Clip模型使用
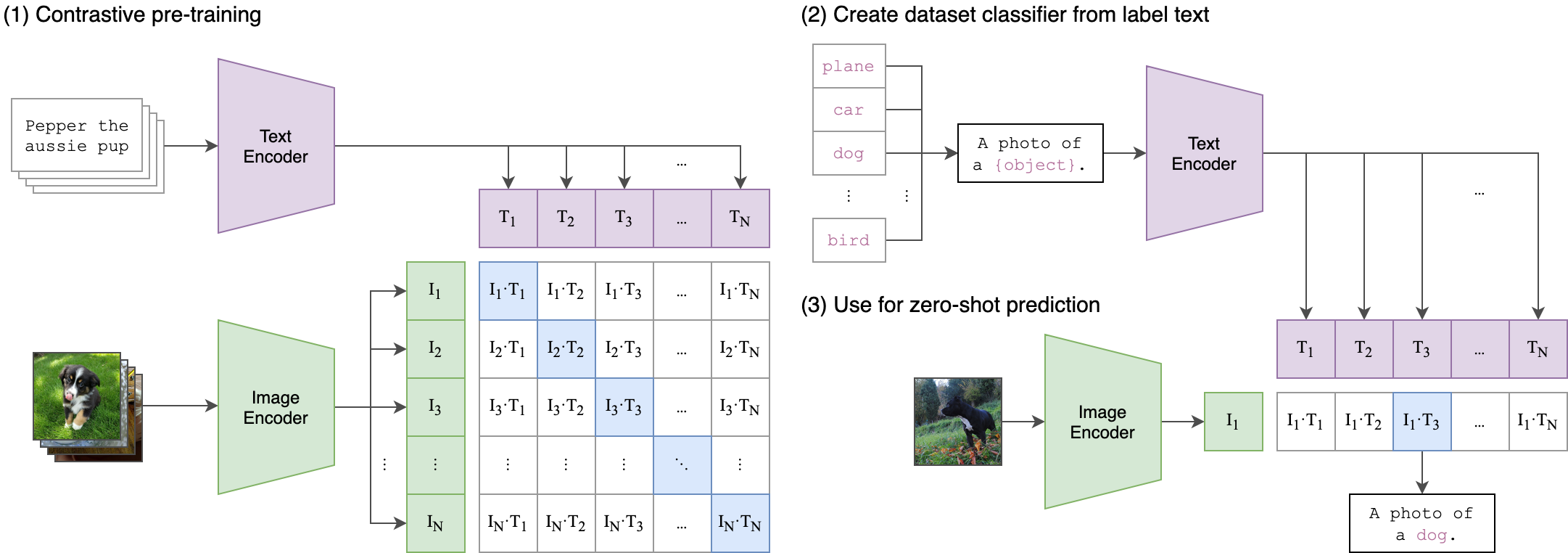
代码文件结构
clip.py
CLIP模块提供了以下方法:
clip.available_models()
返回可用的CLIP模型的名
import clip
models = clip.available_models()
print(models)
#结果
['RN50', 'RN101', 'RN50x4', 'RN50x16', 'RN50x64', 'ViT-B/32', 'ViT-B/16', 'ViT-L/14', 'ViT-L/14@336px']
clip.load(name, device=..., jit=False)
根据clip.available_models()返回的模型名称,返回模型(nn.model)以及模型所需的TorchVision变换。如有必要,它将下载模型。name参数也可以是本地检查点文件的路径。
可以可选地指定运行模型的设备,默认情况下,如果有CUDA设备则使用第一个CUDA设备,否则使用CPU。
当jit为False时,将加载非JIT版本的模型,jit模型经过优化,推理效率更高,但不容易更改;
当jit为True时,使用build_model加载模型,非jit模型适用于需要更改模型的情况。
返回值:
model : torch.nn.Module
The CLIP model
preprocess : Callable[[PIL.Image], torch.Tensor]
A torchvision transform that converts a PIL image into a tensor that the returned model can take as its input
import torch
import clip
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
print(model)
结果:

clip.tokenize(text: Union[str, List[str]], context_length=77)
返回一个LongTensor,其中包含给定文本输入的标记化序列。这可以作为模型的输入使用。
import torch
import clip
device = "cuda" if torch.cuda.is_available() else "cpu"
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
print(text.shape)
#结果
torch.Size([3, 77])
对于clip.load()返回的model,有3个关键用法:
model.encode_image(image: Tensor)
给定一批图像,返回由CLIP模型的视觉部分编码的图像特征。
model.encode_text(text: Tensor)
给定一批文本标记,返回由CLIP模型的语言部分编码的文本特征。
model(image: Tensor, text: Tensor)
给定一批图像和一批文本标记,返回两个张量,分别包含与每个图像和文本输入相对应的日志得分。这些值是对应图像和文本特征之间的余弦相似度,乘以100。
官方demo:
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
文本编码器
将文本["a diagram", "a dog", "a cat"]编码层text_featrue有几个步骤:
text = clip.tokenize(["a diagram", "a dog", "a cat"])
text_features = model.encode_text(text)
其中:
def encode_text(self, text):
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
x = x + self.positional_embedding.type(self.dtype)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_final(x).type(self.dtype)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
return x
clip.tokenize()
该函数用于将文本字符串列表转换为可以输入到 CLIP 模型中的标记化张量。此函数处理标记化过程,包括添加特殊标记、填充和截断文本以适应模型的预期输入格式。
text = clip.tokenize(["i am a handsome boy"]
print(text)
#结果
ensor([49406, 328, 687, 320, 7438, 1876, 49407, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0], device='cuda:0',
dtype=torch.int32)
49406表示截断,5个单词使用5个索引表示,77个长下文长度大学能表示70个单词左右的句子
self.token_embedding()
token_embedding 的作用是将输入的文本标记(tokens)转换为嵌入向量(embedding vectors)。这些嵌入向量是模型可以处理的数值表示形式。具体来说,token_embedding 是一个嵌入层(embedding layer),它将每个标记映射到一个高维向量空间中,这些向量捕捉了标记之间的语义关系。 在 CLIP 模型中,token_embedding 的输出形状为 [batch_size, n_ctx, d_model],其中:
- batch_size 是输入批次的大小。
- n_ctx 是上下文长度,表示每个输入序列的最大长度,这里是77。
- d_model 是嵌入维度,表示每个标记的嵌入向量的维度。
通过这种方式,文本数据可以被转换为模型可以处理的数值形式,从而进行进一步的计算和处理。
例子
import torch
import torch.nn as nn
# 假设我们有1000个词,每个词的向量维度是10
num_embeddings = 1000
embedding_dim = 5
# 定义一个Embedding层
embedding = nn.Embedding(num_embeddings, embedding_dim)
# 假设我们有一些词的索引
indices = torch.tensor([1, 2, 4, 5])
# 通过Embedding层获取这些词的向量表示
embeddings = embedding(indices)
print(embeddings)
# 结果
tensor([[-1.4052, 1.0736, 1.2210, 1.3236, -0.2328],
[-0.5652, 0.0780, 0.5559, -0.3371, 0.3103],
[ 0.6764, -0.4679, -0.4171, 0.3488, -0.9274],
[ 1.4365, -0.2475, 0.2176, -1.9012, 0.4145]],
grad_fn=<EmbeddingBackward0>)
每个单词 并非使用稀疏的one-hot编码表示,而是将整数索引映射到对应的固定大小的密集向量
self.positional_embedding
位置编码,本质上是一个可学习的torch,shape[77,512],通过广播机制和x(x.shape[3,77,512])相加
self.transformer()
Transformer 模型,它对输入数据进行一系列的变换和计算,通常包括多头自注意力机制和前馈神经网络层。
ln_final
LayerNorm(transformer_width),归一化
x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
索引选择:x[torch.arange(x.shape[0]), text.argmax(dim=-1)] 从张量 x 中选择特定的元素。torch.arange(x.shape[0]) 生成一个从 0 到 x.shape[0] - 1 的序列,表示批次中的每个样本。text.argmax(dim=-1) 返回 text 张量中每个样本的最大值的索引。通过这种方式,可以从 x 中选择每个样本对应的特定元素。
矩阵乘法:@ self.text_projection 将选择的元素与 self.text_projection 进行矩阵乘法。self.text_projection 是一个投影矩阵,用于将选择的元素映射到另一个空间。
总结来说,这行代码从 x 中选择每个样本的特定元素,并将其投影到另一个空间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号