
struts2实现的简单的Trie树
Trie树 又称单词查找树,前缀树或键树,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。这是百度百科做的概述。
Trie树是一个非常实用的索引结构,它可以稳定的以O(c)的时间复杂度,它的插入和查询时间复杂度都为 O(c),这是他的优点。 Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。所以Trie 的最大缺点是空间消耗很高。
它有3个基本特性:
1)根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2)从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3)每个节点的所有子节点包含的字符都不相同。
引入维基百科给的图:
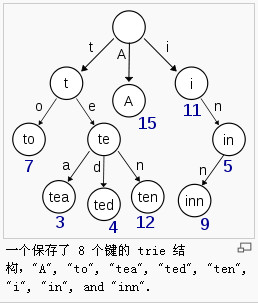
这是一个字符Trie树,每个节点一般来说包含俩部分:值域、指针列表。值域可以任意对象,指针列表可以使用数组、集合都可以。每个节点都固定的表示一个字符串,即从根节点到该节点,路径上经过的字符连接起来。如节点"to",所代表的字符就是从根节点到t节点的路径字符"t"连接上t节点与to节点的路径字符"o"。to节点的值是7。注意:节点内并不包含字符,这个字符是通过路径表示的,一般是采用某个默认的规则,如将指针列表中的下标转为对应的ascll码对应的字符,这样就将下标与某个字符对应起来,这个字符就是路径字符。
struts2中也实现了个简单Trie树org.apache.struts2.util.PrefixTrie,是用于实现前缀检索的。即当通过某个字符串检索值时,优先采用该字符的最小前缀所对应的值。源码如下:
package org.apache.struts2.util;
/**
* Quickly matches a prefix to an object.
*
*/
public class PrefixTrie {
// supports 7-bit chars.
private static final int SIZE = 128;
Node root = new Node();
public void put(String prefix, Object value) {
Node current = root;
for (int i = 0; i < prefix.length(); i++) {
char c = prefix.charAt(i);
if (c > SIZE)
throw new IllegalArgumentException("'" + c + "' is too big.");
if (current.next[c] == null)
current.next[c] = new Node();
current = current.next[c];
}
current.value = value;
}
public Object get(String key) {
Node current = root;
for (int i = 0; i < key.length(); i++) {
char c = key.charAt(i);
if (c > SIZE)
return null;
current = current.next[c];
if (current == null)
return null;
if (current.value != null)
return current.value;
}
return null;
}
static class Node {
Object value;
Node[] next = new Node[SIZE];
}
}
节点类型是通过内部类Node描述的。Node的值域是Object 实例(Object value;),指针列表是Node数组(Node[] next = new Node[SIZE];),数组大小是128,即128个ascll字符。数组的下标值与ascll码值一一对应。PrefixTrie内部预先实例化了根节点root(Node root = new Node();)。PrefixTrie内部只有俩个方法:put、get。这让我们想起了java.util.Map,其实PrefixTrie与Map功能非常相似,都是通过put赋值,通过get取值。两者的区别总结起来有三点:
1)二者的内部实现原理不同。
2)PrefixTrie的key值只能是字符串。
3)PrefixTrie的get是通过最小前缀检索的。
下面分别看下get、put方法是怎样实现的:
public void put(String prefix, Object value) {
Node current = root;
for (int i = 0; i < prefix.length(); i++) {
char c = prefix.charAt(i);
if (c > SIZE)
throw new IllegalArgumentException("'" + c + "' is too big.");
if (current.next[c] == null)
current.next[c] = new Node();
current = current.next[c];
}
current.value = value;
}
方法参数prefix是某个特定的字符串,对应java.util.Map 中的key。value是该字符串对应的值,对应java.util.Map 中的value。
put方法的工作过程实际上就是遍历多叉树(最多128叉)的过程,通过遍历找到该字符串对应的节点,将值放入该节点中。规则是依次遍历参数prefix的每个字符,然后以该字符的ascll码值为下标,访问节点的指针列表,从而找到子节点的路径,在沿着这个路径继续找下去,直到最后一个字符。
第1句定义个临时指针current初始指向根节点root,第2句遍历prefix,char c = prefix.charAt(i)句取当前字符,if (c > SIZE)判断字符是否超出范围以免指针列表数组越界。if (current.next[c] == null)以当前字符的ascll码值为下标判断子节点是否为空,为空则生成个节点。current = current.next[c]将工作指针指向该子节点,继续遍历。当遍历prefix结束时工作指针current指向的节点就是字符prefix对应的节点,将value放入该节点的值域中。而整个遍历树的路径其实就是prefix代表的字符串。
public Object get(String key) {
Node current = root;
for (int i = 0; i < key.length(); i++) {
char c = key.charAt(i);
if (c > SIZE)
return null;
current = current.next[c];
if (current == null)
return null;
if (current.value != null)
return current.value;
}
return null;
}
get方法的遍历树的过程和put方法是一样的,只不过当发现某个节点的值域不为空时立即返回这个值作为get方法的返回,由此来实现最小前缀的匹配。
比如我通过PrefixTrie的put方法分别对字符串"abcde"、"abc"进行了赋值,"abcde"的值为7,"abc"的值为5,则当我通过get方法检索值"abcd"、"abcde"时返回的都是5。因为"abcd"、"abcde"的最小前缀"abc"存在值,遍历到"abc"时就会立即返回。
PrefixTrie在struts2中主要是实现通过form表单域来设置动态方法调用的。
比如有如下表单:
<form action="http://localhost:8080/mystruts2/common/user">
<input type="text" name="method:hello" />
<input type="text" name="myAge"/>
<input type="submit" value="提交">
</form>
action属性定义了访问的命名空间为"/common",访问的action为"user", 访问action的哪个方法那 ?,这个由文本框<input type="text" name="method:hello" />设置,访问"hello"方法。struts2内部维护一个PrefixTrie对象,并通过PrefixTrie的put方法put("method:", handle)往前缀"method:"存入一个对象handle,每个前缀的handle都是不同的对象,这个handle对象是ParameterAction接口的一个实现类的实例,该对象主要负责从类似"method:hello"的字符串中截取出action的方法名(此处为hello)。而在检索某个handle时,是通过表单域提交上来的字符串"method:hello"调用PrefixTrie的get方法,从而检索出前缀"method:"对应的handle对象,在通过这个handle对象截取出action的方法名,从而实现动态方法调用设置的。

