
Python-网络编程(二)
一.网络通讯原理
1.互联网的本质就是一系列的网络协议
我们是在浏览器上输入了一个网址,但是我们都知道,互联网连接的电脑互相通信的是电信号,我们的电脑是怎么将我们输入的网址变成了电信号然后发送出去了呢,并且我们发送出去的消息是不是应该让对方的服务器能够知道,我们是在请求它的网站呢,也就是说京东是不是应该知道我发送的消息是什么意思呢。是不是发送的消息应该有一些固定的格式呢?让所有电脑都能识别的消息格式,他就像英语成为世界上所有人通信的统一标准一样,如果把计算机看成分布于世界各地的人,那么连接两台计算机之间的internet实际上就是一系列统一的标准,这些标准称之为互联网协议,互联网的本质就是一系列的协议,总称为‘互联网协议’(Internet Protocol Suite)。
互联网协议的功能:定义计算机如何接入internet,以及接入internet的计算机通信的标准。
网络通信的流程昨天已经说过了,出门左转就能看到,这里就不再说了.
2.osi七层协议
互联网协议按照功能不同分为osi七层或tcp/ip五层或tcp/ip四层
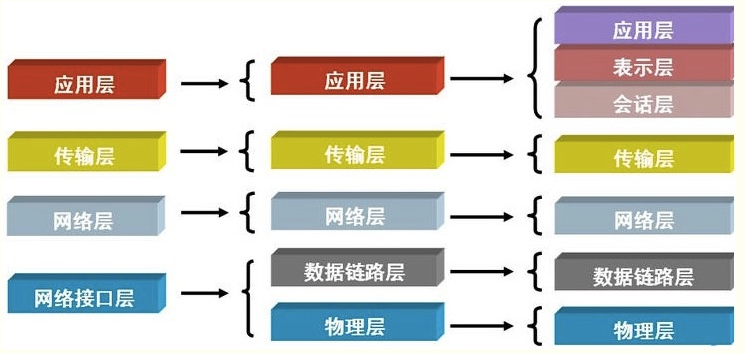
我们现在只需要了解五层的协议就好了,ok吗?我们写的程序属于哪一层呢,属于应用层。
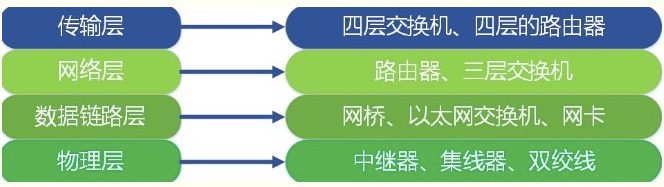
每层运行常见物理设备
3.tcp/ip五层模型讲解
我们将应用层,表示层,会话层并作应用层,从tcp/ip五层协议的角度来阐述每层的由来与功能,搞清楚了每层的主要协议
就理解了整个互联网通信的原理。
首先,用户感知到的只是最上面一层应用层,自上而下每层都依赖于下一层,所以我们从最下一层开始切入,比较好理解
每层都运行特定的协议,越往上越靠近用户,越往下越靠近硬件
3.1 物理层

物理层功能:主要是基于电器特性发送高低电压(电信号),高电压对应数字1,低电压对应数字0
3.2 数据链路层
数据链路层的功能:定义了电信号的分组方式
以太网协议:
早期的时候各个公司都有自己的分组方式,后来形成了统一的标准,即以太网协议ethernet
ethernet规定
一组电信号构成一个数据包,叫做‘帧’
每一数据帧分成:报头head和数据data两部分
mac地址:
mac地址:每块网卡出厂时都被烧制上一个世界唯一的mac地址,长度为48位2进制,通常由12位16进制数表示(前六位是厂商编号,后六位是流水线号)
3.3 网络层
IP协议:
规定网络地址的协议叫ip协议,它定义的地址称之为ip地址,广泛采用的v4版本即ipv4,它规定网络地址由32位2进制表示
范围0.0.0.0-255.255.255.255 (4个点分十进制,也就是4个8位二进制数)
一个ip地址通常写成四段十进制数,例:172.16.10.1
ipv6,通过上面可以看出,ip紧缺,所以为了满足更多ip需要,出现了ipv6协议:6个冒号分割的16进制数表示,这个应该是将来的趋势,但是ipv4还是用的最多的,因为我们一般一个公司就一个对外的IP地址,我们所有的机器上网都走这一个IP出口。
ip数据包
ip数据包也分为head和data部分,无须为ip包定义单独的栏位,直接放入以太网包的data部分
head:长度为20到60字节
data:最长为65,515字节。
而以太网数据包的”数据”部分,最长只有1500字节。因此,如果IP数据包超过了1500字节,它就需要分割成几个以太网数据包,分开发送了。
3.4 传输层
tcp协议:(TCP把连接作为最基本的对象,每一条TCP连接都有两个端点,这种端点我们叫作套接字(socket),它的定义为端口号拼接到IP地址即构成了套接字,例如,若IP地址为192.3.4.16 而端口号为80,那么得到的套接字为192.3.4.16:80。)
当应用程序希望通过 TCP 与另一个应用程序通信时,它会发送一个通信请求。这个请求必须被送到一个确切的地址。在双方“握手”之后,TCP 将在两个应用程序之间建立一个全双工 (full-duplex,双方都可以收发消息) 的通信。
这个全双工的通信将占用两个计算机之间的通信线路,直到它被一方或双方关闭为止。
它是可靠传输,TCP数据包没有长度限制,理论上可以无限长,但是为了保证网络的效率,通常TCP数据包的长度不会超过IP数据包的长度,以确保单个TCP数据包不必再分割。
udp协议:不可靠传输,”报头”部分一共只有8个字节,总长度不超过65,535字节,正好放进一个IP数据包。
tcp三次握手和四次挥手
我们知道网络层,可以实现两个主机之间的通信。但是这并不具体,因为,真正进行通信的实体是在主机中的进程,是一个主机中的一个进程与另外一个主机中的一个进程在交换数据。IP协议虽然能把数据报文送到目的主机,但是并没有交付给主机的具体应用进程。而端到端的通信才应该是应用进程之间的通信。
UDP,在传送数据前不需要先建立连接,远地的主机在收到UDP报文后也不需要给出任何确认。虽然UDP不提供可靠交付,但是正是因为这样,省去和很多的开销,使得它的速度比较快,比如一些对实时性要求较高的服务,就常常使用的是UDP。对应的应用层的协议主要有 DNS,TFTP,DHCP,SNMP,NFS 等。
TCP,提供面向连接的服务,在传送数据之前必须先建立连接,数据传送完成后要释放连接。因此TCP是一种可靠的的运输服务,但是正因为这样,不可避免的增加了许多的开销,比如确认,流量控制等。对应的应用层的协议主要有 SMTP,TELNET,HTTP,FTP 等。
三次握手:
1.TCP服务器进程先创建传输控制块TCB,时刻准备接受客户进程的连接请求,此时服务器就进入了 LISTEN(监听)状态;
2.TCP客户进程也是先创建传输控制块TCB,然后向服务器发出连接请求报文,这是报文首部中的同部位SYN=1,同时选择一个初始序列号 seq=x ,此时,TCP客户端进程进入了 SYN-SENT(同步已发送状态)状态。TCP规定,SYN报文段(SYN=1的报文段)不能携带数据,但需要消耗掉一个序号。
3.TCP服务器收到请求报文后,如果同意连接,则发出确认报文。确认报文中应该 ACK=1,SYN=1,确认号是ack=x+1,同时也要为自己初始化一个序列号 seq=y,此时,TCP服务器进程进入了SYN-RCVD(同步收到)状态。这个报文也不能携带数据,但是同样要消耗一个序号。
4.TCP客户进程收到确认后,还要向服务器给出确认。确认报文的ACK=1,ack=y+1,自己的序列号seq=x+1,此时,TCP连接建立,客户端进入ESTABLISHED(已建立连接)状态。TCP规定,ACK报文段可以携带数据,但是如果不携带数据则不消耗序号。
5.当服务器收到客户端的确认后也进入ESTABLISHED状态,此后双方就可以开始通信了。
四次挥手:
数据传输完毕后,双方都可释放连接。最开始的时候,客户端和服务器都是处于ESTABLISHED状态,然后客户端主动关闭,服务器被动关闭。服务端也可以主动关闭,一个流程。
1.客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2.服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3.客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
4.服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5.客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
6.服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。

3.5 应用层
应用层由来:用户使用的都是应用程序,均工作于应用层,互联网是开发的,大家都可以开发自己的应用程序,数据多种多样,必须规定好数据的组织形式
应用层功能:规定应用程序的数据格式。
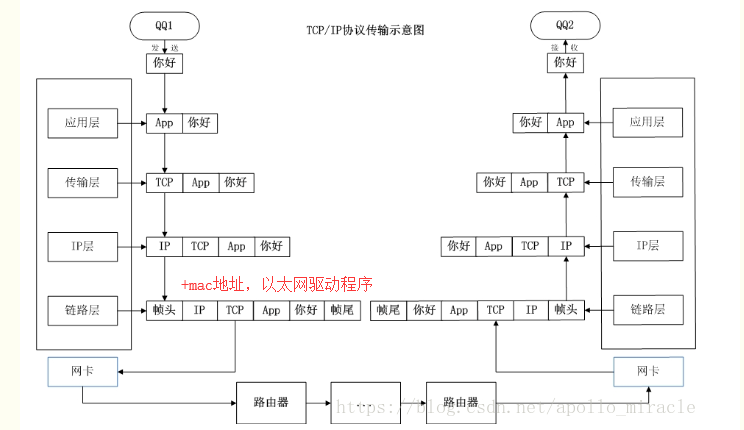
五层通信流程:
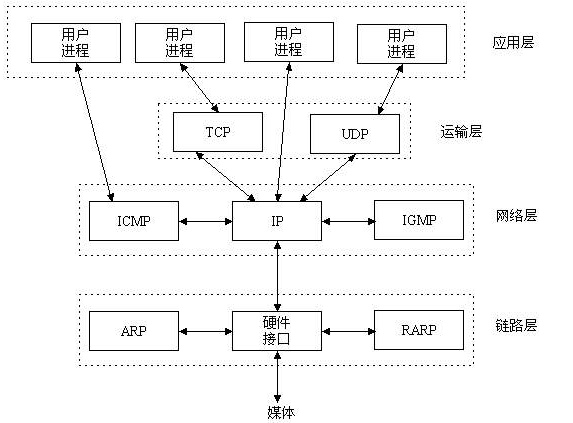
二. socket
结合上图来看,socket在哪一层呢,我们继续看下图
socket在内的五层通讯流程:
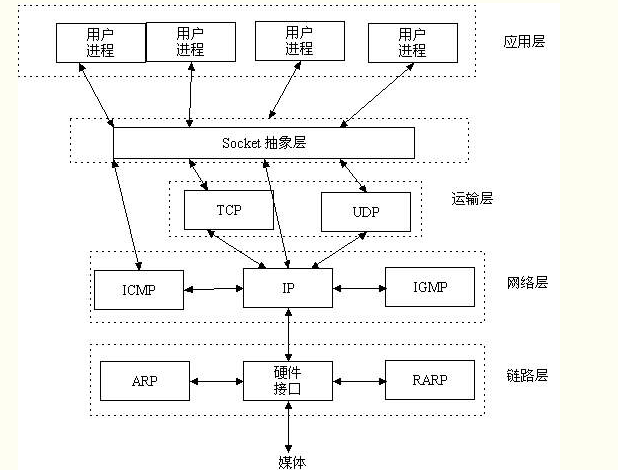
Socket又称为套接字,它是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。当我们使用不同的协议进行通信时就得使用不同的接口,还得处理不同协议的各种细节,这就增加了开发的难度,软件也不易于扩展(就像我们开发一套公司管理系统一样,报账、会议预定、请假等功能不需要单独写系统,而是一个系统上多个功能接口,不需要知道每个功能如何去实现的)。于是UNIX BSD就发明了socket这种东西,socket屏蔽了各个协议的通信细节,使得程序员无需关注协议本身,直接使用socket提供的接口来进行互联的不同主机间的进程的通信。这就好比操作系统给我们提供了使用底层硬件功能的系统调用,通过系统调用我们可以方便的使用磁盘(文件操作),使用内存,而无需自己去进行磁盘读写,内存管理。socket其实也是一样的东西,就是提供了tcp/ip协议的抽象,对外提供了一套接口,同过这个接口就可以统一、方便的使用tcp/ip协议的功能了。
其实站在你的角度上看,socket就是一个模块。我们通过调用模块中已经实现的方法建立两个进程之间的连接和通信。也有人将socket说成ip+port,因为ip是用来标识互联网中的一台主机的位置,而port是用来标识这台机器上的一个应用程序。 所以我们只要确立了ip和port就能找到一个应用程序,并且使用socket模块来与之通信。
三.套接字socket的发展史及分类
基于文件类型的套接字家族
套接字家族的名字:AF_UNIX
基于网络类型的套接字家族
套接字家族的名字:AF_INET
四.基于TCP和UDP两个协议下socket的通讯流程
1.TCP和UDP对比
TCP(Transmission Control Protocol)可靠的、面向连接的协议(eg:打电话)、传输效率低全双工通信(发送缓存&接收缓存)、面向字节流。使用TCP的应用:Web浏览器;文件传输程序。
UDP(User Datagram Protocol)不可靠的、无连接的服务,传输效率高(发送前时延小),一对一、一对多、多对一、多对多、面向报文(数据包),尽最大努力服务,无拥塞控制。使用UDP的应用:域名系统 (DNS);视频流;IP语音(VoIP)。
直接看图对比其中差异

继续往下看
TCP和UDP下socket差异对比图:

2.TCP协议下的socket
基于TCP的socket通讯流程图片:

虽然上图将通讯流程中的大致描述了一下socket各个方法的作用,但是还是要总结一下通讯流程(下面一段内容)
先从服务器端说起。服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束
上代码感受一下,需要创建两个文件,文件名称随便起,为了方便看,我的两个文件名称为tcp_server.py(服务端)和tcp_client.py(客户端),将下面的server端的代码拷贝到tcp_server.py文件中,将下面client端的代码拷贝到tcp_client.py的文件中,然后先运行tcp_server.py文件中的代码,再运行tcp_client.py文件中的代码,然后在pycharm下面的输出窗口看一下效果。
server端代码示例(如果比喻成打电话)
|
1
2
3
4
5
6
7
8
9
10
|
import socketsk = socket.socket()sk.bind(('127.0.0.1',8898)) #把地址绑定到套接字sk.listen() #监听链接conn,addr = sk.accept() #接受客户端链接ret = conn.recv(1024) #接收客户端信息print(ret) #打印客户端信息conn.send(b'hi') #向客户端发送信息conn.close() #关闭客户端套接字sk.close() #关闭服务器套接字(可选) |
client端代码示例
|
1
2
3
4
5
6
7
|
import socketsk = socket.socket() # 创建客户套接字sk.connect(('127.0.0.1',8898)) # 尝试连接服务器sk.send(b'hello!')ret = sk.recv(1024) # 对话(发送/接收)print(ret)sk.close() # 关闭客户套接字 |
socket绑定IP和端口时可能出现下面的问题:

解决办法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#加入一条socket配置,重用ip和端口import socketfrom socket import SOL_SOCKET,SO_REUSEADDRsk = socket.socket()sk.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #在bind前加,允许地址重用sk.bind(('127.0.0.1',8898)) #把地址绑定到套接字sk.listen() #监听链接conn,addr = sk.accept() #接受客户端链接ret = conn.recv(1024) #接收客户端信息print(ret) #打印客户端信息conn.send(b'hi') #向客户端发送信息conn.close() #关闭客户端套接字sk.close() #关闭服务器套接字(可选) |
但是如果你加上了上面的代码之后还是出现这个问题:OSError: [WinError 10013] 以一种访问权限不允许的方式做了一个访问套接字的尝试。那么只能换端口了,因为你的电脑不支持端口重用。
记住一点,用socket进行通信,必须是一收一发对应好。
提一下:网络相关或者需要和电脑上其他程序通信的程序才需要开一个端口。
在看UDP协议下的socket之前,我们还需要加一些内容来讲:看代码
server端
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import socketfrom socket import SOL_SOCKET,SO_REUSEADDRsk = socket.socket()# sk.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)sk.bind(('127.0.0.1',8090))sk.listen()conn,addr = sk.accept() #在这阻塞,等待客户端过来连接while True: ret = conn.recv(1024) #接收消息 在这还是要阻塞,等待收消息 ret = ret.decode('utf-8') #字节类型转换为字符串中文 print(ret) if ret == 'bye': #如果接到的消息为bye,退出 break msg = input('服务端>>') #服务端发消息 conn.send(msg.encode('utf-8')) if msg == 'bye': breakconn.close()sk.close() |
client端
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import socketsk = socket.socket()sk.connect(('127.0.0.1',8090)) #连接服务端while True: msg = input('客户端>>>') #input阻塞,等待输入内容 sk.send(msg.encode('utf-8')) if msg == 'bye': break ret = sk.recv(1024) ret = ret.decode('utf-8') print(ret) if ret == 'bye': breaksk.close() |
你会发现,第一个连接的客户端可以和服务端收发消息,但是第二个连接的客户端发消息服务端是收不到的
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import socketfrom socket import SOL_SOCKET,SO_REUSEADDRsk = socket.socket()# sk.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #允许地址重用,这个东西都说能解决问题,我非常不建议大家这么做,容易出问题sk.bind(('127.0.0.1',8090))sk.listen()# 第二步演示,再加一层while循环while True: #下面的代码全部缩进进去,也就是循环建立连接,但是不管怎么聊,只能和一个聊,也就是另外一个优雅的断了之后才能和另外一个聊 #它不能同时和好多人聊,还是长连接的原因,一直占用着这个端口的连接,udp是可以的,然后我们学习udp conn,addr = sk.accept() #在这阻塞,等待客户端过来连接 while True: ret = conn.recv(1024) #接收消息 在这还是要阻塞,等待收消息 ret = ret.decode('utf-8') #字节类型转换为字符串中文 print(ret) if ret == 'bye': #如果接到的消息为bye,退出 break msg = input('服务端>>') #服务端发消息 conn.send(msg.encode('utf-8')) if msg == 'bye': break conn.close() |
client端代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import socketsk = socket.socket()sk.connect(('127.0.0.1',8090)) #连接服务端while True: msg = input('客户端>>>') #input阻塞,等待输入内容 sk.send(msg.encode('utf-8')) if msg == 'bye': break ret = sk.recv(1024) ret = ret.decode('utf-8') print(ret) if ret == 'bye': break# sk.close() |
强制断开连接之后的报错信息:

3.UDP协议下的socket
老样子!先上图!
基于UDP的socket通讯流程:

总结一下UDP下的socket通讯流程
先从服务器端说起。服务器端先初始化Socket,然后与端口绑定(bind),recvform接收消息,这个消息有两项,消息内容和对方客户端的地址,然后回复消息时也要带着你收到的这个客户端的地址,发送回去,最后关闭连接,一次交互结束
上代码感受一下,需要创建两个文件,文件名称随便起,为了方便看,我的两个文件名称为udp_server.py(服务端)和udp_client.py(客户端),将下面的server端的代码拷贝到udp_server.py文件中,将下面cliet端的代码拷贝到udp_client.py的文件中,然后先运行udp_server.py文件中的代码,再运行udp_client.py文件中的代码,然后在pycharm下面的输出窗口看一下效果。
server端代码示例
|
1
2
3
4
5
6
7
|
import socketudp_sk = socket.socket(type=socket.SOCK_DGRAM) #创建一个服务器的套接字udp_sk.bind(('127.0.0.1',9000)) #绑定服务器套接字msg,addr = udp_sk.recvfrom(1024)print(msg)udp_sk.sendto(b'hi',addr) # 对话(接收与发送)udp_sk.close() # 关闭服务器套接字 |
client端代码示例
|
1
2
3
4
5
6
|
import socketip_port=('127.0.0.1',9000)udp_sk=socket.socket(type=socket.SOCK_DGRAM)udp_sk.sendto(b'hello',ip_port)back_msg,addr=udp_sk.recvfrom(1024)print(back_msg.decode('utf-8'),addr) |
五.粘包现象
说粘包之前,我们先说两个内容,1.缓冲区、2.windows下cmd窗口调用系统指令

5.2 windows下cmd窗口调用系统指令(linux下没有写出来,大家仿照windows的去摸索一下吧)

b.在打开的cmd窗口中输入dir(dir:查看当前文件夹下的所有文件和文件夹),你会看到下面的输出结果。

另外还有ipconfig(查看当前电脑的网络信息),在windows没有ls这个指令(ls在linux下是查看当前文件夹下所有文件和文件夹的指令,和windows下的dir是类似的),那么没有这个指令就会报下面这个错误

5.3 粘包现象(两种)
先上图:(本图是我做出来为了让小白同学有个大致的了解用的,其中很多地方更加的复杂,那就需要将来大家有多余的精力的时候去做一些深入的研究了,这里我就不带大家搞啦)

MTU简单解释:
MTU是Maximum Transmission Unit的缩写。意思是网络上传送的最大数据包。MTU的单位是字节。
大部分网络设备的MTU都是1500个字节,也就是1500B。如果本机一次需要发送的数据比网关的MTU大,
大的数据包就会被拆开来传送,这样会产生很多数据包碎片,增加丢包率,降低网络速度
关于上图中提到的Nagle算法等建议大家去看一看Nagle算法、延迟ACK、linux下的TCP_NODELAY和TCP_CORK,这些内容等你们把python学好以后再去研究吧,网络的内容实在太多啦,也就是说大家需要努力的过程还很长,加油!
超出缓冲区大小会报下面的错误,或者udp协议的时候,你的一个数据包的大小超过了你一次recv能接受的大小,也会报下面的错误,tcp不会,但是超出缓存区大小的时候,肯定会报这个错误。

5.4 模拟一个粘包现象
|
1
2
3
4
5
6
7
8
9
10
|
import subprocesscmd = input('请输入指令>>>')res = subprocess.Popen( cmd, #字符串指令:'dir','ipconfig',等等 shell=True, #使用shell,就相当于使用cmd窗口 stderr=subprocess.PIPE, #标准错误输出,凡是输入错误指令,错误指令输出的报错信息就会被它拿到 stdout=subprocess.PIPE, #标准输出,正确指令的输出结果被它拿到)print(res.stdout.read().decode('gbk'))print(res.stderr.read().decode('gbk')) |
注意:
如果是windows,那么res.stdout.read()读出的就是GBK编码的,在接收端需要用GBK解码
且只能从管道里读一次结果,PIPE称为管道。

好,既然我们会使用subprocess了,那么我们就通过它来模拟一个粘包
tcp粘包演示(一):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
cket import *import subprocessip_port=('127.0.0.1',8080)BUFSIZE=1024tcp_socket_server=socket(AF_INET,SOCK_STREAM)tcp_socket_server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)tcp_socket_server.bind(ip_port)tcp_socket_server.listen(5)while True: conn,addr=tcp_socket_server.accept() print('客户端>>>',addr) while True: cmd=conn.recv(BUFSIZE) if len(cmd) == 0:break res=subprocess.Popen(cmd.decode('gbk'),shell=True, stdout=subprocess.PIPE, stdin=subprocess.PIPE, stderr=subprocess.PIPE) stderr=res.stderr.read() stdout=res.stdout.read() conn.send(stderr) conn.send(stdout) |
client端代码示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import socketip_port = ('127.0.0.1',8080)size = 1024tcp_sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM)res = tcp_sk.connect(ip_port)while True: msg=input('>>: ').strip() if len(msg) == 0:continue if msg == 'quit':break tcp_sk.send(msg.encode('utf-8')) act_res=tcp_sk.recv(size) print('接收的返回结果长度为>',len(act_res)) print('std>>>',act_res.decode('gbk')) #windows返回的内容需要用gbk来解码,因为windows系统的默认编码为gbk |
tcp粘包演示(二):发送数据时间间隔很短,数据也很小,会合到一起,产生粘包
server端代码示例:(如果两次发送有一定的时间间隔,那么就不会出现这种粘包情况,试着在两次发送的中间加一个time.sleep(1))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
from socket import *ip_port=('127.0.0.1',8080)tcp_socket_server=socket(AF_INET,SOCK_STREAM)tcp_socket_server.bind(ip_port)tcp_socket_server.listen(5)conn,addr=tcp_socket_server.accept()data1=conn.recv(10)data2=conn.recv(10)print('----->',data1.decode('utf-8'))print('----->',data2.decode('utf-8'))conn.close() |
client端代码示例:
|
1
2
3
4
5
6
7
8
|
import socketBUFSIZE=1024ip_port=('127.0.0.1',8080)s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)# res=s.connect_ex(ip_port)res=s.connect(ip_port)s.send('hi'.encode('utf-8'))s.send('meinv'.encode('utf-8')) |
示例二的结果:全部被第一个recv接收了

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import socketfrom socket import SOL_SOCKET,SO_REUSEADDR,SO_SNDBUF,SO_RCVBUFsk = socket.socket(type=socket.SOCK_DGRAM)# sk.setsockopt(SOL_SOCKET,SO_RCVBUF,80*1024)sk.bind(('127.0.0.1',8090))msg,addr = sk.recvfrom(1024)while True: cmd = input('>>>>') if cmd == 'q': break sk.sendto(cmd.encode('utf-8'),addr) msg,addr = sk.recvfrom(1032) # print('>>>>', sk.getsockopt(SOL_SOCKET, SO_SNDBUF)) # print('>>>>', sk.getsockopt(SOL_SOCKET, SO_RCVBUF)) print(len(msg)) print(msg.decode('utf-8'))sk.close() |
client端代码示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import socketfrom socket import SOL_SOCKET,SO_REUSEADDR,SO_SNDBUF,SO_RCVBUFsk = socket.socket(type=socket.SOCK_DGRAM)# sk.setsockopt(SOL_SOCKET,SO_RCVBUF,80*1024)sk.bind(('127.0.0.1',8090))msg,addr = sk.recvfrom(1024)while True: cmd = input('>>>>') if cmd == 'q': break sk.sendto(cmd.encode('utf-8'),addr) msg,addr = sk.recvfrom(1024) # msg,addr = sk.recvfrom(1218) # print('>>>>', sk.getsockopt(SOL_SOCKET, SO_SNDBUF)) # print('>>>>', sk.getsockopt(SOL_SOCKET, SO_RCVBUF)) print(len(msg)) print(msg.decode('utf-8'))sk.close() |
在udp的代码中,我们在server端接收返回消息的时候,我们设置的recvfrom(1024),那么当我输入的执行指令为‘dir’的时候,dir在我当前文件夹下输出的内容大于1024,然后就报错了,报的错误也是下面这个:

解释原因:是因为udp是面向报文的,意思就是每个消息是一个包,你接收端设置接收大小的时候,必须要比你发的这个包要大,不然一次接收不了就会报这个错误,而tcp不会报错,这也是为什么ucp会丢包的原因之一,这个和我们上面缓冲区那个错误的报错原因是不一样的。
补充两个问题:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
补充问题一:为何tcp是可靠传输,udp是不可靠传输 tcp在数据传输时,发送端先把数据发送到自己的缓存中,然后协议控制将缓存中的数据发往对端,对端返回一个ack=1,发送端则清理缓存中的数据,对端返回ack=0,则重新发送数据,所以tcp是可靠的。 而udp发送数据,对端是不会返回确认信息的,因此不可靠补充问题二:send(字节流)和sendall send的字节流是先放入己端缓存,然后由协议控制将缓存内容发往对端,如果待发送的字节流大小大于缓存剩余空间,那么数据丢失,用sendall就会循环调用send,数据不会丢失,一般的小数据就用send,因为小数据也用sendall的话有些影响代码性能,简单来讲就是还多while循环这个代码呢。 用UDP协议发送时,用sendto函数最大能发送数据的长度为:65535- IP头(20) – UDP头(8)=65507字节。用sendto函数发送数据时,如果发送数据长度大于该值,则函数会返回错误。(丢弃这个包,不进行发送)用TCP协议发送时,由于TCP是数据流协议,因此不存在包大小的限制(暂不考虑缓冲区的大小),这是指在用send函数时,数据长度参数不受限制。而实际上,所指定的这段数据并不一定会一次性发送出去,如果这段数据比较长,会被分段发送,如果比较短,可能会等待和下一次数据一起发送。 |
粘包的原因:主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的
六.粘包的解决方案
解决方案(一):

看代码示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
import socket,subprocessip_port=('127.0.0.1',8080)s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)s.bind(ip_port)s.listen(5)while True: conn,addr=s.accept() print('客户端',addr) while True: msg=conn.recv(1024) if not msg:break res=subprocess.Popen(msg.decode('utf-8'),shell=True,\ stdin=subprocess.PIPE,\ stderr=subprocess.PIPE,\ stdout=subprocess.PIPE) err=res.stderr.read() if err: ret=err else: ret=res.stdout.read() data_length=len(ret) conn.send(str(data_length).encode('utf-8')) data=conn.recv(1024).decode('utf-8') if data == 'recv_ready': conn.sendall(ret) conn.close() |
client端代码示例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import socket,times=socket.socket(socket.AF_INET,socket.SOCK_STREAM)res=s.connect_ex(('127.0.0.1',8080))while True: msg=input('>>: ').strip() if len(msg) == 0:continue if msg == 'quit':break s.send(msg.encode('utf-8')) length=int(s.recv(1024).decode('utf-8')) s.send('recv_ready'.encode('utf-8')) send_size=0 recv_size=0 data=b'' while recv_size < length: data+=s.recv(1024) recv_size+=len(data) print(data.decode('utf-8')) |
解决方案(二):
struck模块的使用:struct模块中最重要的两个函数是pack()打包, unpack()解包。
pack():#我在这里只介绍一下'i'这个int类型
|
1
2
3
4
5
6
7
|
import structa=12# 将a变为二进制bytes=struct.pack('i',a)-------------------------------------------------------------------------------struct.pack('i',1111111111111) 如果int类型数据太大会报错struck.errorstruct.error: 'i' format requires -2147483648 <= number <= 2147483647 #这个是范围 |
unpack():
|
1
2
3
|
# 注意,unpack返回的是tuple !!a,=struct.unpack('i',bytes) #将bytes类型的数据解包后,拿到int类型数据 |
好,到这里我们将struck这个模块将int类型的数据打包成四个字节的方法了,那么我们就来使用它解决粘包吧。
先看一段伪代码示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import json,struct#假设通过客户端上传1T:1073741824000的文件a.txt#为避免粘包,必须自定制报头header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1T数据,文件路径和md5值#为了该报头能传送,需要序列化并且转为bytes,因为bytes只能将字符串类型的数据转换为bytes类型的,所有需要先序列化一下这个字典,字典不能直接转化为byteshead_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化并转成bytes,用于传输#为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节head_len_bytes=struct.pack('i',len(head_bytes)) #这4个字节里只包含了一个数字,该数字是报头的长度#客户端开始发送conn.send(head_len_bytes) #先发报头的长度,4个bytesconn.send(head_bytes) #再发报头的字节格式conn.sendall(文件内容) #然后发真实内容的字节格式#服务端开始接收head_len_bytes=s.recv(4) #先收报头4个bytes,得到报头长度的字节格式x=struct.unpack('i',head_len_bytes)[0] #提取报头的长度head_bytes=s.recv(x) #按照报头长度x,收取报头的bytes格式header=json.loads(json.dumps(header)) #提取报头#最后根据报头的内容提取真实的数据,比如real_data_len=s.recv(header['file_size'])s.recv(real_data_len) |
下面看正式的代码:
server端代码示例:报头:就是消息的头部信息,我们要发送的真实内容为报头后面的内容。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import socket,struct,jsonimport subprocessphone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) #忘了这是干什么的了吧,地址重用?想起来了吗~phone.bind(('127.0.0.1',8080))phone.listen(5)while True: conn,addr=phone.accept() while True: cmd=conn.recv(1024) if not cmd:break print('cmd: %s' %cmd) res=subprocess.Popen(cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) err=res.stderr.read() if err: back_msg=err else: back_msg=res.stdout.read() conn.send(struct.pack('i',len(back_msg))) #先发back_msg的长度 conn.sendall(back_msg) #在发真实的内容 #其实就是连续的将长度和内容一起发出去,那么整个内容的前4个字节就是我们打包的后面内容的长度,对吧 conn.close() |
client端代码示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import socket,time,structs=socket.socket(socket.AF_INET,socket.SOCK_STREAM)res=s.connect_ex(('127.0.0.1',8080))while True: msg=input('>>: ').strip() if len(msg) == 0:continue if msg == 'quit':break s.send(msg.encode('utf-8')) #发送给一个指令 l=s.recv(4) #先接收4个字节的数据,因为我们将要发送过来的内容打包成了4个字节,所以先取出4个字节 x=struct.unpack('i',l)[0] #解包,是一个元祖,第一个元素就是我们的内容的长度 print(type(x),x) # print(struct.unpack('I',l)) r_s=0 data=b'' while r_s < x: #根据内容的长度来继续接收4个字节后面的内容。 r_d=s.recv(1024) data+=r_d r_s+=len(r_d) # print(data.decode('utf-8')) print(data.decode('gbk')) #windows默认gbk编码 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号