
BioDeepAV:一个多模态基准数据集,包含超过1600个深度伪造视频,用于评估深度伪造检测器在面对未知生成器时的性能。
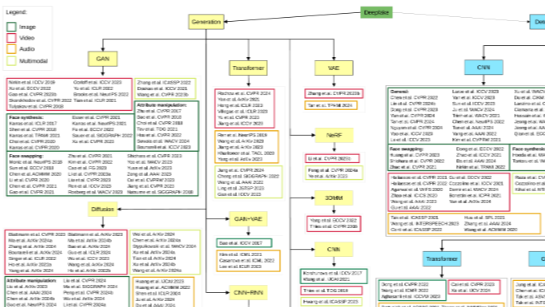 2024-11-29, 由罗马尼亚布加勒斯特大学创建BioDeepAV数据集,它专门设计来评估最先进的深度伪造检测器在面对未见过的深度伪造生成器时的泛化能力,这对于提高检测器的鲁棒性和适应性具有重要意义。
2024-11-29, 由罗马尼亚布加勒斯特大学创建BioDeepAV数据集,它专门设计来评估最先进的深度伪造检测器在面对未见过的深度伪造生成器时的泛化能力,这对于提高检测器的鲁棒性和适应性具有重要意义。
2024-11-29, 由罗马尼亚布加勒斯特大学创建BioDeepAV数据集,它专门设计来评估最先进的深度伪造检测器在面对未见过的深度伪造生成器时的泛化能力,这对于提高检测器的鲁棒性和适应性具有重要意义。
一、研究背景:
随着生成模型的快速发展,深度伪造内容的逼真度不断提高,人们越来越难以在线检测出被操纵的媒体内容,从而容易受到各种诈骗的欺骗。这不仅对个人隐私构成威胁,也对社会信任和民主构成挑战。
目前遇到困难和挑战:
1、深度伪造检测器通常在特定生成器上训练,但对其他生成器生成的深度伪造内容检测效果不佳。
2、深度伪造技术不断进步,新的生成器不断出现,使得现有的检测方法难以适应。
二、让我们一起来看一下BioDeepAV数据集
BioDeepAV是一个多模态基准数据集,用于评估深度伪造检测器在面对未知生成器时的性能。
BioDeepAV包含超过1600个深度伪造视频,这些视频使用四种最新的专门用于说话人脸合成的方法生成。数据集涵盖了多种身份和表情,以及音频-视觉的不一致性。
数据集构建:
我们从HDTF和TalkingHead-1KH数据集中采样真实视频,并使用RealVisXL、LAION-Face和HDTF等来源的人脸图像,以及英语方言、HDTF数据集和我们自己创建的700多个深度伪造音频样本来生成深度伪造视频。
数据集特点:
1、包含由最新生成模型创建的深度伪造内容,这些内容在以前的数据集中未曾出现过。
2、提供了一个测试平台,用以评估检测器对未知深度伪造生成器的泛化能力。
研究人员可以使用BioDeepAV来训练和测试他们的深度伪造检测模型,特别是评估模型对于新出现或未知深度伪造生成器的检测能力
基准测试:
在BioDeepAV上运行了一系列最先进的深度伪造检测器,并发现即使这些检测器在原始测试集上表现优异,但在BioDeepAV上的性能大幅下降,这表明现有检测器在面对新生成器时存在明显的性能下降。
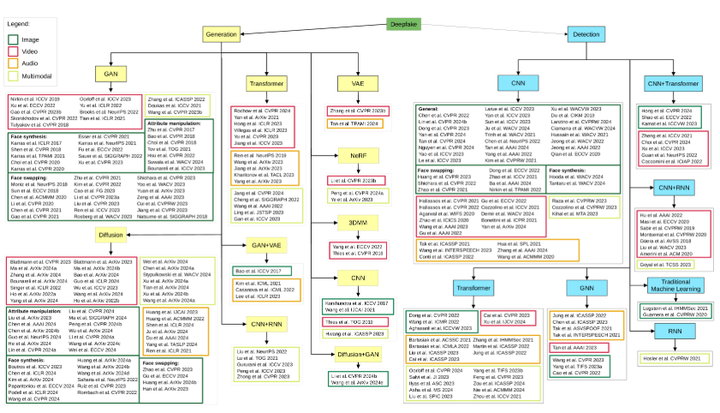

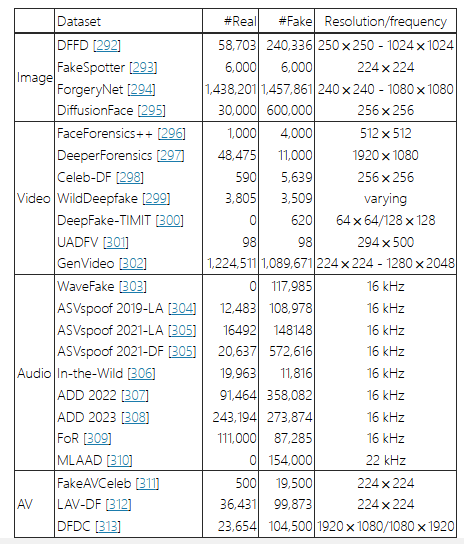
三、让我们一起展望数据集的应用
比如,你是一名计算机视觉研究员,你的团队正在开发一种新的深度伪造检测技术。你们的目标是创建一个能够准确识别出由最新深度伪造技术生成的视频的检测系统。你们面临的挑战是,现有的检测器往往只能在它们训练时见过的特定生成器生成的伪造内容上表现良好,而对新出现的生成器则无能为力。
你了解到了BioDeepAV数据集,这是一个专门用来评估深度伪造检测器对未知生成器泛化能力的数据集。这个数据集包含了1600多个由四种最新方法生成的深度伪造视频,包括了多种身份和表情,以及音频-视觉的不一致性。
你决定使用这个数据集来训练和测试你的检测模型。你从GitHub上下载了BioDeepAV数据集,开始着手进行深度伪造检测技术的研究与开发。
技术研究与开发
1、模型训练:你使用BioDeepAV数据集中的视频来训练你的深度伪造检测模型。这些视频是用最新的深度伪造技术生成的,包括了一些非常逼真的说话人脸视频。你的目标是让你的模型学会识别这些伪造视频的特征。
2、性能评估:在模型训练完成后,你在BioDeepAV数据集上进行严格的性能评估。你发现,尽管你的模型在一些常见的深度伪造数据集上表现良好,但在BioDeepAV上的表现却不尽如人意,这表明你的模型对新出现的深度伪造生成器的泛化能力还有待提高。
3、模型优化:基于BioDeepAV数据集的评估结果,你开始对你的模型进行优化。你尝试了多种技术,包括改进网络结构、引入新的损失函数、以及使用数据增强技术来提高模型的泛化能力。
4、迭代改进:经过多次迭代改进,你的模型在BioDeepAV数据集上的表现逐渐提升。你发现,通过结合多种技术,如自监督学习、对抗训练和多任务学习,你的模型能够更好地识别出由新生成器生成的深度伪造视频。
最终,你的团队开发出了一种新的深度伪造检测技术,这种技术在BioDeepAV数据集上展现出了强大的泛化能力。你的模型不仅能够识别出常见的深度伪造视频,还能够有效地检测出由最新技术生成的深度伪造内容。
更多开源数据集,请打开:遇见数据集

 浙公网安备 33010602011771号
浙公网安备 33010602011771号