吴恩达-机器学习笔记-第四章多变量线性回归(Linear Regression with Multiple Variables)
参考:机器学习
笔记:
4.1 多维特征
- 一个含有多个变量的模型,模型中的特征为(𝑥1, 𝑥1, . . . , 𝑥𝑛):
![]() ,𝑥(𝑖)代表第 𝑖 个训练实例,是特征矩阵中的第𝑖行,是一个向量(vector)。
,𝑥(𝑖)代表第 𝑖 个训练实例,是特征矩阵中的第𝑖行,是一个向量(vector)。![]() (转置一下就是左图了)
(转置一下就是左图了) ![]() 代表特征矩阵中第 𝑖 行的第 𝑗 个特征,也就是第 𝑖 个训练实例的第 𝑗 个特征。
代表特征矩阵中第 𝑖 行的第 𝑗 个特征,也就是第 𝑖 个训练实例的第 𝑗 个特征。![]()
- 支持多变量的假设 ℎ 表示为:ℎ𝜃(𝑥) = 𝜃0 + 𝜃1𝑥1 + 𝜃2𝑥2+. . . +𝜃𝑛𝑥𝑛,这个公式中有𝑛 + 1个参数和𝑛个变量,为了使得公式能够简化一些,引入𝑥0 = 1,则公式转化为:ℎ𝜃(𝑥) = 𝜃0𝑥0 + 𝜃1𝑥1 + 𝜃2𝑥2+. . . +𝜃𝑛𝑥n
- 此时模型中的参数是一个𝑛 + 1维的向量,任何一个训练实例也都是𝑛 + 1维的向量,特征矩阵𝑋的维度是 𝑚 ∗ (𝑛 + 1)。 因此公式可以简化为:ℎ𝜃(𝑥) = 𝜃𝑇𝑋,其中上标𝑇代表矩阵转置
 ,𝑥(𝑖)代表第 𝑖 个训练实例,是特征矩阵中的第𝑖行,是一个向量(vector)。
,𝑥(𝑖)代表第 𝑖 个训练实例,是特征矩阵中的第𝑖行,是一个向量(vector)。 (转置一下就是左图了)
(转置一下就是左图了)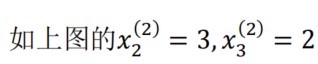
4.2 多变量梯度下降
- 与单变量线性回归类似,在多变量线性回归中,我们也构建一个代价函数,则这个代价函数是所有建模误差的平方和,即:𝐽(𝜃0, 𝜃1. . . 𝜃𝑛) =
![]() ,
, - 看链接吴恩达机器学习笔记9-多变量梯度下降
-
其中:ℎ𝜃(𝑥) = 𝜃𝑇𝑋 = 𝜃0 + 𝜃1𝑥1 + 𝜃2𝑥2+. . . +𝜃𝑛𝑥𝑛 ,我们的目标和单变量线性回归问题中一样,是要找出使得代价函数最小的一系列参数。多变量线性回归的批量梯度下降算法为:
![]()
即:![]()
求导数后得到:
![]() (xj(i))是怎么来的?ℎ𝜃(𝑥) = 𝜃𝑇𝑋 = 𝜃0 + 𝜃1𝑥1 + 𝜃2𝑥2+. . . +𝜃𝑛𝑥𝑛 ,求导来的,x是常数。
(xj(i))是怎么来的?ℎ𝜃(𝑥) = 𝜃𝑇𝑋 = 𝜃0 + 𝜃1𝑥1 + 𝜃2𝑥2+. . . +𝜃𝑛𝑥𝑛 ,求导来的,x是常数。当𝑛 >= 1时,
![]()
我们开始随机选择一系列的参数值,计算所有的预测结果后,再给所有的参数一个新的
值,如此循环直到收敛。
代码示例:![]()
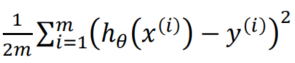 ,
,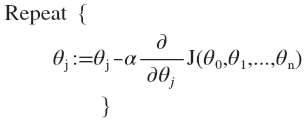
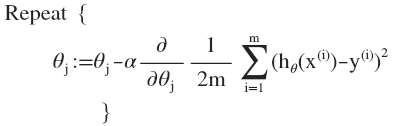
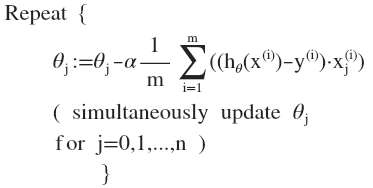 (xj(i))是怎么来的?ℎ𝜃(𝑥) = 𝜃𝑇𝑋 = 𝜃0 + 𝜃1𝑥1 + 𝜃2𝑥2+. . . +𝜃𝑛𝑥𝑛 ,求导来的,x是常数。
(xj(i))是怎么来的?ℎ𝜃(𝑥) = 𝜃𝑇𝑋 = 𝜃0 + 𝜃1𝑥1 + 𝜃2𝑥2+. . . +𝜃𝑛𝑥𝑛 ,求导来的,x是常数。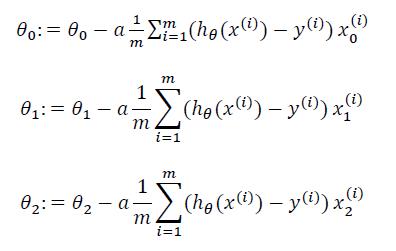

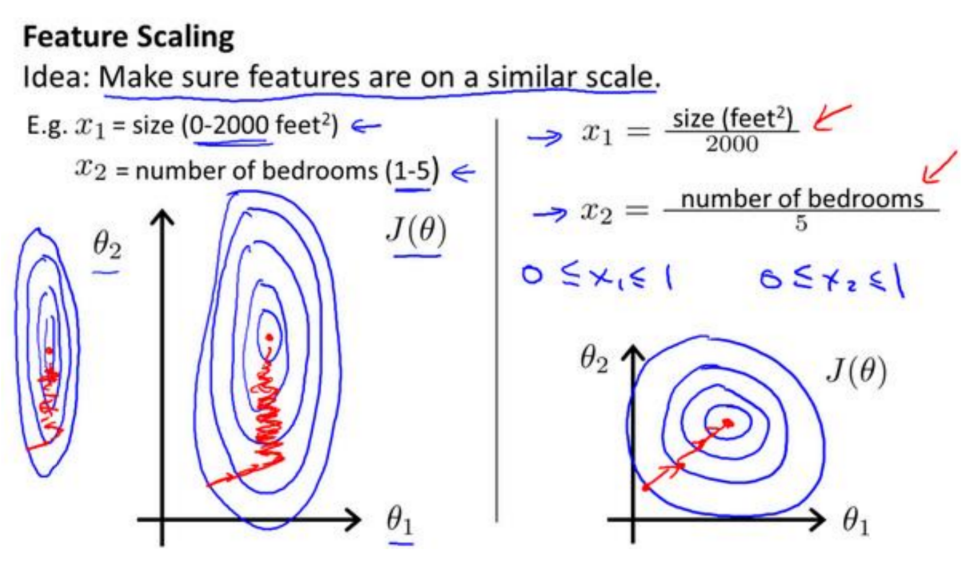
4.3 梯度下降法实践 1-特征缩放
- 在我们面对多维特征问题的时候,我们要保证这些特征都具有相近的尺度(所以需要特征缩放),这将帮助梯度下降算法更快地收敛。
- 解决的方法是尝试将所有特征的尺度都尽量缩放到-1 到 1 之间。
![]()
- 最简单的方法是令:
![]() ,其中 𝜇𝑛是平均值,𝑠𝑛是标准差。
,其中 𝜇𝑛是平均值,𝑠𝑛是标准差。
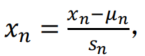 ,其中 𝜇𝑛是平均值,𝑠𝑛是标准差。
,其中 𝜇𝑛是平均值,𝑠𝑛是标准差。
4.4 梯度下降法实践 2-学习率
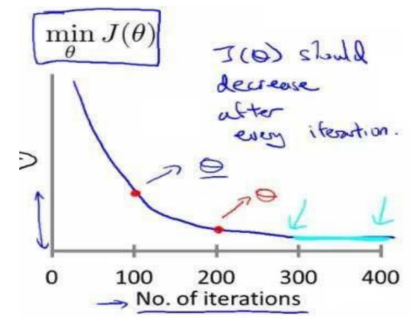
- 梯度下降算法收敛所需要的迭代次数根据模型的不同而不同,我们不能提前预知,我们可以绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛。
![]()
- 梯度下降算法的每次迭代受到学习率的影响,如果学习率𝑎过小,则达到收敛所需的迭 代次数会非常高;如果学习率𝑎过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。 通常可以考虑尝试些学习率: 𝛼 = 0.01,0.03,0.1,0.3,1,3,10
4.5 特征和多项式回归
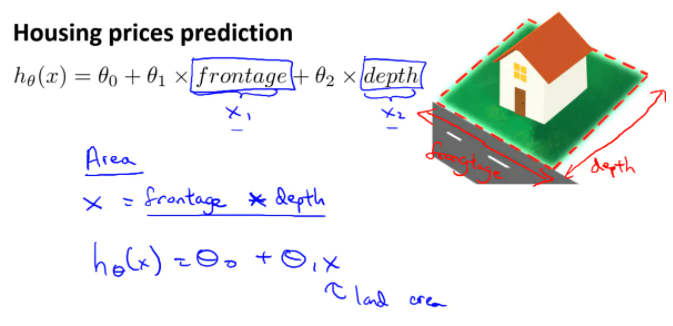
- 首先,我们需要选择合适的特征。 例如有房子临街宽度和垂直宽度,使用这两个特征不如创造新的特征——面积,即面积这个新的特征能更好决定房子价格。有的时候不直接使用给的特征,反而使用自己创造的新的特征,可能会得到一个更好的模型。
![]()
- 线性回归并不适用于所有数据,有时我们需要曲线来适应我们的数据,比如一个二次方模型
![]()
- 或者三次方模型:
![]()
- 另外,我们可以令:𝑥2 = 𝑥22, 𝑥3 = 𝑥33,从而将模型转化为线性回归模型。
- 注:如果我们采用多项式回归模型,在运行梯度下降算法前,特征缩放非常有必要。
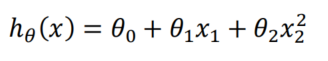

4.6 正规方程(标准方程)
- 到目前为止,我们都在使用梯度下降算法,但是对于某些线性回归问题,正规方程方法是更好的解决方案:
![]()
- 正规方程(标准方程)是通过求解下面的方程来找出使得代价函数最小的参数的:
![]() 。 假设我们的训练集特征矩阵为 𝑋(包含了 𝑥0 = 1)并且我们的训练集结果为向量 𝑦,则利用正规方程解出向量 𝜃 = (𝑋𝑇𝑋)−1𝑋𝑇𝑦 。
。 假设我们的训练集特征矩阵为 𝑋(包含了 𝑥0 = 1)并且我们的训练集结果为向量 𝑦,则利用正规方程解出向量 𝜃 = (𝑋𝑇𝑋)−1𝑋𝑇𝑦 。 - 正规方程的使用
- 梯度下降与正规方程的比较:
![]() 。
。 - 只要特征变量的数目并不大,标准方程是一个很好的计算参数𝜃的替代方法。 具体地说,只要特征变量数量小于一万,通常使用标准方程法,而不使用梯度下降法。
- 随着我们要讲的学习算法越来越复杂,例如,当我们讲到分类算法,像逻辑回归算法, 我们会看到,实际上对于那些算法,并不能使用标准方程法。对于那些更复杂的学习算法, 我们将不得不仍然使用梯度下降法。因此,梯度下降法是一个非常有用的算法,可以用在有 大量特征变量的线性回归问题。对于特定的线性回归模型,标准方程法是一个 比梯度下降法更快的替代算法。所以,根据具体的问题,以及你的特征变量的数量,这两种算法都是值得学习的。

 。 假设我们的训练集特征矩阵为 𝑋(包含了 𝑥0 = 1)并且我们的训练集结果为向量 𝑦,则利用正规方程解出向量 𝜃 = (𝑋𝑇𝑋)−1𝑋𝑇𝑦 。
。 假设我们的训练集特征矩阵为 𝑋(包含了 𝑥0 = 1)并且我们的训练集结果为向量 𝑦,则利用正规方程解出向量 𝜃 = (𝑋𝑇𝑋)−1𝑋𝑇𝑦 。 。
。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号