MySQL8️⃣SQL 优化
1、插入数据
1.1、说明
- 场景:需要一次性插入多条记录,使用 INSERT 逐条插入数据的效率低。
- 优化:
- 多条数据:优化 LIMIT
- 大批数据:LOAD
1.2、优化
1.2.1、INSERT
场景:需要一次性插入多条记录(< 1000 条)
-
批量插入:VALUES 多条记录。
-
手动提交事务:避免事务的频繁提交。
-
主键顺序插入:主键按顺序插入的效率高于乱序插入。
# 批量插入 INSERT INTO tb_user(id, name) VALUES(1,'Alice'), (2,'Bob'), (3,'Cindy'); # 手动提交事务 START TRANSACTION; INSERT INTO tb_user(id, name) VALUE(1,'Alice'); INSERT INTO tb_user(id, name) VALUE(2,'Bob'); INSERT INTO tb_user(id, name) VALUE(3,'Cindy'); COMMIT;
1.2.2、LOAD
场景:需要一次性插入大批量记录。
-
连接服务器:添加参数
mysql --local-infile -u root -p -
开启导入数据:
# 查看状态 SELECT @@local_infile; # 开启 SET GLOBAL local_infile = 1; -
加载数据:
# 格式 LOAD DATA LOCAL INFILE '数据文件路径' INTO TABLE 表名 FIELDS TERMINATED BY '字段分隔符' LINES TERMINATED BY '行分隔符'; # 示例 LOAD DATA LOCAL INFILE '/root/sql_data.log' INTO TABLE `tb_user` FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';
2、主键
2.1、说明(❗)
索引组织表(IOT, Index Organized Table)
表的数据按主键顺序组织存放。
基于 InnoDB 的表是 IOT。
- 结构特点:
- 行数据存储在聚集索引的叶节点上。
- 数据行记录在逻辑结构 page 中,每个 page 大小固定,默认 16K。
- 规定每个 Page 包含 2~N 行数据,根据主键排列(如果某行数据过大,会行溢出)。
- 操作特点:
- 页分裂,页合并
- 逻辑删除:被删除的记录并不会被物理删除。而是被标记(flaged)且空间允许被其它记录声明使用。
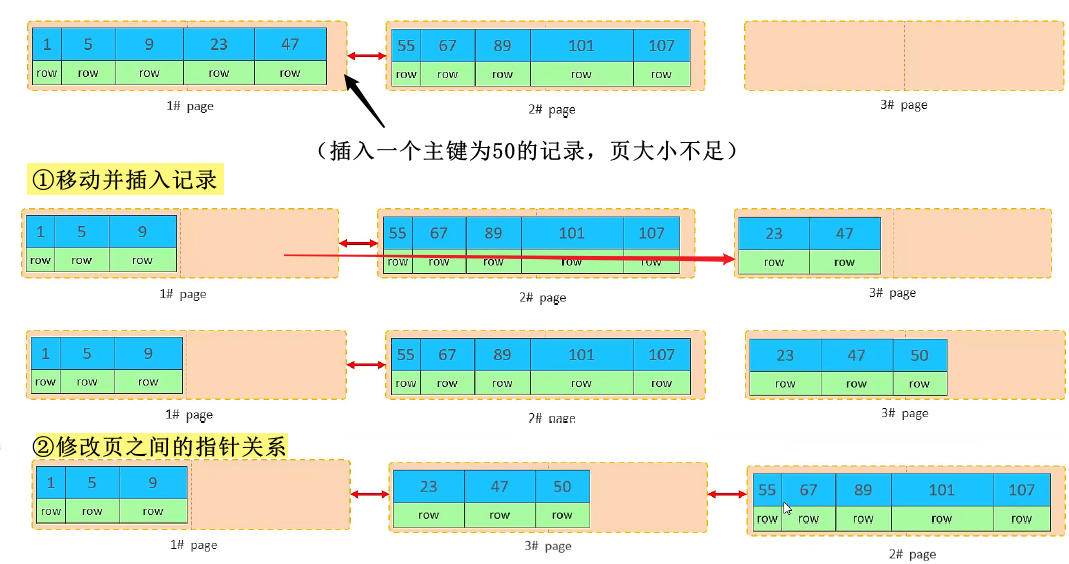
2.1.1、页分裂
场景:Page 内存不足。
若插入的记录在该页存储不下,将会存储到下一个 Page 中,Page 之间通过指针连接。
步骤:
-
将 Page 的后半部分记录移动到一张新 Page 中,将新记录插入到新的 Page。
-
修改 Page 之间的指针关系。
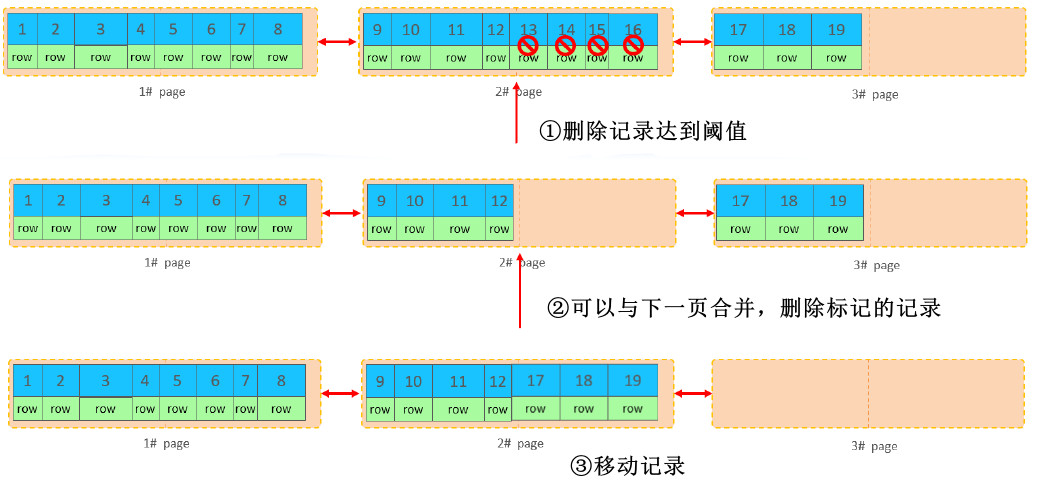
2.1.2、页合并
场景:删除记录达到阈值。
Page 中删除的记录达到阈值时,InnoDB 会寻找相邻 Page(前/后)并尝试合并。
MERGE_THRESHOLD:合并页的阈值(默认页的 50%),可在创建表或创建索引时指定。
步骤:
-
删除的记录达到阈值,查看相邻页是否可以合并。
-
若可以合并,将标记为删除的记录物理删除。
-
移动记录进行页合并。
2.2、优化(❗)
主键索引设计原则
- 满足业务需求的情况下,尽量降低主键长度(尽量不使用 UUID,身份证等)
- 尽量顺序插入,优先使用 AUTO_INCREMENT 自增主键。
- 业务操作时,避免修改主键。
Hint:实际开发中,通常使用逻辑主键和业务主键。
- 逻辑主键:AUTO_INCREMENT 自增主键,用于区分每一条数据库记录。
- 业务主键:能唯一标识业务实体的键,如用户 ID,员工 ID,学号等。
3、ORDER BY
3.1、说明
3.1.1、排序方式(❗)
MySQL 排序方式
Using index:通过有序索引顺序扫描,直接返回有序数据。Using filesort:通过索引(或全表扫描)读取满足条件的数据行,在排序缓冲区(sort buffer)中完成排序操作。
3.1.2、示例
创建索引
-
无索引:以 Using filesort 方式排序。
-
创建索引:以 Using index 方式排序(默认升序)
# 没有指定排序方式,默认为升序 CREATE INDEX idx_user_age_phone ON tb_user(age, phone);
排序查询:
观察不同情况下的排序方式
Hint:记遵守 = 最左前缀法则,相同/相反 = 排序顺序(ASC/DESC)。
-
遵守:Using index
SELECT id, age, phone FROM tb_user ORDER BY age; SELECT id, age, phone FROM tb_user ORDER BY age, phone; -
不遵守:Using filesort
SELECT id, age, phone FROM tb_user ORDER BY phone; SELECT id, age, phone FROM tb_user ORDER BY phone, age; -
遵守、相反:Using index + Backward index scan
# 索引 ASC, ASC,查询 DESC, DESC SELECT id, age, phone FROM tb_user ORDER BY age DESC, phone DESC; -
遵守、部分相反:Using index + Using filesort
# 索引 ASC, ASC,查询 ASC, DESC SELECT id, age, phone FROM tb_user ORDER BY age, phone DESC; # 解决方案:创建相应排序顺序的索引 CREATE INDEX idx_user_age_phone_ad ON tb_user(age ASC, phone DESC);
3.2、优化(❗)
目标:Using index
-
建立索引:
- 根据排序字段建立合适的索引。
- 尽量使用覆盖索引。
-
多字段排序:
- 遵循最左前缀法则。
- 注意联合索引的排序规则(ASC / DESC)。
-
缓冲区:若无法避免 filesort,适当增加排序缓冲区大小(sort_buffer_size,默认 256K)。
4、GROUP BY
4.1、说明
4.1.1、分组方式(❗)
MySQL 分组方式
Using index:索引Using temporary:临时表
4.1.2、示例
创建索引
-
无索引:以 Using temporary 方式排序。
-
创建索引:以 Using index 方式排序。
CREATE INDEX idx_user_prof_age ON tb_user(profession, age);
分组查询:
观察不同情况下的分组方式
Hint:记遵守 = 最左前缀法则。
-
遵守:Using index
SELECT profession, COUNT(*) FROM tb_user GROUP BY profession; SELECT profession, COUNT(*) FROM tb_user GROUP BY profession, age; SELECT profession, COUNT(*) FROM tb_user WHERE profession = '计算机科学' GROUP BY age; -
不遵守:Using temporary
SELECT profession, COUNT(*) FROM tb_user GROUP BY age;
4.2、优化(❗)
目标:Using index
-
建立索引:
- 为分组条件字段建立索引。
- 尽量使用覆盖索引。
-
多字段:遵循最左前缀法则。
5、LIMIT
5.1、说明(❗)
LIMIT 现象:
- 现象:大数据量的数据库表,越往后查询效率越低。
- 执行原理:SQL 的执行过程(LIMIT offset size)
- 从表中读取 size 条记录,重复直到读取 offset + size 条。
- 丢弃前面 offset 条记录。
- 返回余下的 size 条记录。
- 优化:效率从低到高。
- 自增索引
- 覆盖索引 + 子查询
- 覆盖索引 + 内连接
5.2、优化
5.2.1、自增索引
-
示例:分页查询
SELECT * FROM tb_user LIMIT 1000000, 10; -
优化:使用主键索引,迅速定位 id=1000000 的记录,取代全表扫描。
SELECT * FROM tb_user WHERE id > 1000000 LIMIT 10;
分析:
- 必须包含自增索引,且数据必须连续(不能中断)。
- 仅支持简单分页,不能添加其它 WHERE 条件。
5.2.2、覆盖索引 + 子查询
-
示例:条件 + 分页查询
SELECT * FROM tb_user WHERE age = 18 LIMIT 1000000, 10; -
优化:创建覆盖索引。
# 覆盖索引 CREATE INDEX idx_user_age ON tb_user(age); # 子查询 SELECT * FROM tb_user WHERE id IN ( SELECT id FROM tb_user WHERE age = 18 ) LIMIT 1000000, 10;
分析:
- MySQL 不支持 IN 中使用 LIMIT。
- IN 存在数据量限制,通常子表超过 1000 条时效率降低。
5.2.3、覆盖索引 + 内连接
👍 使用 INNER JOIN 代替 IN。
SELECT * FROM tb_user
INNER JOIN (
SELECT id FROM tb_user
WHERE age = 18
LIMIT 1000000, 10
) AS tmp
USING(id);
6、COUNT
COUNT(*)
- MyISAM:将表的总行数存储在磁盘中。执行 COUNT(*) 时直接返回(前提:无 WHERE 条件)
- InnoDB:执行 COUNT(*) 时,从引擎中逐行读取并累计。
COUNT(?) 的效率
-
InnoDB:执行时,InnoDB 会扫描全表。
-
服务层:根据 ? 决定计数方式。
InnoDB 服务层 (*) 不取值 按行累加 (数字) 不取值 对返回的每行放入一个数字,按行累加 (主键) 取每行的主键值 按行累加 (字段) 取每行的字段值 根据字段有无 NOT NULL 约束。
无:判断字段是否 NULL,仅累计非空字段;
有:直接按行累加。
结论:COUNT(*) ≈ COUNT(1) > COUNT(主键) > COUNT(字段)
优先使用 COUNT(*)
7、UPDATE
7.1、说明
InnoDB 支持行级锁:对索引项加锁,而不是对记录加锁。
-
加锁:在一个事务中执行 UPDATE 操作时,系统会自动加锁,
-
粒度:根据 WHERE 条件列是否有索引。
- 是:行级锁
- 否:表锁。
-
释放:事务提交后,自动释放锁。
# id 主键索引:行级锁 START TRANSACTION; UPDATE tb_user SET name = 'Jaywee' WHERE id = 1; COMMIT; # name 无索引:表锁 START TRANSACTION; UPDATE tb_user SET name = 'Jaywee' WHERE name = 'demo'; COMMIT;
7.2、优化
建立索引:
- 对 WHERE 条件列添加有效索引。
- 避免行级锁升级为表锁,。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通