网络3️⃣TCP-可靠性-窗口
1、滑动窗口
1.1、窗口
TCP 的数据单位是段(segment)
如果每发送一个段就需要进行一次
ACK处理,通信性能差。
窗口:ACK 以窗口大小为单位,而不是以段为单位。
- 窗口大小:无需等待
ACK,而可以发送数据的最大值。 - 窗口实现:操作系统开辟的一个缓冲区(
Buffer)。- 发送方主机:在收到 ACK 之前,需要在缓冲区中保留已发送的数据。
- 接收方主机:在收到乱序的数据时,在缓冲区中保留这部分数据。
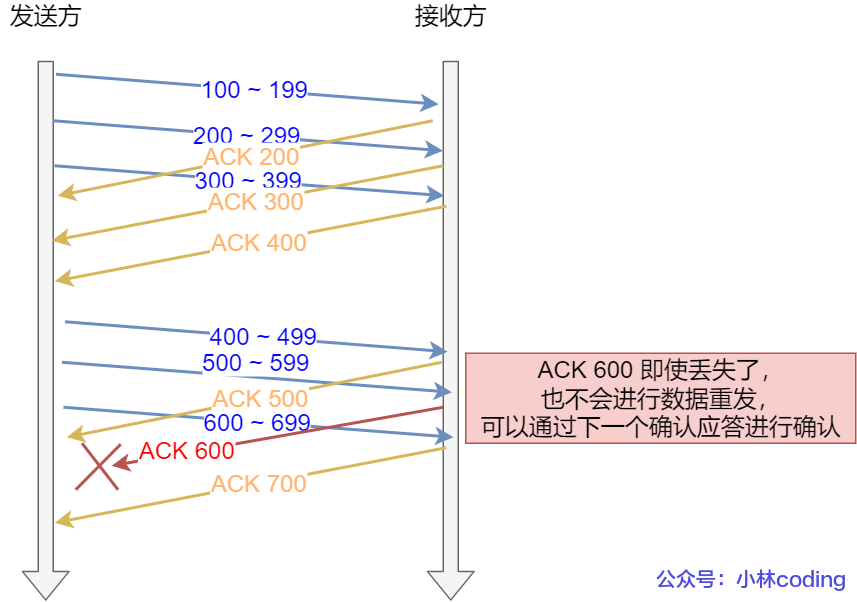
累计应答(aka. 累计确认):
在窗口中的数据即使某个 ACK 丢失,发送方可以根据下一个 ACK 进行确认。
示例:假设窗口大小 = 3 个 TCP 段。
-
发送方可以连续发送
3个段,接收方回复的某个 ACK 报文丢失。 -
发送方可以通过后面的 ACK,确认之前的所有数据都已被接收。
1.2、滑动窗口
1.2.1、发送方
四区三针
根据数据处理情况,分为四部分。
-
#1:已发送,已收到 ACK。 -
发送窗口:假设 20 个字节,包括两部分数据。
#2:已发送,未收到 ACK。#3:未发送,大小在接收方处理范围内(可发送)。
-
#1:未发送,大小超过接收方处理范围(无法发送)。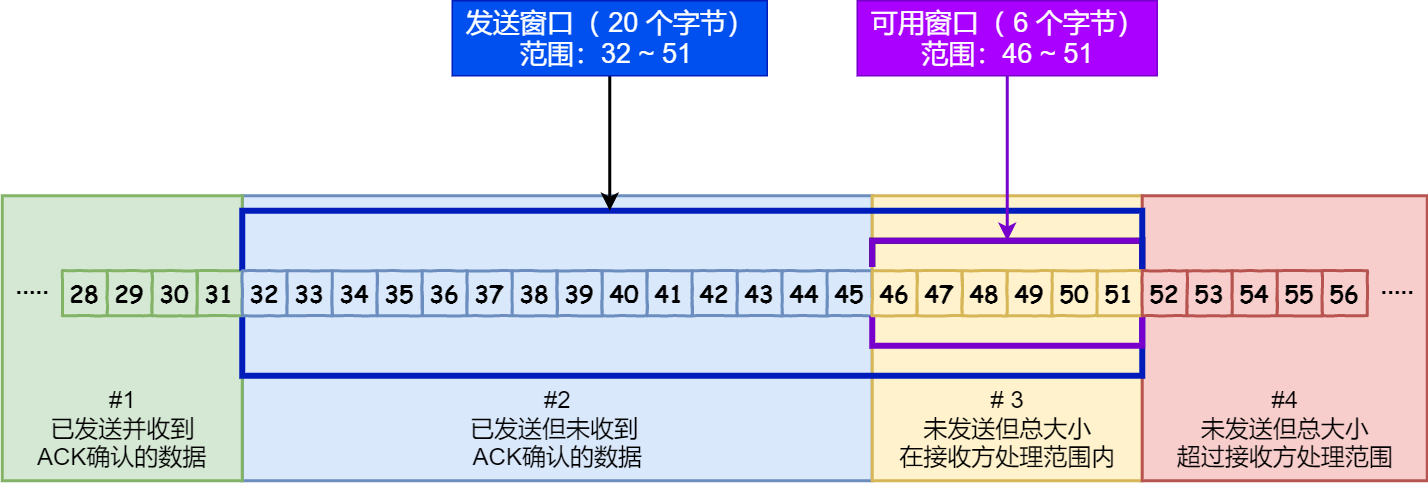
收到
ACK报文后,将窗口滑动到确认应答号的位置。
程序表示-指针
程序是如何表示发送方的四个部分的呢?
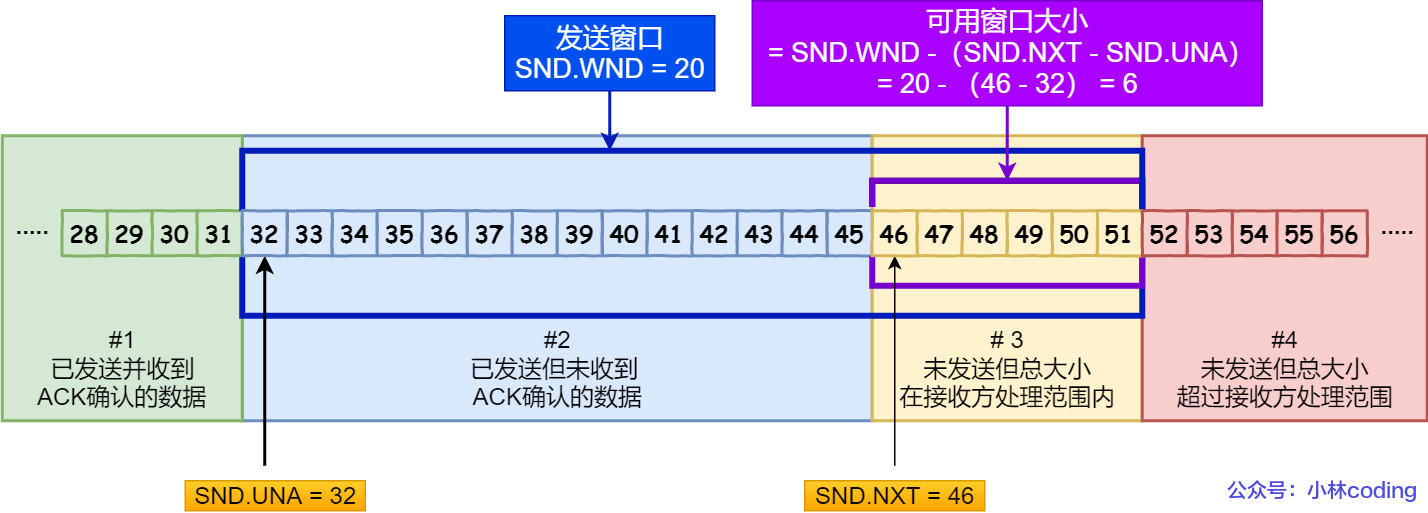
TCP 滑动窗口中,使用 3 个指针来跟踪在四个传输类别中的字节。
-
2 个绝对指针:指向特定的序列号。
SND.UNA(Send Unacknoleged):指向已发送但未收到 ACK 的首个字节的序列号(滑动窗口的首个)。SND.NXT(Send Next):指向未发送但可发送的首个字节的序列号(可用窗口的首个)。
-
1 个相对指针:需要做偏移。
SND.WND(Send Window):表示发送窗口的大小,由接收方指定。
-
计算公式:
- UNA + SND = 未发送且无法发送的首个字节的序列号。
- 可用窗口大小 = SND.WND -(SND.NXT - SND.UNA)
1.2.2、接收方
三区二针
根据数据处理情况,分为三部分。
-
#1, #2:已接收,已确认(等待应用进程读取)。 -
接收窗口:
#3:未收到,可接收。
-
#4:未收到,不可接收。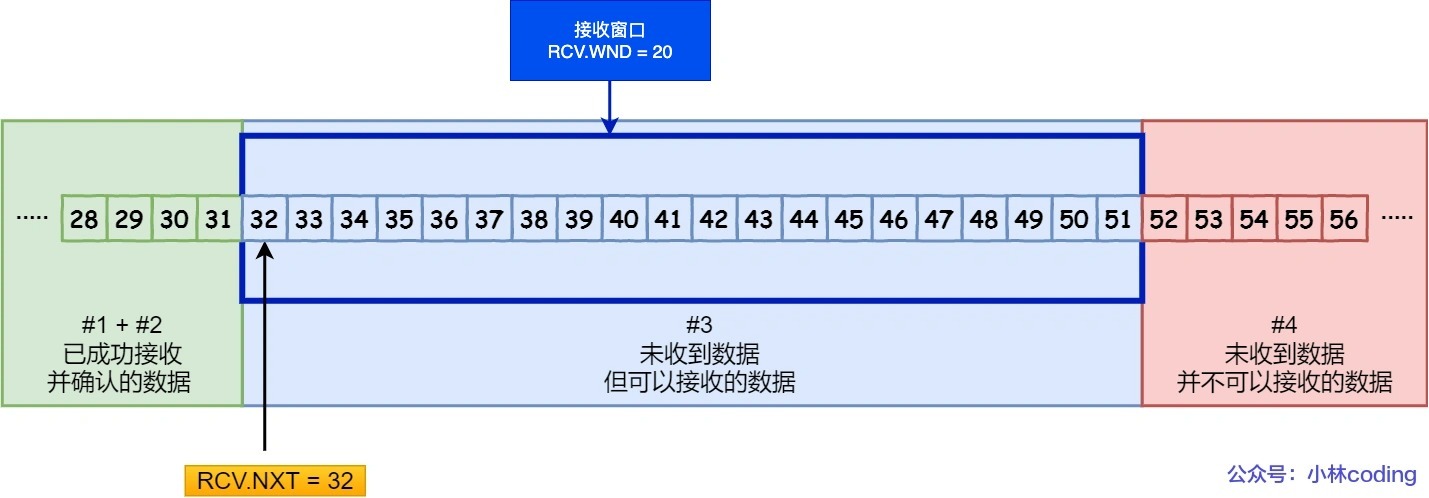
程序表示-指针
- 1 个绝对指针:指向特定的序列号。
RCV.NXT(Receive Unacknoleged):指向未收到但可接收的首个字节的序列号(接收窗口的首个,i.e. 期望收到的下一个数据字节的序列号)。
- 1 个相对指针:需要做偏移。
RCV.WND(Receive Window):表示接收窗口的大小。
- 计算公式:NXT + WND = 未收到数据且不可接收的首个字节的序列号。
1.2.3、接收窗口=发送窗口?
接收窗口和发送窗口接近,但不完全相等。
原因:
- 滑动窗口是一直在改变的。
- 接收窗口大小(
Window)是通过 TCP 报文传输告知的,存在时延。
2、流量控制
流量控制(aka. 流控制):发送方根据接收方的实际接收能力,控制发送的数据量。
实现:TCP 首部的 Window 字段。
- 接收方:将自己接收缓冲区的大小放入
Window字段(i.e. 窗口大小),告知发送端。 - 发送方:根据
Window值调整发送缓冲区的大小,发送的数据不超过窗口大小。
2.1、缓冲区调整
发送方和接收方的缓冲区均由操作系统分配,因此操作系统会调整缓冲区大小。
可能情况:
-
接收方的应用程序没有及时读取缓存。👉 缓冲区大小不变,但
Window不断缩小,甚至发生窗口关闭。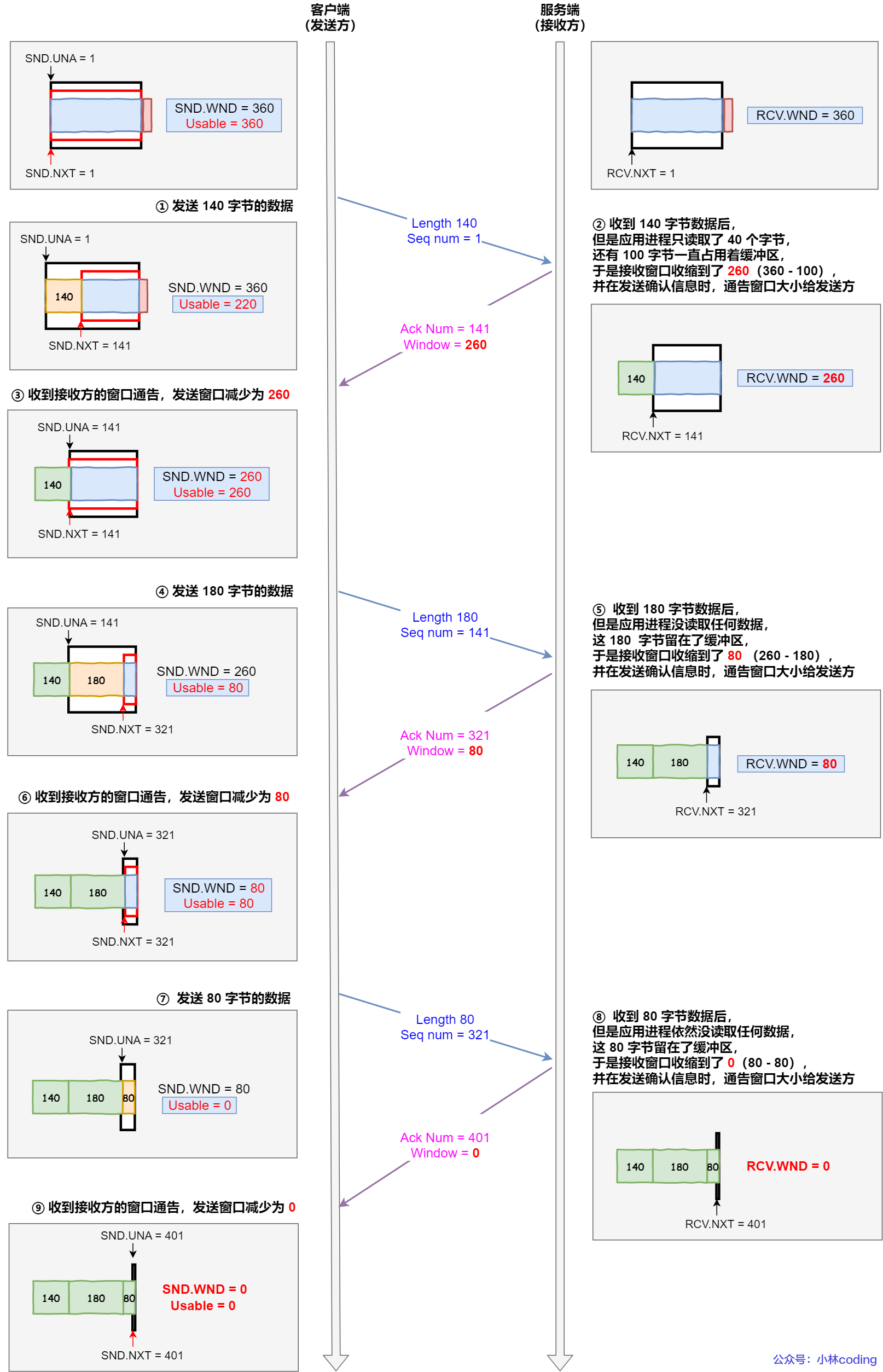
-
接收方的系统资源紧张。👉 缓冲区大小被操作系统减少,容易发生丢包。
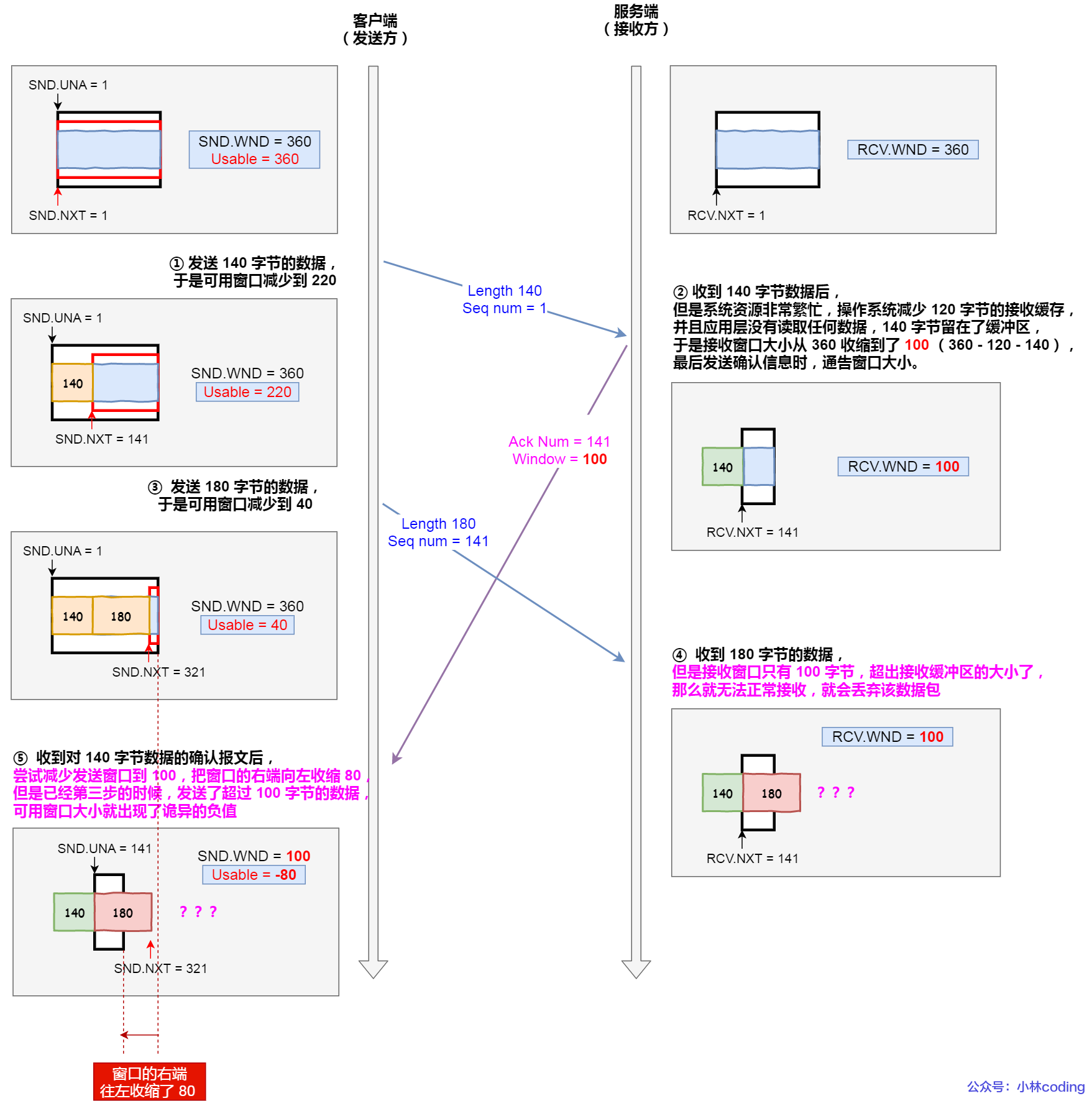
在情况 2 中,先减少缓存、后收缩窗口,就会导致丢包。
TCP 规定:
- 不允许同时减少缓存和收缩窗口。
- 采用先收缩窗口,过段时间再减少缓存,从而避免丢包。
2.2、窗口关闭
窗口关闭:当窗口大小为 0,发送方就会停止发送数据。
直到得知窗口变为非 0。
- 存在风险:死锁
- 对策:窗口探测
2.2.1、死锁
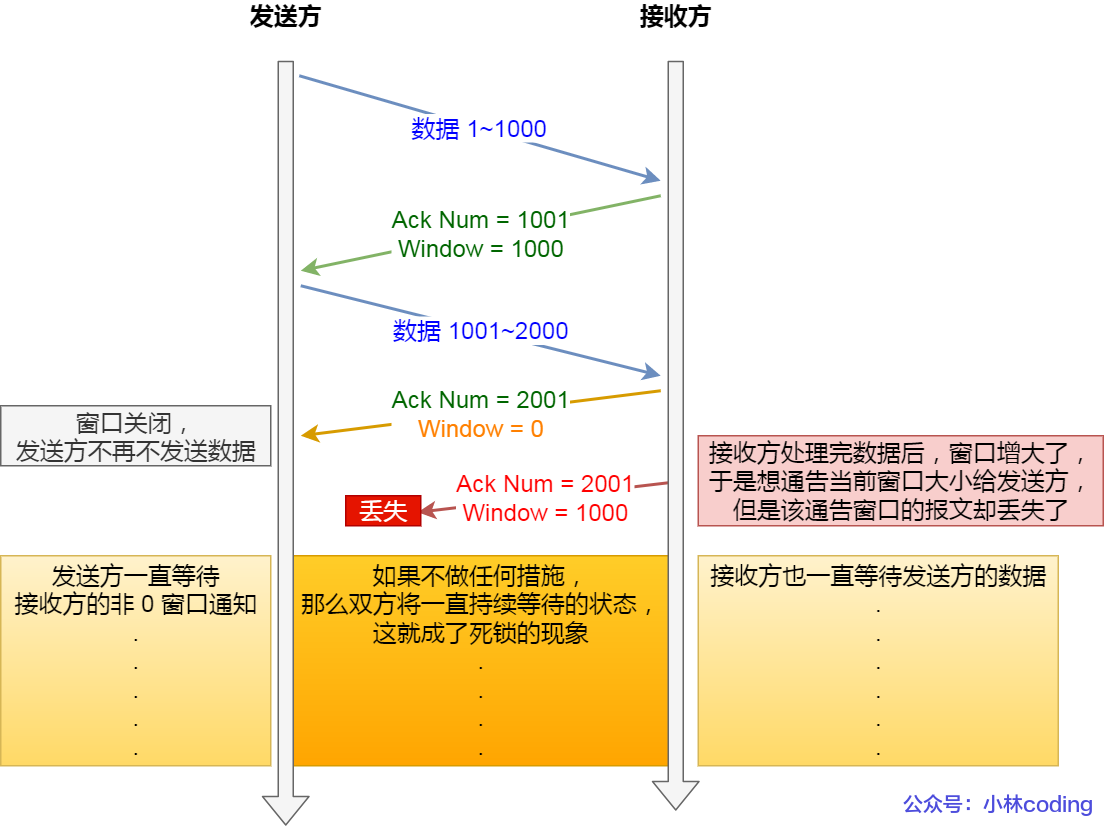
假设发生窗口关闭一段时间后,接收方已恢复接收能力。
-
接收方:需要通过
ACK报文,通告发送方Window大小。 -
发送方:窗口关闭后会停止发送数据,直到接收到
Window非 0 的 ACK 报文。 -
如果此 ACK 报文丢失,发送方和接收方会相互等待,造成死锁。
2.2.2、窗口探测
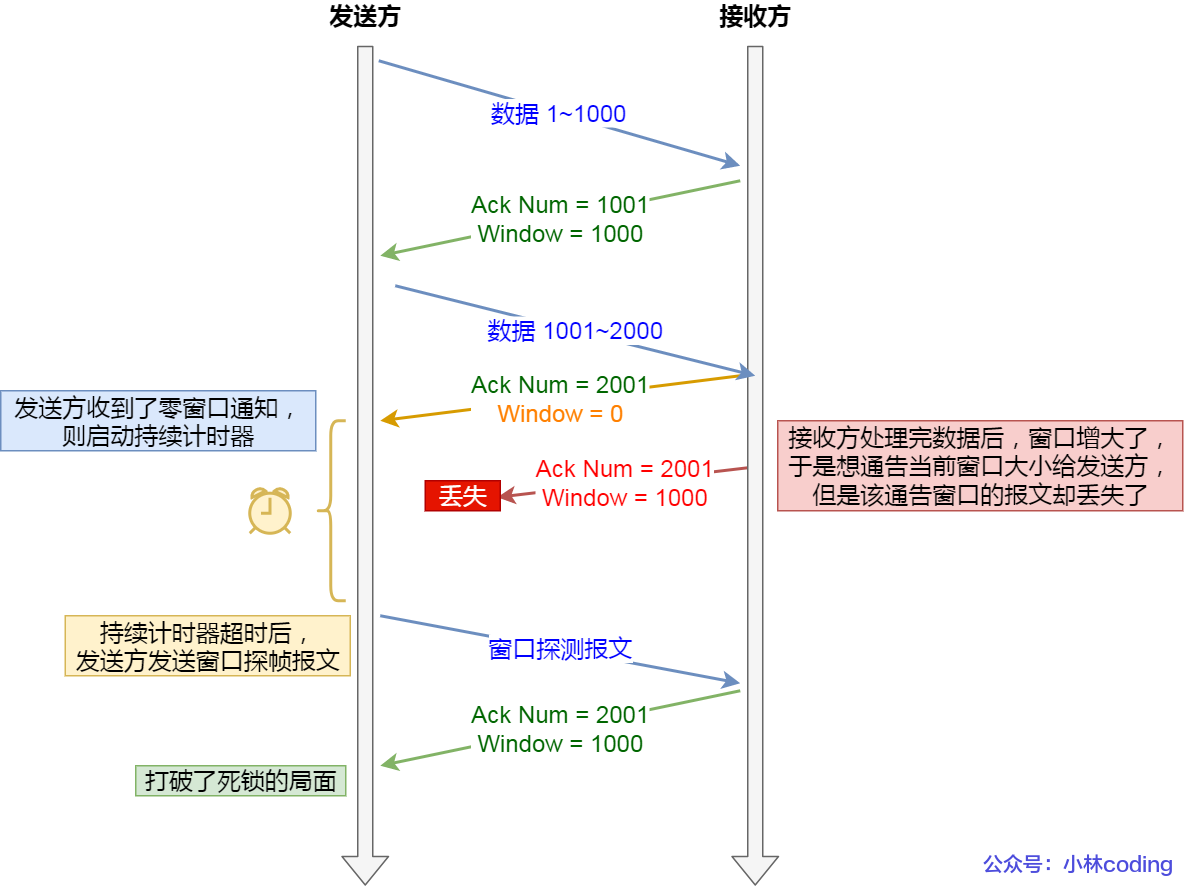
持续计时器:TCP 为每个连接设置一个持续计时器,当其中一方收到对方的零窗口通知时启动。
窗口探测(Window probe):探测包仅含一个字节。
-
探测机制:当持续计时器超时后,发送方会发送窗口探测报文,以获取最新的窗口大小。
- 为 0:重置持续计时器。
- 非 0:继续发送数据。
-
探测次数:一般为 3 次。
- 每次大约 30-60s(不同的实现可能不同)。
- 如果 3 次过后接收窗口仍为 0,有些 TCP 实现会发
RST报文来中断连接。
2.3、糊涂窗口综合症
Silly Window Syndrome:当发送方发送数据缓慢,或接收方读取数据缓慢,或二者兼有。
会导致通信中传送的数据(有效载荷)很小,但传输开销(首部信息)很大。
e.g. 数据只有 1 字节,开销需要 40 字节(IP 首部 20 + TCP 首部 20)
如何避免:同时满足以下条件。
- 接收方不通告小窗口
- 发送方不发送小数据
① 接收方不通告小窗口
接收方策略:对比
窗口大小和min{MSS, 缓存空间/2}(i.e. MSS 和 1/2 缓存空间中的较小值)
- 当
窗口大小 < min{...}时认为是小窗口,通告窗口为 0。 - 处理部分数据后,当
窗口大小 >= min{...},通告当前实际窗口大小(非 0)。
② 发送方不发送小数据
发送方策略:Nagle 算法(延迟处理思想)
至少满足以下条件之一才可发送数据,否则一直囤积数据。
-
窗口大小和数据大小均
>= MSS。 -
收到已发送数据的
ACK确认报文。// 伪代码 if 有数据要发送 { if 可用窗口大小 >= MSS and 可发送的数据 >= MSS { 立刻发送MSS大小的数据 } else { if 有未确认的数据 { 将数据放入缓存等待接收ACK } else { 立刻发送数据 } } }
Nagle 算法说明
-
使用前提:接收方不通告小窗口,否则用于通告的 ACK 报文很容易满足上述条件 2。
-
开启/关闭:Nagle 算法默认开启。
-
对于需要小数据包交互场景的程序(e.g. Telnet, SSH),则需关闭。
-
没有全局参数用于关闭 Nagel 算法,需要根据应用特点来关闭(e.g. Socket 的
TCP_NODELAY选项)。setsockopt(sock_fd, IPPROTO_TCP, TCP_NODELAY, (char *)&value, sizeof(int));
-
结论:接收方不通告小窗口 + 发送方开启 Nagel,才能避免糊涂窗口综合征
3、拥塞控制
流量控制和拥塞控制都是为了避免发送方发送的数据过多,但侧重点不同。
- 流量控制:避免数据填满接收方缓冲区。
- 拥塞控制:避免数据填满整个网络。
- 计算机网络处在一个共享的环境,可能会因为其他主机之间的通信使得网络拥堵。
- 在网络拥堵时,继续发送大量数据包可能会导致时延、丢失等,进而触发重传机制。
- 重传机制会进一步加剧网络拥堵,陷入恶性循环......
3.1、拥塞窗口
cwnd(Congestion Window):发送方维护的状态变量,用于调节发送方所发送的数据量。
- cwnd 大小:不会使网络拥塞的窗口大小。
- 变化规律:根据网络拥塞程度动态变化。
- 网络没有出现拥塞:cwnd 增大.
- 网络出现拥塞:cwnd 减小。
- 判定网络拥塞:发送方触发超时重传(没有在规定时间内收到 ACK 报文),就认为网络出现拥塞。
cwnd 和 swnd 的关系
- 假如没有 cwnd,发送窗口(swnd)约等于接收窗口(rwnd)。
- 引入 cnwd 后,发送窗口 swnd = min{cwnd, rwnd},避免数据填满网络和接收方填充区。
3.2、拥塞控制算法
- 慢启动
- 拥塞避免
- 拥塞发生
- 快速恢复
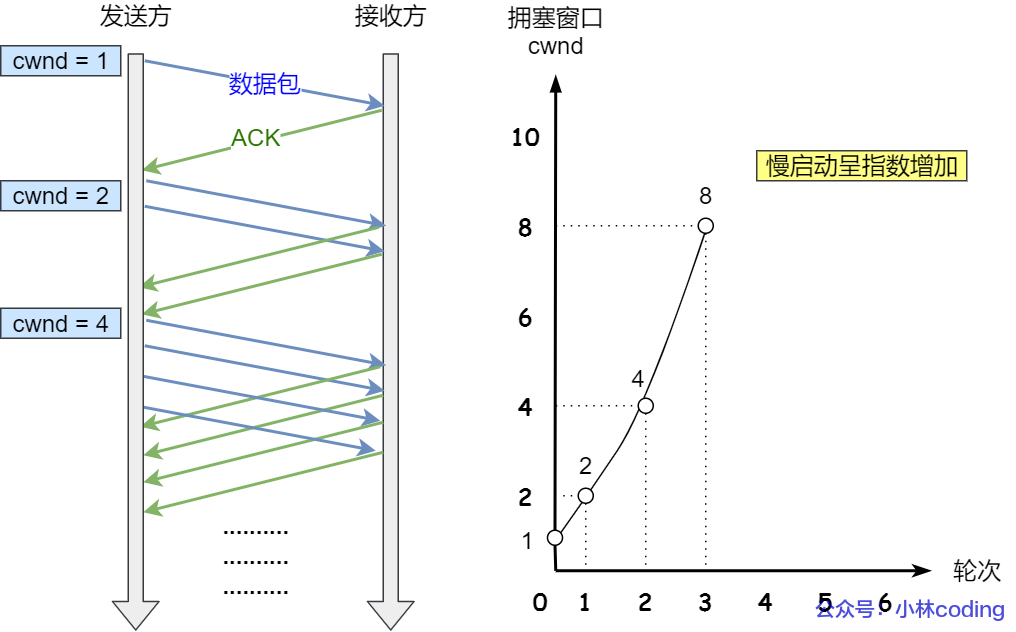
① 慢启动
Slow Start:一点点的提高发送数据包的数量。
-
规则:初始
cwnd = 1MSS,每收到一次 ACK 报文cwnd + 1。 -
特点:cwnd 呈指数增长。
慢启动阈值
ssthresh (slow start threshold):发送方维护的另一个状态变量。
通常是
65535字节。
cwnd < ssthresh时:使用慢启动算法,cwnd 每次 +1。cwmd >= ssthresh时,使用拥塞避免算法,cwnd 每次 +1/cwnd。
ssthresh的值在触发重传时更新。
超时重传和快速重传时触发的算法不同,设置的值也不同。👇具体见下文
- 超时重传:触发拥塞发生算法,
ssthresh = cwnd / 2。 - 快速重传:触发快速恢复算法,
ssthresh = cwnd / 2且cwnd = ssthresh + 3。
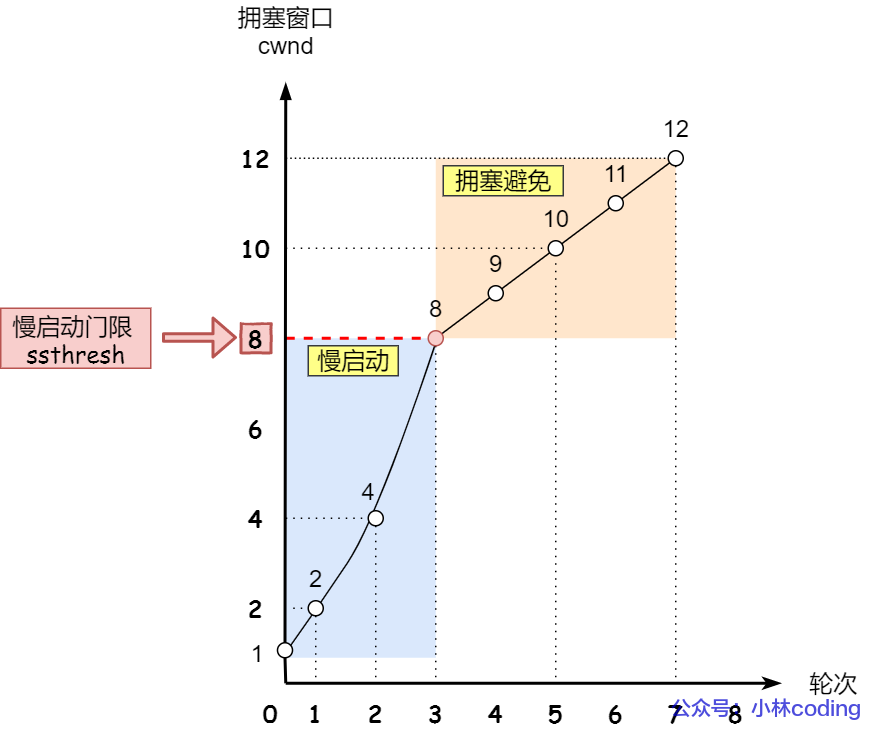
② 拥塞避免
Congestion Avoidance
- 规则:每收到一次 ACK 报文
cwnd增加1/cwnd。 - 特点:cwnd 呈线性增长。
假设
ssthresh = 8,每个 ACK 增加 1/8
-
收到 8 个 ACK 之前,只能发送 8MSS 数据。
-
收到 8 个 ACK 之后,ssthresh = 9,可以发送 9MSS 数据。
-
以此类推,线性增长。
③ 拥塞发生
发生超时重传时,会触发拥塞发生算法。
变化如下:
-
ssthresh = cwnd / 2 -
cwnd = 初始值- i.e. 拥塞算法后会重新开始慢启动。
- Linux 的初始值是
10MMS,可通过ss -nli指令查看每个 TCP 连接的 cwnd 初始值。

图示(假设 ssthresh 初始值为8,cwnd 初始值为 1)
假设在第 7 轮发生超时重传,此时 cwnd = 12。
-
更新 ssthresh = cwnd / 2 = 6
-
更新 cwnd = 1
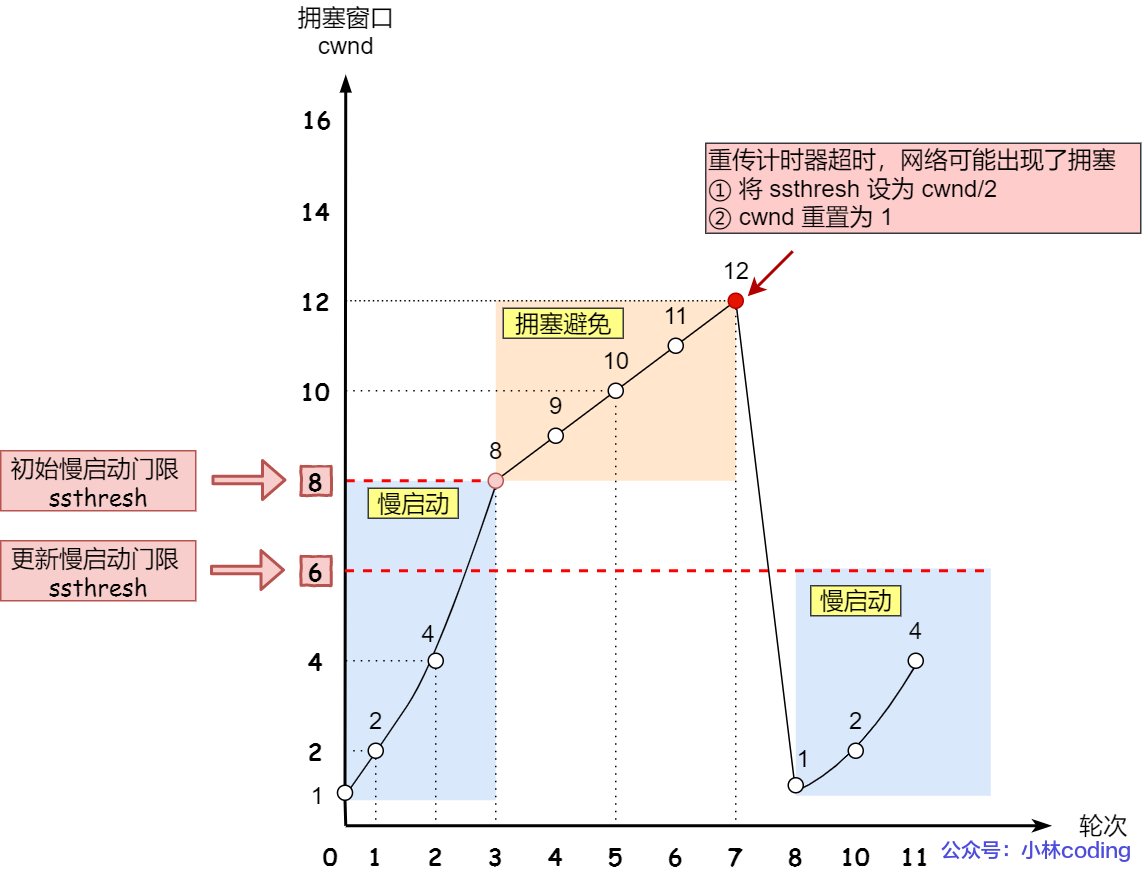
一旦发生超时重传,cwnd 急剧减少,容易造成网络卡顿。
更好的方法是快速重传+快速回复。
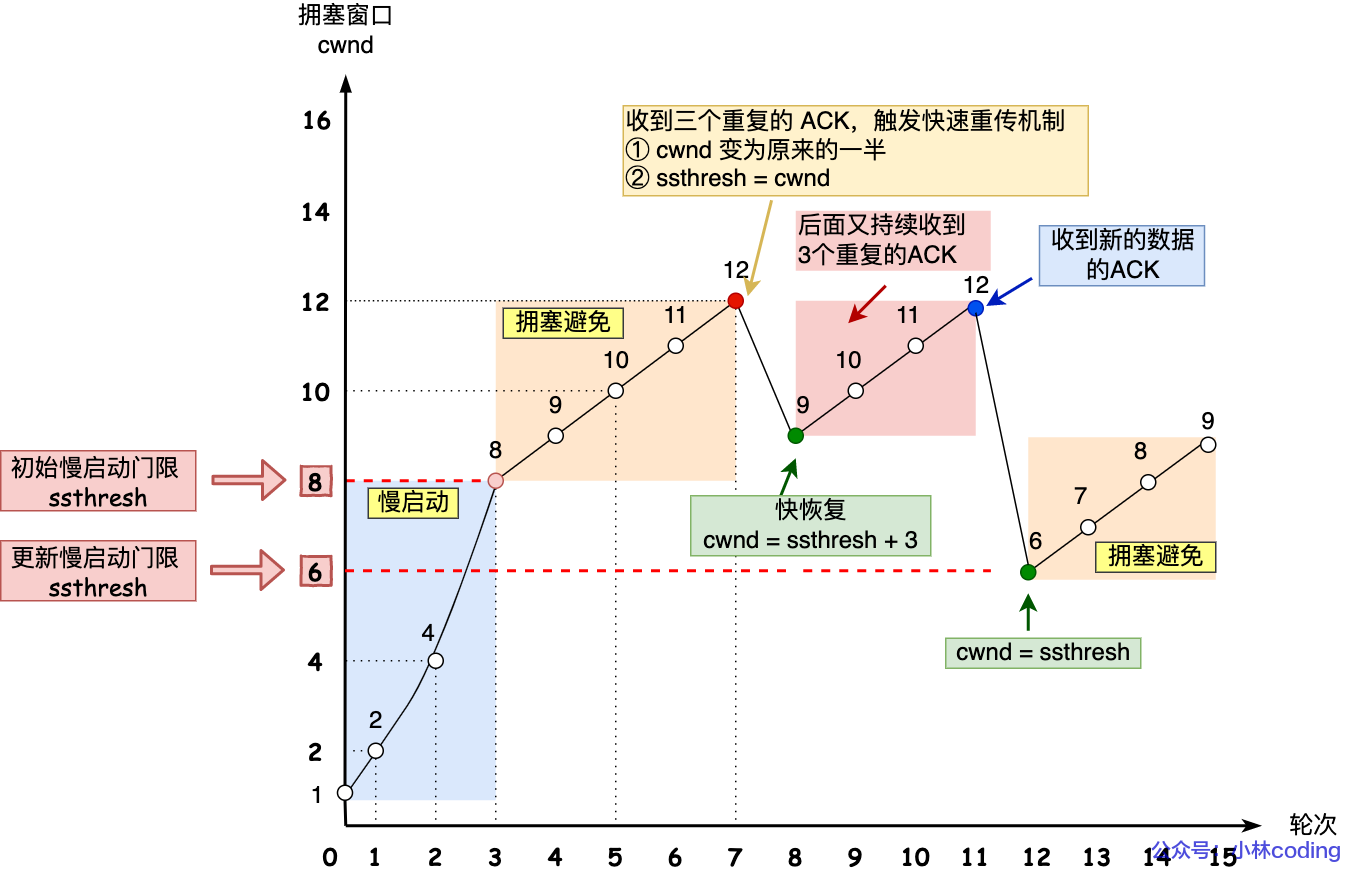
④ 快速恢复
当发生快速重传时,会触发快速恢复算法。
变化如下:
ssthresh = cwnd / 2cwnd = ssthresh + 3- 发生快速重传时,接收方已经收到 3 个相同的 ACK 报文,意味着网络中已经消失了 3 个报文。
- 因此接收方可以多发送 3 个报文,即 cwnd 可增加 3MMS。
更新 ssthresh 和 cwnd 时,也会重传丢失的包。
-
又收到重复的 ACK:cwnd + 1,如果达到 3 次再次触发快速重传+快速恢复。
-
收到新数据的 ACK:快速恢复结束,
cwnd = ssthresh。-
也就是说,快速恢复后回到拥塞避免(而不是从慢启动开始)。
-


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)