
论文阅读01-Improving Closed and Open-Vocabulary Attribute Prediction using Transformers
摘要
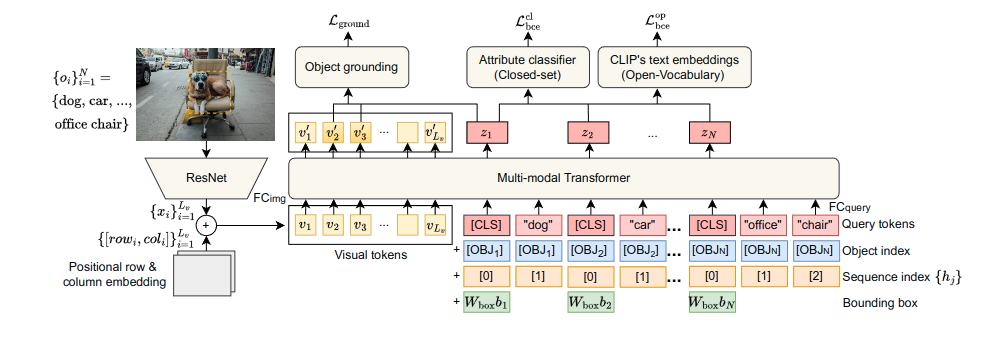
我们研究在视觉场景中识别对象的属性。我们将属性视为描述对象的物理和语义属性以及其与其他对象关系的任何短语。现有工作在封闭环境下研究属性预测,并使用一组固定的属性,实现了一个使用有限上下文的模型。我们提出了TAP,这是一个新的基于Transformer的模型,可以在单个前向传递中利用上下文并为场景中的多个对象预测属性,以及一个训练方案,允许该模型从图像-文本数据集中学习属性预测。在大型封闭属性基准VAW上的实验表明,TAP的mAP性能比SOTA高出5.1%。此外,通过利用预训练的文本嵌入,我们将模型扩展到OpenTAP,该模型可以识别训练过程中未见过的全新属性。在大规模设置中,我们进一步展示了OpenTAP可以预测大量已见过和未见过属性,其性能优于大规模视觉-文本模型CLIP,并且具有决定性的优势。
论文框架

 浙公网安备 33010602011771号
浙公网安备 33010602011771号