论文阅读-ArtVLM: Attribute Recognition Through Vision-Based Prefix Language Modeling
摘要
识别并从对象中分离视觉属性是许多计算机视觉应用的基础。虽然像CLIP这样的大型视觉-语言表示在很大程度上解决了零样本对象识别的任务,但零样本视觉属性识别仍然是一个挑战,因为CLIP通过对比学习得到的视觉-语言表示无法有效捕捉对象-属性依赖关系。在本文中,我们针对这一弱点提出了一个基于句子生成的检索公式,用于属性识别,该公式在以下两个方面是新颖的:1)明确地将待测量和检索的对象-属性关系建模为一个条件概率图,这将识别问题转化为一个依赖敏感的语言建模问题;2)在这个重新表述上应用大型预训练的视觉-语言模型(VLM),并自然地将其关于图像-对象-属性关系的知识蒸馏出来,用于属性识别。具体来说,对于图像上要识别的每个属性,我们测量生成一个短句子的视觉条件概率,该句子编码属性与图像上对象的关系。与通过全局对齐句子元素和图像的可能性进行测量的对比检索不同,生成式检索对句子中对象和属性的顺序和依赖关系敏感。我们通过实验证明,在两个视觉推理数据集Visual Attribute in the Wild (VAW)上,生成式检索一致优于对比检索。
论文框架
研究背景和动机
1. 这篇论文试图解决什么问题?
该论文解决CLIP等对比模型进行视觉属性识别时无法建模属性之间的依赖关系的问题
2. 为什么这个问题重要?
对物体属性进行识别有助于增强模型对于现实世界的理解
3. 这个问题在当前的研究领域中有哪些已知的解决方案?
- 基于分类和排序的方法: 这些方法使用分类器或排序模型来预测图像中物体的属性。例如, Chen 和 Grauman (2018) 使用对比学习来学习视觉差异,而 Parikh 和 Grauman (2011) 使用排序模型来预测相对属性。
- 基于向量空间的方法: 这些方法将物体和属性投影到同一个特征空间中,并使用线性变换或加法运算符来建模属性对物体的修饰。例如, Chen 等人 (2023) 使用 CLIP 模型来比较视觉信息和预定义的属性提示,而 Nagarajan 和 Grauman (2018) 将属性视为运算符,用于将属性投影到物体上。
- 基于深度学习的模型: 这些模型使用深度学习技术来预测物体的属性。例如, Anderson 等人 (2018) 使用自下而上和自上而下的注意力机制来预测图像的标题和回答视觉问题。
研究方法和创新点
4. 论文提出了什么新的方法或模型?
这篇论文提出了 基于前缀语言模型的生成式检索方法 (ArtVLM),用于解决大规模视觉语言模型在属性识别任务中的局限性。
5. 这个方法或模型是如何工作的?
ArtVLM 的主要组成部分:
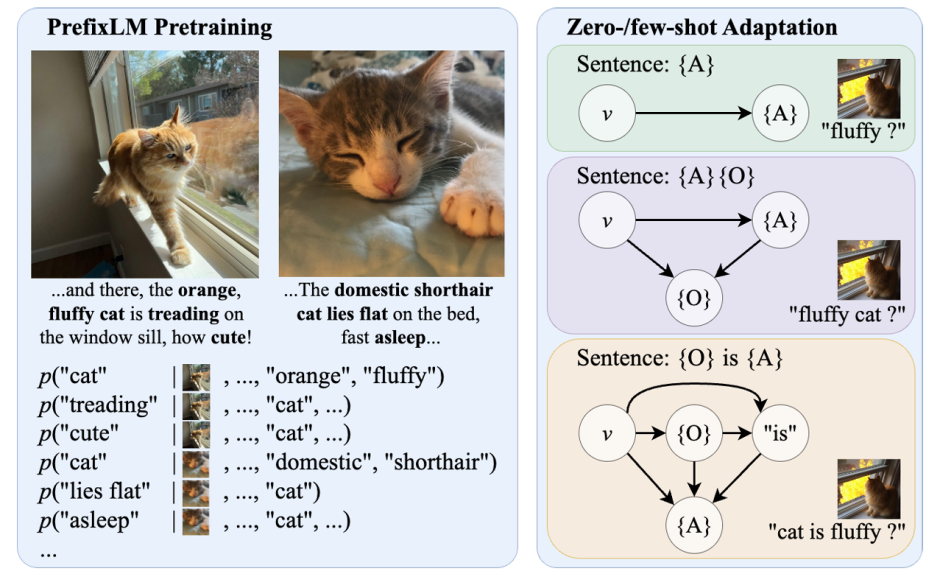
- 前缀语言模型 (PrefixLM): 作为预训练基础,PrefixLM 学习根据视觉输入和之前的文本标记预测下一个标记,从而捕捉句子中物体-属性依赖关系的复杂组合。
- 生成式检索: 作为下游属性识别任务的解决方案,生成式检索通过评估生成描述图像中物体和属性关系的句子概率来衡量图像-属性对齐情况。
识别原理:为了识别图像上的每个属性,测量了在视觉条件下生成一个短句子的概率,这个短句子能够表达该属性与图像上物体之间的关系。
6. 它与现有的方法相比有哪些改进?
由于句子生成模型会考虑词语之间的顺序和结构,将此视为object-attribute之间的依赖关系
7. 论文中的创新点是否显著且有实际意义?
在对比检测属性方法中,往往都将text视为一个整体,不考虑object-attribute和attribute之间的依赖关系,即使有,也不够有效,从生成句子的角度去建立依赖关系确实是一个创新点
理论和实证分析
8. 论文是否提供了足够的理论支持其方法?
9. 实验设计是否合理?
10. 实验结果是否支持论文的结论?
评估和比较
11. 论文是如何评估其方法的性能的?
应用和影响
12. 论文的方法有哪些局限性?
13. 有哪些潜在的问题或挑战需要进一步研究?
个人理解和应用
14. 这个方法是否可以应用到我的研究或工作中?
考虑建立有效的object-attribute和attribute之间依赖关系

 浙公网安备 33010602011771号
浙公网安备 33010602011771号