记录 | 可以指定输出为表 |
| 二进制日志 | log_bin |
记录可能执行更改的所有操作 | mysqlbinlog查看 |
2.日志的分析
2.1日志的存储
数据操作过程中,Mysqld是将接收到的语句按照接收的顺序(注意不是执行顺序)写到查询日志文件中。一条一条就类似这样:
# Time: 070927 8:08:52
# User@Host: root[root] @ [192.168.0.20]
# Query_time: 372 Lock_time: 136 Rows_sent: 152 Rows_examined: 263630
select id, name from manager where id in (66,10135);
这样的话,当我们去查看日志内容时就会灰常费时费神费眼睛。那么应该怎么破?
自5.1.6版本起,就有一波新功能出炉,比如查询日志可以写到数据库系统中的专用表。
MySQL的命令行在启动时可以加载很多参数,其中就提供了一个日志专用的参数--log-output,用来指定日志文件的输出方式.
--log-output参数可选值有三个:
- TABLE:记录到数据库中的日志表;
- FILE:记录到日志文件,默认值即为FILE (在5.1.6到5.1.20版本时,默认值为TABLE);
- NONE:不记录。
(1)可以是TABLE、FILE、NONE,也可以是TABLE及FILE的组合(用逗号隔开),默认为TABLE。
(2)如果组合中出现了NONE,那么其它设定都将失效,同时,无论是否启用日志功能,也不会记录任何相关的日志信息。
(3)作用范围为全局级别,可用于配置文件,属动态变量。
(4)启用mysqld进程时附加--log-output指定日志输出类型。
MySQL支持将慢查询日志保存到mysql.slow_log这张表中:

2.2慢查询分析工具
如果慢查询日志输出类型已经指定了FILE,在日志量大的情况下,我们可以借助一些分析工具。

(2)mysqlsla
hackmysql.com推出的一款日志分析工具
功能非常强大. 数据报表,非常有利于分析慢查询的原因, 包括执行频率, 数据量, 查询消耗等.

格式说明如下:
总查询次数 (queries total), 去重后的sql数量 (unique)输出报表的内容排序(sorted by)最重大的慢sql统计信息, 包括平均执行时间, 等待锁时间, 结果行的总数, 扫描的行总数。
Count: sql的执行次数及占总的slow log数量的百分比。
Time: 执行时间, 包括总时间, 平均时间, 最小, 最大时间, 时间占到总慢sql时间的百分比。
95% of Time: 去除最快和最慢的sql, 覆盖率占95%的sql的执行时间。
Lock Time: 等待锁的时间。
95% of Lock: 95%的慢sql等待锁时间。
Rows sent: 结果行统计数量, 包括平均, 最小, 最大数量。
Rows examined: 扫描的行数量。
Database: 属于哪个数据库。
Users: 哪个用户IP占到所有用户执行的sql百分比。
Query abstract: 抽象后的sql语句。
Query sample: sql语句。
除了以上的输出, 官方还提供了很多定制化参数, 是一款不可多得的好工具。
(3) pt-upgrade
这个工具用来检查在新版本中运行的SQL是否与老版本一样,返回相同的结果,最好的应用场景就是数据迁移的时候。
pt-upgrade h=host1 h=host2 slow.log
(4) pt-query-digest
可以从普通MySQL日志,慢查询日志以及二进制日志中分析查询,甚至可以从SHOW PROCESSLIST和MySQL协议的tcpdump中进行分析,如果没有指定文件,它从标准输入流(STDIN)中读取数据。
最简单的用法如下:
pt-query-digest slow.logs
整个输出分为三大部分:
1、整体概要(Overall)
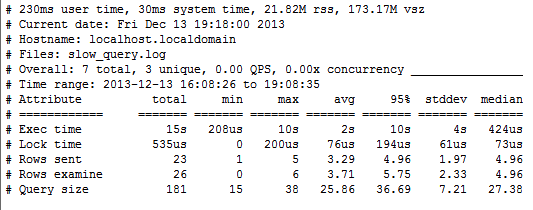
这个部分是一个大致的概要信息(类似loadrunner给出的概要信息),通过它可以对当前MySQL的查询性能做一个初步的评估,比如各个指标的最大 值(max),平均值(min),95%分布值,中位数(median),标准偏差(stddev)。这些指标有查询的执行时间(Exec time),锁占用的时间(Lock time),MySQL执行器需要检查的行数(Rows examine),最后返回给客户端的行数(Rows sent),查询的大小。
2、查询的汇总信息(Profile)
这个部分对所有”重要”的查询(通常是比较慢的查询)做了个一览表:

每个查询都有一个Query ID,这个ID通过Hash计算出来的。pt-query-digest是根据这个所谓的Fingerprint来group by的。举例下面两个查询的Fingerprint是一样的都是select * from table1 where column1 = ?,工具箱中也有一个与之相关的工具pt-fingerprint。
select * from table1 where column1 = 2 select * from table1 where column1 = 3
- Rank整个分析中该“语句”的排名,一般也就是性能最常的。
- Response time “语句”的响应时间以及整体占比情况。
- Calls 该“语句”的执行次数。
- R/Call 每次执行的平均响应时间。
- V/M 响应时间的差异平均对比率。
在尾部有一行输出,显示了其他2个占比较低而不值得单独显示的查询的统计数据。
3、详细信息
这个部分会列出Profile表中每个查询的详细信息:

包括Overall中有的信息、查询响应时间的分布情况以及该查询”入榜”的理由。
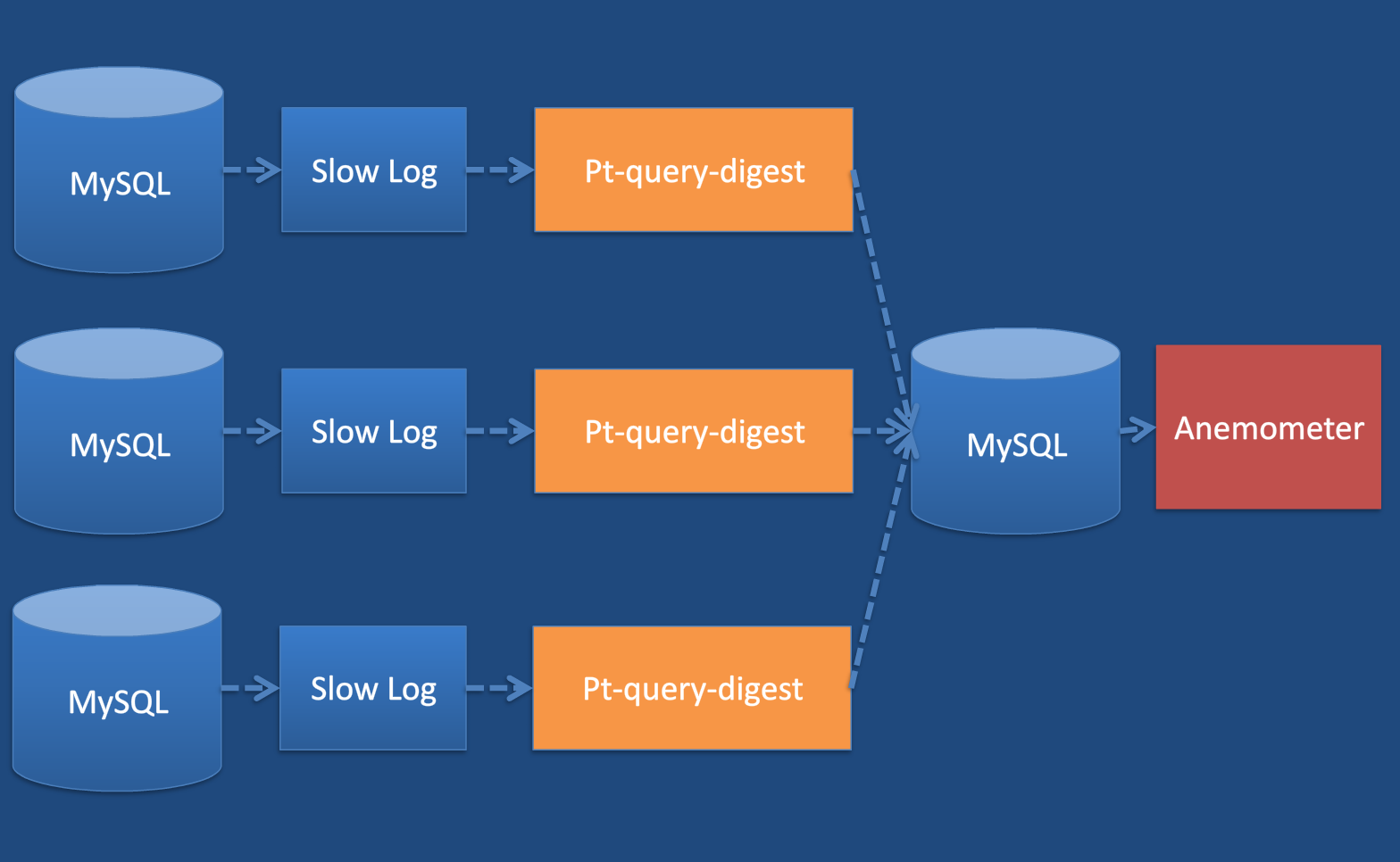
2.3BOX Anemometer
BOX Anemometer是 基于pt-query-digest将MySQL慢查询可视化