并发4️⃣管程④synchronized 锁优化
synchronized 是重量级锁,并发性能低。
为了提高并发时的系统吞吐量,JVM 提供了锁优化策略。
- 加锁策略:不加锁 → 偏向锁 → 轻量级锁 → 重量级锁
- 其它策略:自旋、锁消除、锁粗化等
1、偏向锁
1.1、Biased locking
当一个线程获取锁时进入偏向模式(设置锁标志位、线程 ID)
同一个线程再次请求锁时,检查 Mark Word 为当前线程 ID,则无需做同步操作。
-
优点:优化同一线程多次获取同一个锁的情况,节省大量有关锁申请(如 CAS)的操作,提高性能。
-
适用场合:只有一个线程对该对象加锁(没有锁竞争)
- 锁竞争:有其它线程也对该对象加锁。
- 发生不同时刻的锁竞争时升级为轻量级锁,发生同一时刻的锁竞争时膨胀为重量级锁。
-
虚拟机参数
# 开启偏向锁(默认开启) -XX:+UserBiasedLocking # 偏向锁开启延时(JDK10前默认4000ms,之后默认0) -XX:BiasedLockingStartupDelay=毫秒 -
Mark Word 说明
-
Thread、epoch、age:对象实例化时为 0,加锁 / 垃圾回收时才设置。
-
锁标志:
101(不加锁是001,区别在于倒数第三位)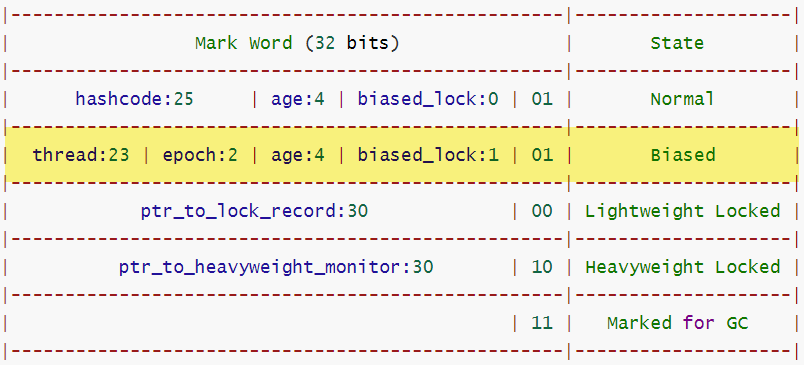
-
1.2、锁撤销
偏向锁在没有发生锁竞争时生效。
-
发生撤销的情况
变化 原因 获取对象 hashcode 撤销 Mark Word 需要存储 hashcode,
而偏向锁状态的 Mark Word 存储的是 thread 和 epoch。发生不同时刻的锁竞争 升级为轻量级锁 发生同一时刻的锁竞争 膨胀为重量级锁 调用 wait/notify膨胀为重量级锁 涉及到 Monitor 结构 -
对撤销的优化:撤销次数达到阈值时,会触发批量重偏向或批量撤销。
- 默认阈值:批量重偏向 20,批量撤销 40。
撤销次数 = 阈值 - 1,就认为达到了阈值。
-
涉及 JVM 结构
revocation_count:撤销计数器BiasdLockingDecayTime:即重新开启偏向锁的时间(默认 25000ms)
1.3、批量重偏向
场合:同一个类的对象实例发生不同时刻的锁竞争。
撤销次数达到阈值后不再撤销,而是将该类剩余的需要被加锁的实例,批量重偏向至另一个线程。
- 撤销次数是针对类计数,而不是对象实例。
- 重偏向不增加撤销次数。
- 批量重偏向的对象,在规定时间(即
BiasLockingDecayTime)内无法再次批量重偏向至新的线程。
示例理解
用 Vector 存储 User 对象,模拟多线程访问相同的对象实例。
Vector<User> userVector = new Vector<>();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100; i++) {
User user = new User();
userVector.add(user);
synchronized (user) {
}
}
}, "t1");
t1.start();
// 保证t1和t2在不同时刻加锁(否则膨胀为重量级锁)
t1.join();
new Thread(() -> {
for (int i = 0; i < 39; i++) {
User user = userVector.get(i);
synchronized (user) {
}
}
}, "t2").start();
线程 t1:对 100 个 user 对象实例加锁
- 100 个 User 都从无锁变成偏向锁。
- Mark Word 后三位为
101,thread 为 t1。
线程 t2:对前 39 个 user 对象加锁,分析如下
- user1-19:撤销偏向锁,加锁为轻量级锁(
00),解锁后设为禁用偏向锁(001) - user20-39:达到默认阈值 20 不再撤销,将之后此线程需加锁的所有实例都重偏向至 t2(
101,thread 置为 t2)
全程的对象状态
# t1
user1-100
加锁前: 001 无锁
加锁中: 101 偏向锁,thread为t1
解锁后: 101 偏向锁,thread为t1
# t2
# user1-19:撤销,升级为轻量级锁,禁用偏向锁
加锁前: 101 偏向锁,thread为t1
加锁中: 00 轻量级锁
解锁后: 001 禁用偏向锁
# user20-39:批量重偏向至 t2
加锁前: 101 偏向锁,thread为t1
加锁中: 101 偏向锁,thread为t2
解锁后: 101 偏向锁,thread为t2
# user40-100
101 偏向锁,thread为t1
1.4、批量撤销
场合:同一个类的对象实例发生不同时刻的锁竞争。
撤销次数达到阈值后,不再撤销或批量重偏向,而是撤销该类所有实例的偏向锁,并禁用该类的偏向锁。
示例理解
在批量重偏向的例子中,增加 t3 线程。
Vector<User> userVector = new Vector<>();
// 保证t1和t2在不同时刻加锁(否则膨胀为重量级锁)
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100; i++) {
User user = new User();
userVector.add(user);
synchronized (user) {
}
}
}, "t1");
t1.join();
Thread t2 = new Thread(() -> {
for (int i = 0; i < 39; i++) {
User user = userVector.get(i);
synchronized (user) {
}
}
}, "t2");
// 保证t2和t3在不同时刻加锁(否则膨胀为重量级锁)
t1.join();
new Thread(() -> {
for (int i = 0; i < 39; i++) {
User user = userVector.get(i);
synchronized (user) {
}
}
}, "t3").start();
线程 t1:对 100 个 User 对象实例加偏向锁(101,thread 为 t1)
线程 t2:对 UserVector 前 39 个对象加锁(前 19 个禁用偏向锁,20-39 是 t2 偏向锁)
线程 t3:对前 40 个 user 对象加锁,分析如下
- user1-19:t2 加锁时已设为禁用偏向锁,加锁时为轻量级锁,解锁时仍为禁用偏向锁。
- user20-38:(共 19 个)撤销偏向锁,加锁为轻量级锁(
00),解锁后设为禁用偏向锁(001) - user39:达到批量重偏向阈值,但未超过 BiasedLockingDecayTime
- 无法二次重偏向(操作同上,加轻量级锁,禁用偏向锁)。
达到阈值 40
- 撤销次数共 39 次,达到阈值。
- 撤销该类所有实例的偏向锁,并禁用该类的偏向锁。
- 此后创建该类的实例对象,也是处于禁用偏向锁的状态(
001)。
全程的对象状态
# t1
# user1-100
加锁前: 001 无锁
加锁中: 101 偏向锁,thread为t1
解锁后: 101 偏向锁,thread为t1
# t2
# user1-19:撤销,升级为轻量级锁,禁用偏向锁
加锁前: 101 偏向锁,thread为t1
加锁中: 00 轻量级锁
解锁后: 001 禁用偏向锁
# user20-39:批量重偏向至 t2
加锁前: 101 偏向锁,thread为t1
加锁中: 101 偏向锁,thread为t2
解锁后: 101 偏向锁,thread为t2
# user40-100
101 偏向锁,thread为t1
# t3
# user1-19:保持禁用偏向锁
加锁前: 001 禁用偏向锁
加锁中: 00 轻量级锁
解锁后: 001 禁用偏向锁
# user20-38:撤销,升级为轻量级锁,禁用偏向锁
加锁前: 101 偏向锁,thread为t2
加锁中: 00 轻量级锁
解锁后: 001 禁用偏向锁
# user39:达到批量重偏向阈值,但已被批量重偏向过
加锁前: 101 偏向锁,3的thread为t2
加锁中: 00 偏向锁,轻量级锁
解锁后: 001 禁用偏向锁
# user40-100
001 禁用偏向锁
2、轻量级锁
线程 t1 已获取对象锁,某一时刻 t1 没有加锁,t2 尝试获取该对象锁时。
t2 检查 Mark Word 发现线程 ID 不是 t2,则升级为轻量级锁。
-
适用场景:发生不同时刻的锁竞争。
-
锁标志:Mark Word 保存锁记录对象地址,末尾两位为
00。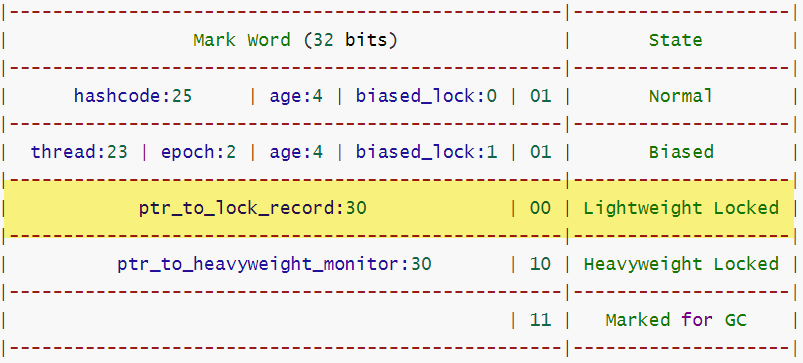
2.1、锁记录
Lock Record:每个线程的栈帧中的空间结构
两部分组成
-
锁记录地址、锁标志

-
对象引用:存储当前线程正加锁的对象
2.2、加锁过程
- 创建 Lock Record → CAS → 成功
- 创建 Lock Record → CAS → 失败 → 自旋 → 成功或膨胀
① 创建 Lock Record
-
线程执行到
synchronized(user){}代码块,在当前栈帧(Frame)创建锁记录对象(Lock Record)。 -
Object Reference保存 user 地址。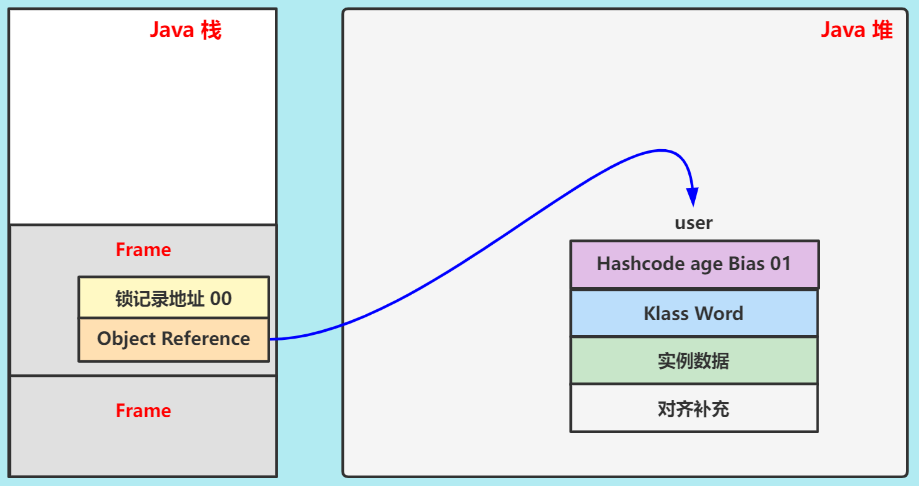
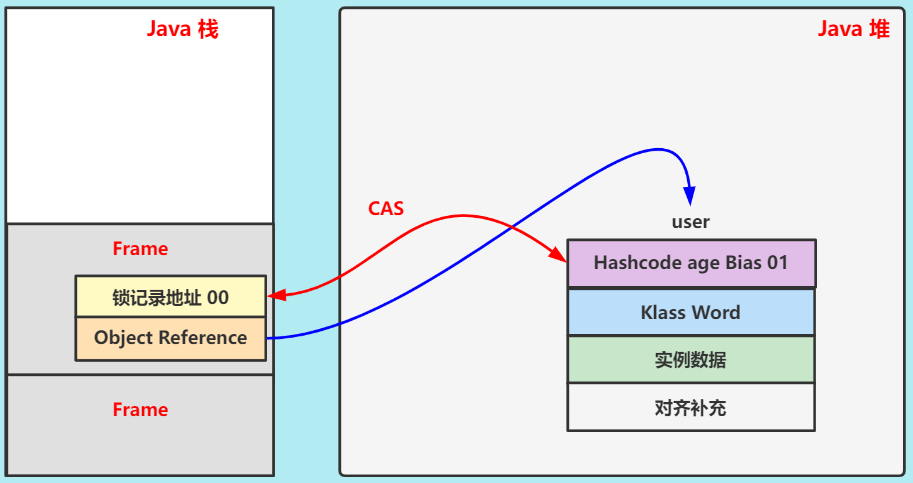
② CAS
尝试用锁记录地址,交换 user 的 Mark Word。
③ CAS 成功
加轻量级锁成功
-
Lock Record中存储 user 的原Mark Word。 -
user 当前的
Mark Word存储了锁记录地址和锁标志(即ptr_to_lock_record00)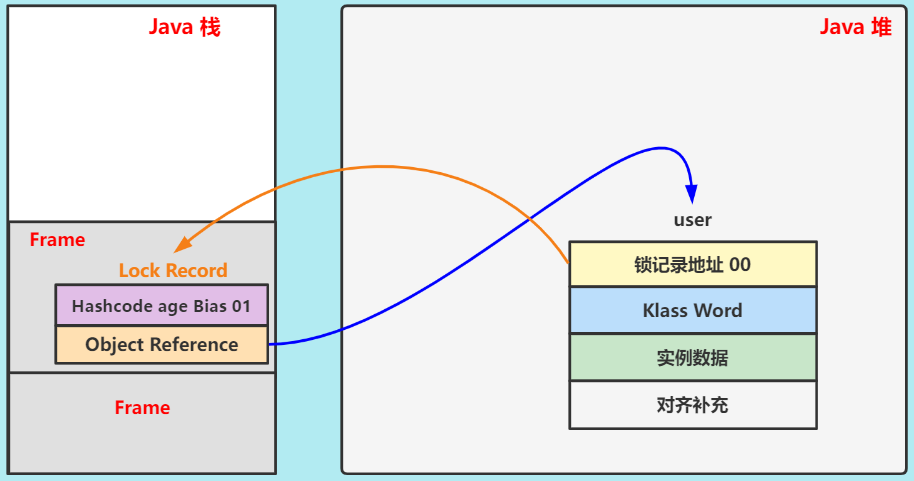
④ CAS 失败
假设线程 t1 已对 user 加轻量级锁且未释放,分析以下情况。
case1:线程 t2 尝试加轻量级锁
new Thread(()->{
synchronized(user){ // 锁膨胀(先自旋)
}
},"t2").start;
- 创建
Lock Record。 - 尝试 CAS,但 user 的
Mark Word已存储锁记录地址,CAS 失败。 - 查看锁记录地址,发现不属于当前线程(即产生同一时刻的锁竞争)
- 进入锁膨胀过程(稍后讲解)。
case2:线程 t1 再次该对象加锁(锁重入)
-
创建
Lock Record。 -
尝试 CAS,但 user 的
Mark Word已存储锁记录地址,CAS 失败。 -
查看锁记录地址,发现属于当前线程 (即锁重入)
-
重置
Lock Record的锁记录地址(置为 null),此锁记录作为重入计数。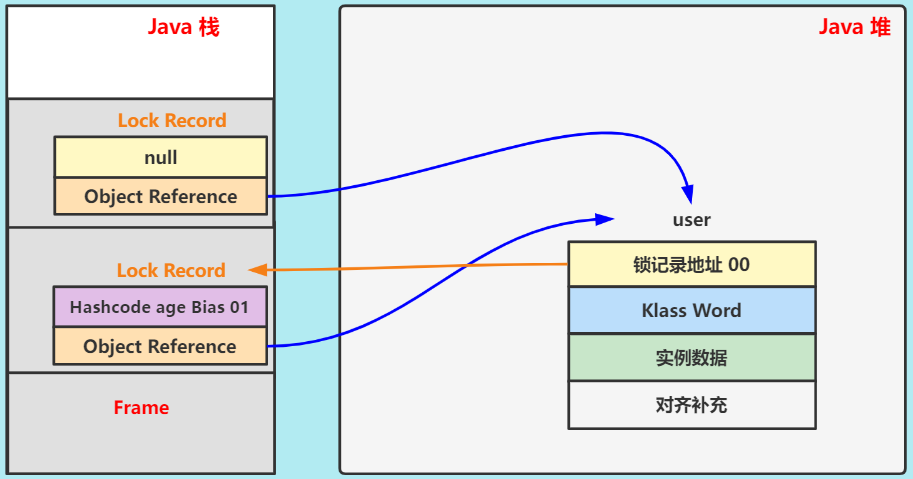
2.3、解锁过程
线程退出
synchronized代码块时,查看当前活动栈帧中Lock Record的头部。
- null:说明是锁重入。
- 非 null:存储的是对象实例的原
Mark Word,通过 CAS 恢复给对象实例。- CAS 成功:轻量级锁解锁成功。
- CAS 失败:说明轻量级锁已膨胀,进入重量级锁解锁流程(稍后讲解)。
2.4、锁膨胀 & 锁自旋
① 锁膨胀
锁膨胀:不使用轻量级锁,而是改用重量级锁。
场景:发生同一时刻的锁竞争
示例:线程 t1 持有 user 的轻量级锁,线程 t2 尝试加轻量级锁时 CAS 失败
进入锁膨胀过程
- t2 为 user 申请 Monitor,让 user 的
Mark Word指向 Monitor 对象地址。 - t2 进入
EntryList,变成BLOCKED状态。 - t1 执行完临界区代码,退出
synchronized代码块时 CAS 失败。 - t1 进入重量级锁解锁流程
- 通过
Lock Record的对象引用,根据 user 的Mark Word找到 Monitor 对象。 - 将
Owner置为 null,唤醒EntryList中的阻塞队列。 - 后续操作,回顾 Monitor 原理(1.2)
- 通过
② 自旋
锁膨胀的缺点
- 导致当前线程进入
EntryList变成阻塞状态(BLOCKED) - 导致线程上下文切换,影响性能。
在锁膨胀之前,JVM 会尝试自旋优化。
- 让当前线程做若干次空循环(即自旋),而不是直接阻塞。
- 若在此期间,轻量级锁被持有者释放,则当前线程成功获得锁。
说明
- 自旋会消耗 CPU:自旋的做法是使线程执行空循环,在此期间消耗一定的 CPU 资源。
- 多核 CPU 下自旋才有效:至少有一个 CPU 用于执行 owner 的线程,另一个 CPU 用于当前线程的自旋。
- Java 6 后自旋锁自适应(自动调整自旋次数),Java 7 后默认开启自旋功能。
3、锁消除 & 锁粗化
锁消除和锁粗化是 JVM 的运行期优化 技术。
3.1、锁消除
Lock Elimination
以线程安全的 StringBuffer 类为例。
-
变量 result 是局部变量,只会在方法内部被调用,不存在线程安全问题。
-
JVM 在运行时自动将 StringBuffer 对象内部的锁消除。
public void add(String str1, String str2) { StringBuffer result = new StringBuffer(); result.append(str1).append(str2); }
3.2、锁粗化
Lock Coarsening
仍以 StringBuffer 类为例。
-
假如没有锁粗化,以下代码会对同一个对象进行 10000 次加锁和解锁操作,浪费资源。
-
JVM 在运行时会将加锁的范围粗化(比如对整个循环体加锁),使得整个操作只进行 1 次加锁和解锁操作。
StringBuffer result = new StringBuffer(); public String add(String str) { for (int i = 0; i < 10000; i++){ result.append(str) } return result.toString(); }
