Redis2️⃣数据类型 & 指令(❗)
1、说明
1.1、基本要求
1.1.1、指令
-
大小写敏感:
- key 和 value 值大小写敏感
- 指令大小写不敏感(👍 大写)
-
数据类型:
- Redis 数据的 key 通常是字符串类型。
- value 支持多种数据类型(本文介绍的数据类型,指 value 的类型)
-
操作指令:Redis 单线程,因此指令具有原子性。
- 官方中文文档
- 指令帮助:Redis 命令行输入
help 指令名
1.1.2、key 命名
目的:Redis 的 key 要求唯一,避免覆盖。
-
建议命名:
::分隔不同的层级(命名空间)。- 层级适中:太长占资源,太短可读性差。
- 单词全部大写。
-
参考格式:根据实际需求调整层级,仅供参考。
项目名:表名:字段名:主键 项目名:模块名:功能名:主键
示例
# 商品访问量
goodscenter:goods:pv:179
# 用户登录验证码
usercenter:user:login:7
1.2、通用指令
1.2.1、key
① 查询
| 作用 | 备注 | |
|---|---|---|
| KEYS <pattern> | 查询当前数据库中匹配的 key | 可用通配符*:多个字符,类似 MySQL 模糊查询 %?:单个字符,类似 MySQL 模糊查询 _ |
| EXISTS <key> [key...] | 判断 key 是否存在 | 返回存在的个数 |
| TYPE <key> | 查看 key 的类型 |
② 删除
可指定多个 key,返回实际删除个数。
| 备注 | |
|---|---|
| DEL <key> [key...] | 在当前线程删除(同步,阻塞) |
| UNLINK <key> [key...] | 在另一个线程删除(异步,非阻塞) |
③ 过期时间
单位:秒
| 作用 | 备注 | |
|---|---|---|
| EXPIRE <key> <second> | 设置到期时间 | |
| TTL <key> | 查看剩余到期时间(Time To Live) | -1:永不过期-2:已过期 |
1.2.2、数据库
Redis 默认有 16 个数据库,默认使用 0 号库。
| 作用 | |
|---|---|
| DBSIZE | 查看当前库的 key 数量 |
| SELECT <index> | 切换数据库 |
| FLUSHDB [ASYNC|SYNC] | 清空当前库(同步/异步) |
| FLUSHALL [ASYNC|SYNC] | 清空所有库(同步/异步) |
2、数据类型
2.1、String 字符串
Redis 最基本的数据类型
- 二进制安全:严格按照二进制化的字符串进行存储,不会以特殊格式解析字符串。
- 类型:根据内容可分为字符串,整数,浮点数
- 最大内存空间:512M
2.1.1、数据结构
类似 Java 的 ArrayList
简单动态字符串(SDS, Simple Dynamic String)
-
内存分配:预分配冗余空间(capacity),减少内存的频繁分配。
-
扩容:根据字符串长度(len)决定
-
若 len < 1M 则加倍,若 len > 1M 则扩容 1M。
-
最大长度是 512M。

-
2.1.2、常用命令
① 存取
| 作用 | 备注 | |
|---|---|---|
| SET <key> <value> | 设置 key 的 value 值 | 新增/更新 |
| GET <key> | 查询 key 的 value 值 | |
| MSET <key> <value> ... | 设置多个 key 的 value 值 | 新增/更新 |
| MGET <key> ... | 查询多个 key 的 value 值 | |
| SETEX <key> <second> <value> | 设置 key 的 value 并设置有效期 | SET + EXPIRE |
| SETNX <key> <value> | key 不存在才设置 | 新增 |
| GETSET <key> <value> | 查询 key 并设置新值 |
② 范围
索引从 0 开始。
| 作用 | 备注 | |
|---|---|---|
| GETRANGE <key> <start> <end> | 查询 key 指定范围的值 | 即子串,闭区间 |
| SETRANGE <key> <offset> <value> | 覆盖 key 指定下标之后的值 |
③ 增减(数值)
- 只能操作数值型(整型/浮点型)
- 若 key 不存在则自动新增并赋值。
- 仅
INCRBYFLOAT可用于浮点型,其它仅用于整型。
| 作用 | 备注 | |
|---|---|---|
| INCR <key> | 自增 1 | 整型 |
| DECR <key> | 自减 1 | 整型 |
| INCRBY <key> <amount> | 自增 amount | 整型 |
| DECRBY <key> <amount> | 自减 amount | 整型 |
| INCRBYFLOAT <key> <amount> | 自增 amount | 整型,浮点型 |
④ 其它
| 作用 | |
|---|---|
| APPEND <key> <value> | 将 value 追加到 Key 的值 |
| STRLEN <key> | 查询 key 的 value 长度 |
2.1.3、应用
- 验证码、token(expire)
- 点赞或访问计数(incr / decr)
2.2、Hash 哈希
无序字典(键值对集合)
- 结构:key 是 String,value 是无序字典(若干个 field-value 对)。
- 适合存储对象:可独立存储对象中的每个字段,可针对单个字段操作。
2.2.1、数据结构
根据 field-value 的长度和个数,使用不同的数据结构。
- ziplist:一块连续内存,类似 Java 数组
- hashtable:类似 Java 的 HashMap<String, Object>
- 长度短且个数少:压缩链表(ziplist)
- 其它情况:哈希表(hashtable)
2.2.2、常用命令
命令以字母
h开头,可理解为嵌套了一层的普通命令。
① 查询
| 作用 | 备注 | |
|---|---|---|
| HEXISTS <key> <field> | 判断指定 field 是否存在 | |
| HGETALL <key> | 获取 key 的所有 field-value 对 | 类似 Map 的 EntrySet() |
| HKEYS <key> | 获取 key 的所有 field | 类似 Map 的 KeySet() |
| HVALS <key> | 获取 key 的所有 value | 类似 Map 的 values() |
② 存取
| 作用 | 备注 | |
|---|---|---|
| HSET <key> <field> <value> | 设置 key 的 field-value 对 | 可存储多对 |
| HGET <key> <field> | 查询 key 的 field 值 | GET 的 field 版 |
| HMSET <key> <field> <value> ... | 设置 key 的多个 field-value 对 | 等同 HSET |
| HMGET <key> <field> ... | 查询 key 的多个 field 值 | |
| HSETNX <key> <field> <value> | SETNX 的 field 版 |
③ 递增
仅数值型 field 可用
| 作用 | |
|---|---|
| HINCRBY <key> <field> <amount> | key 的数值型 field,递增指定步长 |
2.2.3、应用
存储对象
示例:key 为对象唯一标识,value 为对象属性。
- key:usercenter:user:1
- value:
- name:jaywee
- age:18
- gender:male
思考:使用 String 存储对象?
尝试两种方案:
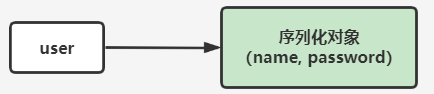
-
key 为对象唯一标识,value 为序列化对象。
-
存储:将对象序列化成 JSON 字符串,存入 Redis。
-
缺点:属性发生变更时需要反序列化,再序列化修改后的对象(开销大)。
-
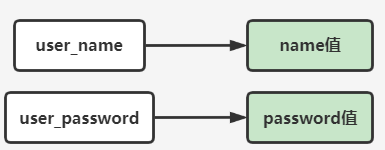
-
Key 为对象唯一标识+属性名,value 为属性值。
-
存储:将属性值存储在不同 Key 下。
-
问题:存储时使用多个 Key,查询对象时需查询多个 key(数据冗余)。
-
2.3、List 列表
单键多值(字符串列表)
- 结构:key 是 String,value 是多个 element 值(单键多值)。
- 特点:有序,有下标,可重复。
2.3.1、数据结构
根据 value 的值个数,使用不同的数据结构。
- ziplist:一块连续内存,类似 Java 数组
- quicklist:ziplist + 双向链表
-
元素较少时:压缩列表(ziplist)
-
元素较多时:快速链表(quicklist)
-
分析:ziplist 的增删效率低,普通链表的指针需要占用大量内存。
-
结论:结合使用,满足增删性能,减少内存冗余。

-
2.3.2、常用命令
① 存取
-
两侧:
作用 备注 LPUSH|RPUSH <key> <element> [element...] 向 key 的左/右侧,添加若干个值 LPOP|RPOP <key> [count] 从 key 的左/右侧取出若干个值 默认 1,可指定个数 RPOPLPUSH <k1> <k2> 将 k1 右侧值取出,添加到 k2 左侧 BLPOP|RLPOP <key> [key...] <second> pop,若 key 不存在的等待指定时间 同步,阻塞 -
索引:从 0 开始,顺序从左往右。
作用 备注 LINDEX 查询 key 指定索引的元素 LINSERT <key> <BEFORE|AFTER> <pivot> <value> 向 key 的元素 pivot 前/后,添加指定 value pivot 是元素值 LSET <key> <index> <element> 替换 key 指定索引的 element LREM <key> <count> <element> 删除 key 中 count 个 element
② 范围、长度
| 作用 | 备注 | |
|---|---|---|
| LRANGE <key> <start> <stop> | 查询 key 指定索引范围的值 | stop > 0 从左数,stop < 0 从右数 |
| LLEN <key> | 查询 key 的列表长度 | 即 value 元素个数 |
2.3.3、应用
- 发布/订阅
- 消息队列
2.4、Set 集合
单键多值(字符串集合)
- 结构:key 是 String,value 是多个 member 值(单键多值)。
- 特点:无序、无下标、不可重复。
- 支持交并差集。
2.4.1、数据结构
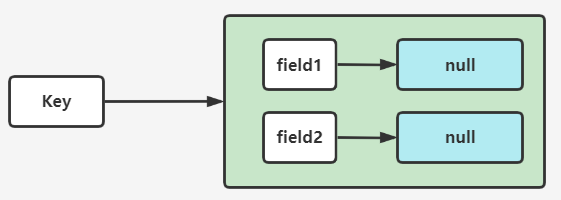
类似 Java 的 HashSet
字典(dict):底层是 value 为 null 的 Hash。
2.4.2、常用命令
① 查询
| 作用 | 备注 | |
|---|---|---|
| SCARD <key> | 元素个数 | 基数 cardinality |
| SMEMBERS <key> | 查出所有元素 | |
| SRANDMEMBER <key> [count] | 随机查出若干个元素 | 默认 1,可指定个数 |
| SISMEMBER <key> <member> | 判断 member 是否属于 set |
② 增删
| 作用 | 备注 | |
|---|---|---|
| SADD <key> <member> [member..] | 添加若干个元素 | 跳过已存在的值 |
| SREM <key> <member> [member..] | 删除指定元素 | |
| SMOVE <k1> <k2> <member> | 将 member 从 k1 移动到 k2 | |
| SPOP <key> [count] | 随机取出若干个元素 | 查询并删除 |
③ 集合论
| 作用 | |
|---|---|
| SINTER <key> [key...] | 交集 |
| SUNION <key> [key...] | 并集 |
| SDIFF <key> [key...] | 差集 |
2.4.3、应用
去重
2.5、Zset 有序集合
单键多值 + 排序(可排序字符串集合)
-
结构:
- key 是 String,value 是若干个 member-score 对(单键多值)。
- 每个 member 关联 score(评分),用于排序。
-
特点:set 特点、可排序。
2.5.1、数据结构
类似 Java 的 TreeSet,排序标准是 score
使用两种数据结构:
- hash:保证 member 唯一性,关联 member 和 score。
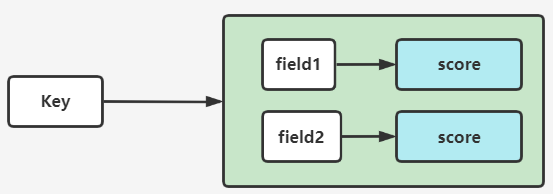
- skipList(跳跃表):基于 score 为 member 排序。
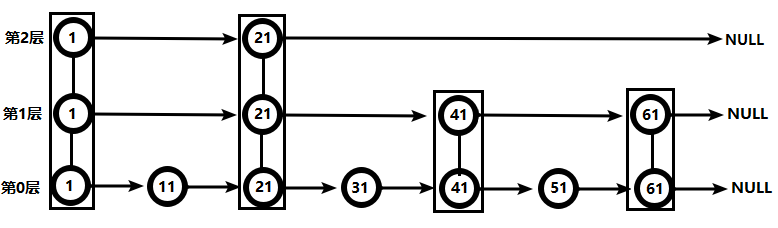
2.5.2、常用命令
- 指令 Z... 默认升序,若要降序则使用 ZREV...
- 下标从 0 开始
① 查询
| 作用 | 备注 | |
|---|---|---|
| ZRANGE <key> <min> <max> [WITHSCORES] | 查询排名范围内的 member | 名次的范围 |
| ZRANGEBYSCORE <key> <min> <max> [WITHSCORES] | 查询 score 范围内的 member | score 的范围 |
| ZCARD <key> | 查询 zset 的 member 个数 | |
| ZCOUNT <key> <min> <max> | 查询 score 范围内的 member 个数 | |
| ZSCORE <key> <member> | 查询 member 的 score | |
| ZRANK <key> <member> | 查询 member 的排名 |
② 增删
|
|
|
|
|
| 作用 | 备注 | |
|---|---|---|
| ZADD <key> <score> <member> | 添加若干对 score-member | member 已存在则更新 score |
| ZREM <key> <member> [member...] | 删除指定 member |
③ 递增
| 作用 | 备注 | |
|---|---|---|
| ZINCRBY <key> <amount> <member> | member 的 score 递增指定步长 | 可正可负 |
2.5.3、应用
排行榜
3、新数据类型
3.1、Bitmaps(位图)
充分使用字节的 8 位二进制数。
- 计算机中用 8 位二进制数编码表示数值信息(1 byte = 8 bit)
- Bitmaps 本质是字符串,但支持位操作。
- 可理解成以 bit 为单位的数组,数组下标称为偏移量。
- 充分利用操作位,可有效提高内存使用率和开发效率。
3.2.1、常用命令
-
setbit:设置指定偏移量的值(偏移量,offset 从 0 开始)。
-
getbit:获取指定偏移量的值。
-
bitcount:统计值为 1 的位数目,可指定字节范围。
-
bitop:复合操作(与或非、异或)
setbit <key> <offset> <value> getbit <key> <offset> bitcount <key> [start end] bitop and/or/not/xor <destkey> [key]
案例:某一天用户是否上线
- 设置:用户 ID作为偏移量,用户上线则设为 1。
- 通常,bitmaps 的 Key 为某一天的访问情况。
- 用户 ID 可能未必从 0 开始,需要经过一定处理。
- 获取:根据用户 ID(偏移量)查询,1 表示访问过。
- 数量:统计上线用户数。
- 复合:如 and,查看两天都有上线的用户。
3.2.2、应用
签到、用户在线状态、用户访问情况
3.2、HyperLogLog(基数统计)
3.2.1、基数问题
基数:集合中不重复元素的个数。
- 示例:
{1, 3, 3, 5, 7}的基数集为{1, 3, 5},基数为 3。 - 应用场景:
传统方案
特点:精度高,但随着数据的增加,空间占用过多。
- MySQL:查询 DISTINCT COUNT。
- Redis:hash、set、bitmaps 等数据结构。
HyperLogLog(HLL):基数统计算法
降低一定的精度来平衡存储空间
- 机制
- 根据输入元素来计算基数,而不会存储元素。
- 每个 HLL 的 Key 占用 12KB 内存,可计算接近 2^64 个不同元素的基数。
- 特点:
- 即使输入元素的数量或容量很大,计算基数所占空间固定且很小。
- 只计算基数,不存储元素,无法返回输入的元素。
3.2.2、常用命令
HyperLogLog,以下简称 HLL
-
pfadd:添加一个或多个元素。
-
pfcount:计算一个或多个 HLL 的基数。
-
pfmerge:将一个或多个 HLL 合并到另一个 HLL。
pfadd <key><element1><element2> pfcount <k1> <k2> pfmerge <destkey><sourcekey1><sourcekey2>
案例:记录网站 UV,多次访问只有一个 UV 记录
- 设置:用户 ID 作为 HLL 的元素。
- 统计
- 合并:如合并 7 天的 UV 得到一周的 UV。
3.2.3、应用
UV(UniqueVisitor,独立访客)、独立 IP 数。
3.3、Geospatial(地理)
- 二维坐标表示地图的经纬度。
- 提供经纬度设置、查询等操作。
命令
-
geoadd:添加一个或多个地理位置。
-
geopos:获取指一个或多个 Key 的坐标值。
-
geodist:计算两个位置的直线距离,可设置单位。
-
georadius:获取指定 Key 的半径之内的元素,可设置单位。
geoadd <key> <longitude> <latitude> <member> geopos <key> <member> geodist <key> <member1> <member2> [m|km|ft|mi ] georadius <key> <longitude> <latitude> radius m|km|ft|mi


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现