MySQL知识树 查询分类
MySQL的查询可以分为交叉联接、内联接、外联接、自然联接、straight_join
下面对于查询的学习,会用到以下四张表:
create table t_commodity_type(
`id` BIGINT(20) not null auto_increment comment '商品类别ID',
`time` TIMESTAMP not null DEFAULT CURRENT_TIMESTAMP comment '入库时间',
`name` VARCHAR(32) not null DEFAULT '' comment '名称',
`is_use` bit(1) not null DEFAULT b'0' comment '是否上架',
primary key (`id`)
)engine=innodb DEFAULT CHARSET=utf8 comment '商品类型表';
create table t_commodity(
`id` BIGINT(20) not null auto_increment comment '商品ID',
`commodity_type_id` BIGINT(20) not null DEFAULT 0 COMMENT '商户所属类别ID',
`time` TIMESTAMP not null DEFAULT CURRENT_TIMESTAMP comment '入库时间',
`name` varchar(64) not null DEFAULT '' comment '商品名称',
`price` DECIMAL(20,2) not null DEFAULT 0.00 comment '价格',
`is_use` bit(1) not null DEFAULT b'0' comment '是否上架',
PRIMARY key (`id`),
key `com_typ_id` (`commodity_type_id`) using BTREE
)engine=innodb DEFAULT charset=utf8 COMMENT '商品表';
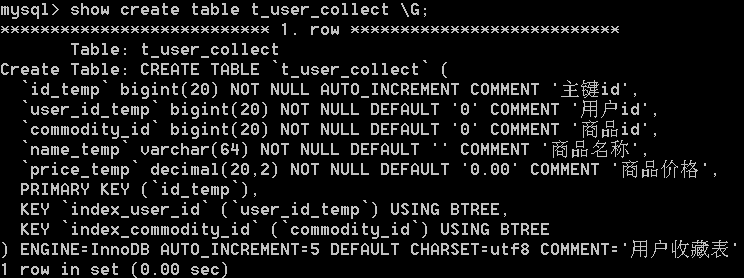
CREATE TABLE `t_user_collect` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`user_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '用户id',
`commodity_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '商品id',
`name` varchar(64) NOT NULL DEFAULT '' COMMENT '商品名称',
`price` decimal(20,2) NOT NULL DEFAULT '0.00' COMMENT '商品价格',
PRIMARY KEY (`id`),
KEY `index_user_id` (`user_id`) USING BTREE,
KEY `index_commodity_id` (`commodity_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户收藏表';
CREATE TABLE `t_user_order` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户订单id',
`user_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '用户id',
`commodity_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '商品id',
`name` varchar(64) NOT NULL DEFAULT '' COMMENT '商品名称',
`price` decimal(20,2) NOT NULL DEFAULT '0.00' COMMENT '商品价格',
PRIMARY KEY (`id`),
KEY `index_user_id` (`user_id`) USING BTREE,
KEY `index_commodity_id` (`commodity_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户订单表';
我们在查询原理中有讲解SQL中各子句的执行顺序【对于查询原理的学习烦请移步:http://www.cnblogs.com/seker/p/6536643.html】,因此无论from子句后的表有多少张,都先是第一张表和第二表执行完from、on、join后,再与第三张表重复该操作(from、on、join),一直到与最后一张表执行完该操作。
虽然原理是这样,但是对于交叉联接来说,其只有from的操作;对内联接来说,其只有from、on操作;而对于外联接来说,其有from、on、join操作。
①交叉联接(cross join)
对两表做笛卡尔积,这将返回两表所有列的组合,若表A有m行数据,表B有n行数据,则cross join将返回m*n行数据。如下SQL实例,
select uc.user_id as user_id, c.id as commodity_id, uc.`name` as `name`, uc.price as price
from t_commodity c cross join t_user_collect uc;
当然我们可以以一种更简单的语法来实现,
select uc.user_id as user_id, c.id as commodity_id, uc.`name` as `name`, uc.price as price
from t_commodity c, t_user_collect uc;
不用担心,两者的执行计划是一样的,

需要注意的是使用交叉联接就是想得到两表的笛卡尔积,虽然也可以配合on子句来使用,但实际当我们拿到两表的笛卡尔积后再去使用on,从行为上来说我们是想要得到两表关联的数据,那么就符合了内联接(inner join)的使用条件,因此在这种情况下,我们更应该去选择内联接(inner join)。
那么cross join在实际中有哪些应用呢?其实可以利用它产生笛卡尔积的特点用来快速生成大量测试数据,如下SQL:
insert into t_user_order(user_id,commodity_id,`name`,price)
select uc.user_id as user_id, c.id as commodity_id, uc.`name` as `name`, uc.price as price
from t_commodity c cross join t_user_collect uc;
②内联接(inner join)
通过on子句来匹配两表的记录,查询出来的数据是两表的交集。
拿t_commodity和t_commodity_type两张表来举例子,从表结构上看t_commodity表通过commodity_type_id列和t_commodity_type表的id列产生了关联,我们看一个SQL实例,
select c.id as id, ct.`name` as type_name, c.`name` as `name`, c.time as time
from t_commodity_type ct inner join t_commodity c on ct.id=c.commodity_type_id;
查询结果如下(仅截取了局部数据),
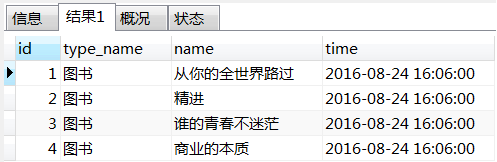
以上SQL可以通过另外几种形式来实现,如下:
1)省略inner关键字的实现
select c.id as id, ct.`name` as type_name, c.`name` as `name`, c.time as time
from t_commodity_type ct join t_commodity c on ct.id=c.commodity_type_id;
2)不接on子句,通过逗号分隔表来实现
select c.id as id, ct.`name` as type_name, c.`name` as `name`, c.time as time
from t_commodity_type ct, t_commodity c where ct.id=c.commodity_type_id;
3)通过cross join和on子句来实现
select c.id as id, ct.`name` as type_name, c.`name` as `name`, c.time as time
from t_commodity_type ct cross join t_commodity c on ct.id=c.commodity_type_id;
总共四种实现方式,它们的执行计划都是一样的,

额外知识点
为什么可以通过另外三种形式来实现呢?
1)在使用inner join时,inner关键字本身就是可以被省略的。
2)这其实是旧语法和新语法的区别,对于两表之间使用逗号分隔,且无on子句的SQL书写是ANSI(美国国家标准学会) SQL 89的规范,因为ANSI SQL 89在当时不支持on和join子句,而是直到ANSI SQL 92才引入的。
虽说是两种不同的语法,但MySQL对两者都是完全兼容的,两种书写方式无所谓好坏与否。MySQL优化器会为两者生成相同的执行计划,因此在执行效率及结果上都是一致的,至于在实际项目中使用哪种语法则取决于你所在公司的SQL规范。
3)inner join后不跟on子句,也可以通过MySQL语法解析,这时inner join就等于cross join,因为在MySQL数据库中cross join和inner join是同义词关系。因此,cross join也是可以配合on子句来使用的,只是一般很少这样做。
额外知识点
我们看到在SQL中on和where子句后都可以接过滤条件,那有没有一些通用的放置规则呢?
对两表的匹配条件一般放在on子句中,而对一个表过滤数据的条件一般放在where子句中。
③外联接(outer join)
外联接有两种,第一种是左外联接(left outer join),第二种是右外联接(right outer join)。
这种联接也是通过on子句来匹配两表的记录,但它与inner join不同的地方在于若是左外联接,则左表的记录会被全部获取,即便左表中的列无法通过on子句与右表发生匹配,这部分无匹配关系但依然被获取出来的记录,称之为外部行,而左表就被称之为保留表,若使用的是右外联接,那右表就是保留表。
我们来看一个SQL实例,
select ct.id as id, ct.`name` as type_name, c.`name` as `name`, c.time as time
from t_commodity_type ct left join t_commodity c on ct.id=c.commodity_type_id;
查询结果如下(仅截取了局部数据):
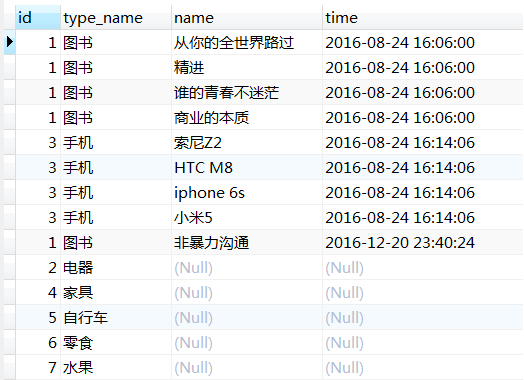
这个查询通过t_commodity_type表的id和t_commodity表的commodity_type_id进行匹配,由于有些商品类型在商品表中无对应关系,但又需要保留这部分行显示出来(添加外部行),于是可以看到结果中不属于t_commodity_type表的列值(c.`name`、c.time)被填充为Null(因未匹配而被添加的记录,其中不属于保留表的列值会被null填充)。
而对于右外联接,它的原理与左外联接一致,上面那个SQL用右外联接来实现就是:
select ct.id as id, ct.`name` as type_name, c.`name` as `name`, c.time as time
from t_commodity c right join t_commodity_type ct on c.commodity_type_id=ct.id;
可以看到在书写左外连接和右外连接时都没有加outer关键字,因为它是可以被省略的,这会使语法看起来更简洁。同样的左外联接、右外联接也可以简称为左联接、右联接,只要不要忘了它俩都属于outer join。
另外inner join即便省略了on子句也可以使用,但outer join就必须配合on子句来使用。这是因为inner join在省略了on子句后,就单纯的用于产生笛卡尔积了,其作用就等于cross join。而outer join会对保留表添加外部行,在没有on子句进行条件过滤的情况下,怎么会有添加外部行的操作呢。
额外知识点
如果on子句中的列具有相同的名称,那么可以使用using来简化SQL。我们来看一个实例,
简化前:
select uo.commodity_id, uo.`name` from t_user_order uo inner join t_user_collect uc on
uo.commodity_id=uc.commodity_id;
简化后:
select uo.commodity_id, uo.`name` from t_user_order uo inner join t_user_collect uc using (commodity_id);
这个SQL是想知道订单中的哪些商品原本是被用户收藏的。由于t_user_order表的commodity_id列与t_user_collect表的commodity_id列同名,因此我们使用了using来简化书写。两者的执行计划和结果都是一样的。

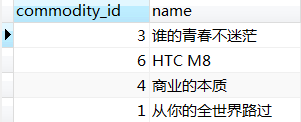
④自然联接(natural join)
自然联接会将两表中具有相同名称的列进行匹配。
我们用t_user_collect、t_user_order两表来做说明,t_user_collect表中的数据如下,
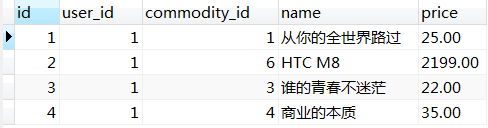
t_user_order表中的数据如下,
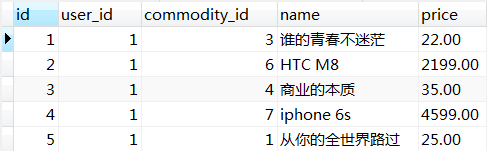
对两表使用自然联接,select * from t_user_order natural join t_user_collect;(这里我们为了方便演示使用了*,在实际开发中不建议这样做),我们可以看到以下数据被筛选出来,

怎么理解?由于两表每列名称都相同,因此只有每列的值都一致,才会匹配。观察两表数据,仅id为2的每列数据是一致的。假如我们将t_user_collect表中几个列名做修改,仅保留commodity_id,再看看会有怎样的匹配效果,修改后的t_user_collect表如下,
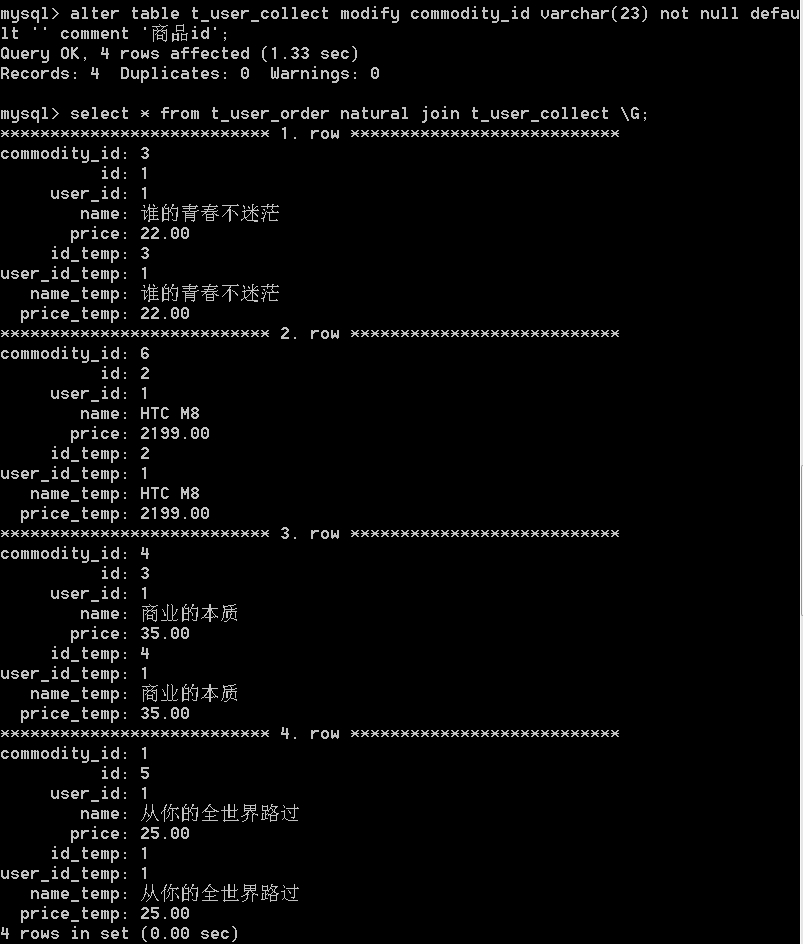
我们再执行select * from t_user_order natural join t_user_collec;(这里我们为了方便演示使用了*,在实际开发中不建议这样做),会得到以下数据,

可以看到有4行数据,因为commodity_id列在两表中是能产生4行数据匹配的,看到这里大家应该对natural join的使用效果较为明白了。简单来说就是当两表中仅有一个列名相同时,那么就会用这个列作为条件来匹配,而如果两表中每个列名都相同,那么就会用所有的列作为条件来匹配。
接下来我们再探讨两个问题,
1)相同名称但数据类型不同的列会产生匹配吗?
2)是否能以其它的联接方式来实现natural join的效果?
关于第1)个问题,我们可以做如下实验,对t_user_collect表的commodity_id列修改数据类型,再执行查询得到结果如下,
我们可以看到查询出的4行结果与之前的4行结果一致,这说明同名称的列虽然数据类型不同,但不会对natural join的匹配产生影响。
关于第2)个问题,就拿刚刚那个查询SQL:“select * from t_user_order natural join t_user_collec;”来说,它可以改写成如下形式:“select * from t_user_order inner join t_user_collect using(commodity_id);”。
实际上natural join等同于inner join和using的组合。
⑤straight_join
注意两个单词之间是有一个下划线连接的,straight_join会强制MySQL优化器先读取该子句左边的表。
因为我们在查询语句中书写的表联接顺序,到了MySQL实际执行时由于优化器的作用,联接顺序可能会发生变化,而straight_join就可以让MySQL按照我们指定的顺序去联接表,有一种强制作用。当然我们在使MySQL按照我们的意愿去联接表时,需要确保其执行效率要高于优化器原本的优化效果,不然就是坑自己。
来看一个SQL实例,
select * from t_commodity_type ct inner join t_commodity c on ct.id=c.commodity_type_id; 其执行计划如下,

我们可以看到虽然t_commodity_type表是写在inner join子句左边的,但MySQL先读取的却是t_commodity表,我们将上述SQL的inner join替换为straight_join,看看有什么变化,

从上面的截图中我们可以看到MySQL先读取了t_commodity_type表,但在rows一栏却扫描了15行数据,同时两张表分别执行了全表扫描(type为ALL),明显查询的效率降低了。因此除非是经验丰富的DBA,否则请谨慎使用straight_join子句。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号