
论文阅读-CORA: Adapting CLIP for Open-Vocabulary Detection with Region Prompting and Anchor Pre-Matching
摘要
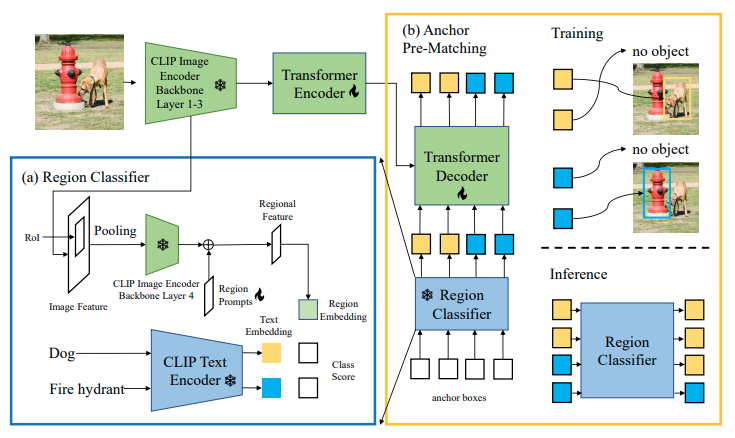
开集词汇检测(OVD)是一项目标检测任务,旨在检测训练检测器的基类之外的新类别对象。最近的开集词汇检测方法依赖于大规模的视觉-语言预训练模型,如CLIP,以识别新对象。我们确定了在将这些模型纳入检测器训练时需要解决的两大核心障碍:(1)当将训练于整幅图像的VL模型应用于区域识别任务时出现的分布不匹配;(2)定位未见类别对象的困难。为了克服这些障碍,我们提出了CORA,这是一个DETR风格的框架,通过区域提示和锚点预匹配来适应CLIP进行开集词汇检测。区域提示通过提示CLIP基础区域分类器的区域特征,减轻了整体到区域的分布差距。锚点预匹配通过一种类感知匹配机制帮助学习可泛化的对象定位。我们在COCO OVD基准测试上评估了CORA,在新型类别上实现了41.7的AP50,即使没有使用额外的训练数据,也超过了之前的SOTA 2.4个AP50。当有额外的训练数据时,我们在地面真实基类注释以及CORA计算得到的额外伪边界框标签上训练CORA+。CORA+在COCO OVD基准测试上实现了43.1的AP50,在LVIS OVD基准测试上实现了28.1的框APr。
论文框架

 浙公网安备 33010602011771号
浙公网安备 33010602011771号