MySQL7️⃣索引(❗)
索引(index):帮助 MySQL 高效获取数据的有序数据结构。
数据库系统既维护数据,还维护索引(以某种方式引用数据)。
- 优点:
- 提高查询效率,降低数据库 I/O 成本。
- 通过有序索引列对数据排序,降低排序成本 和 CPU 消耗。
- 缺点:
- 索引也占用内存。
- 执行 DML 时需要更新索引,导致表的更新效率降低。
1、数据结构
MySQL 索引在存储引擎层实现,
不同存储引擎的索引结构可能有所不同。
主要的索引结构:
| 说明 | InnoDB | MyISAM | Memory | |
|---|---|---|---|---|
| B+ tree 🔥 | 若非特别指明,索引通常是指 B+ tree | ✔ | ✔ | ✔ |
| Hash | 仅支持精确匹配,不支持范围查询 | - | - | ✔ |
| R tree | 通常用于地理空间数据类型 | - | ✔ | - |
| Full text | 通过建立倒排索引,快速匹配文档 | 5.6+ ✔ | ✔ | - |
1.1、B+ tree(❗)
InnoDB 使用优化的 B+ tree 索引结构。
在此之前,先了解二叉树,B tree、标准 B+ tree。
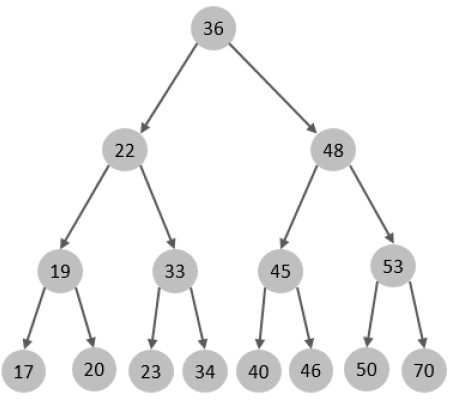
1.1.1、二叉树
每个结点存放 key(包括数据)和指针。
缺点:以二叉搜索树(BST)为例
-
线性情况:
- 在极端情况下,添加的元素都比根节点大或者小,导致一侧子树线性增长。
- 此时的结构无异于链表,时间复杂度是
O(n)。
-
层级多:
-
在大数据量的场景下,由于二叉树的度是 2(每个结点最多存储 2 个孩子)。
-
导致树的层级多,检索速度慢。
-
如果使用红黑树呢?
- 线性情况:可以避免(旋转达到平衡)
- 层级多:无法避免(红黑树也是二叉树,度 == 2)
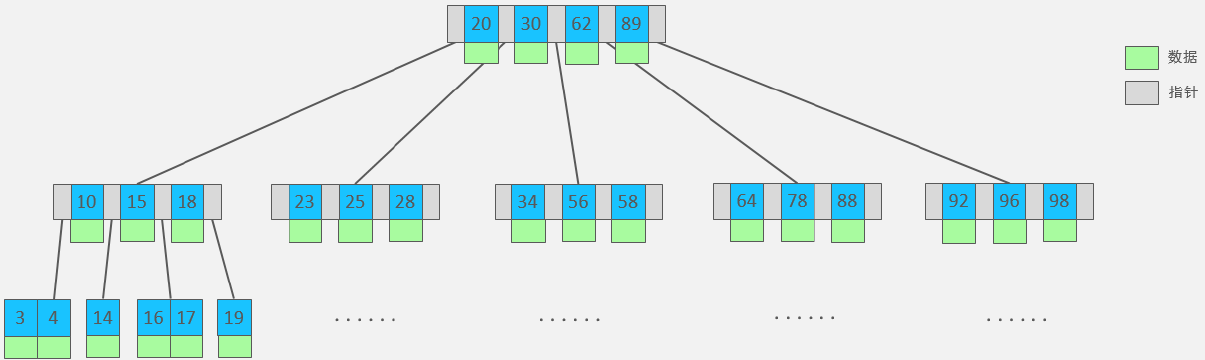
1.1.2、B tree
多路平衡查找树(算法可视化)
每个结点存放 key(包括数据)和指针。
特点:
-
最大度数为 k 的 B tree,每个结点最多存储
k - 1个 key 和k个指针。 -
当结点存储的 key 达到度数,中间元素向上分裂。
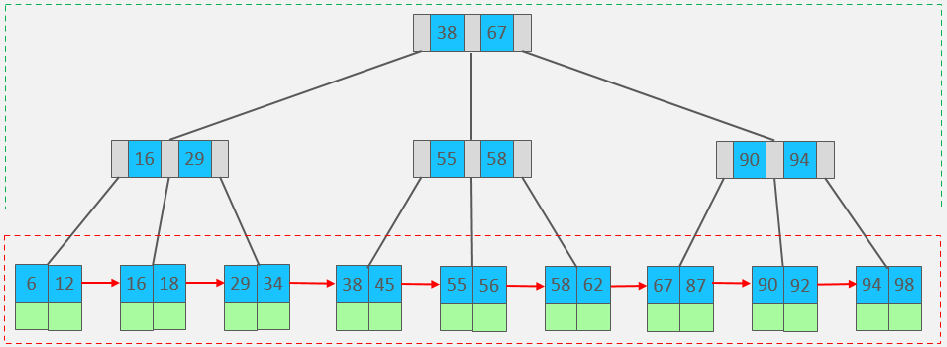
1.1.3、B+ tree
B tree 的变体
- 非叶结点:仅存放 key(不包括数据) 和指针。
- 叶结点:存储 key(包括数据),叶子结点形成单向链表。
特点:
-
当结点存储的 Key 达到度数时,中间元素保留且向上分裂。
-
相比标准的 B tree,可以存储的数据更多。
-
非叶结点仅起到索引作用。
-
叶节点才存储数据。
-
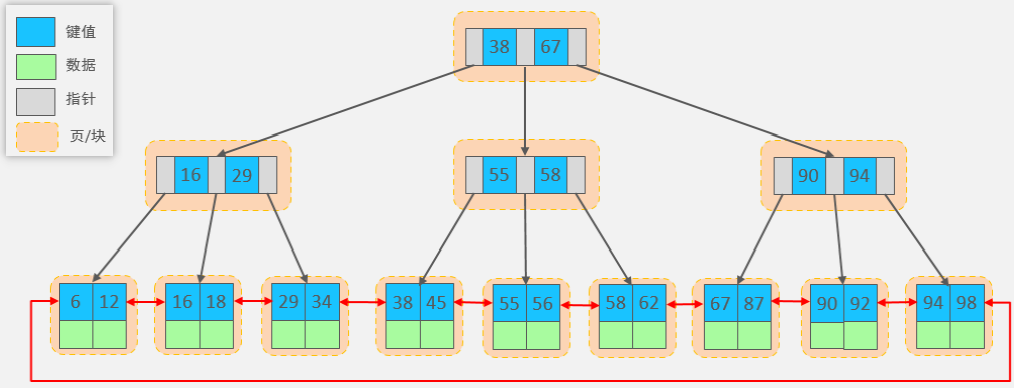
1.1.4、优化 B+ tree
B+ tree 的变体
特点:相比标准 B+ tree,叶子结点形成双向循环链表。
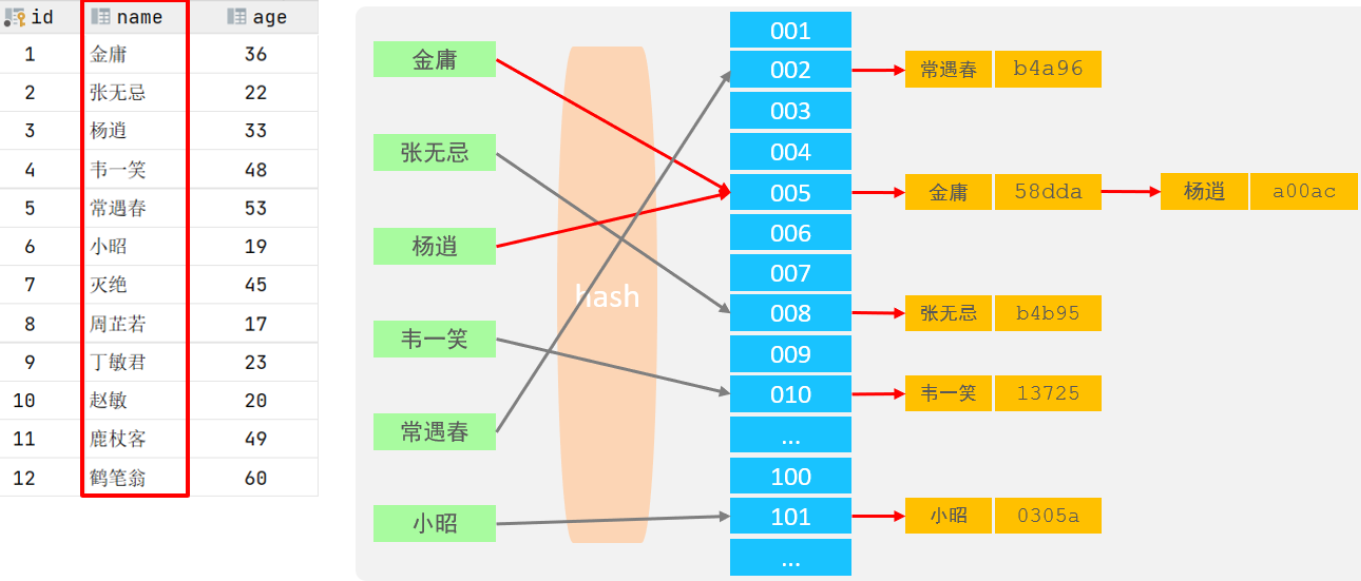
1.2、Hash
参考 👉 哈希及 Java 实现
特点:
-
支持等值查询( =,in),不支持范围查询(between,>)
-
不支持排序
-
查询效率高:若不存在哈希冲突,通常只需一次检索。
1.3、对比
为什么 InnoDB 存储引擎使用 B+ tree 索引结构
思路:介绍二叉树、B 树、Hash 索引,对比并说明其缺点。
| 二叉树 | B tree | B+ tree | Hash | |
|---|---|---|---|---|
| 存储机制 | 结点存放数据和指针 | 结点存放数据和指针 | 非叶节点存指针,叶结点存数据 | Hash 表 |
| 缺点 | 可能出现线性情况; 数据量大时层级多。 |
相比 B+ 树,每页能存储的结点数减少 | - | 不支持范围查询和排序 |
2、分类(❗)
2.1、MySQL 索引类型
| 含义 | 特点 | 关键字 | |
|---|---|---|---|
| 主键索引 | 针对主键创建 | 自动创建,唯一 | PRIMARY |
| 唯一索引 | 避免某数据列中的值重复 | 可有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可有多个 | |
| 全文索引 | 查找文本关键词,而不是比较索引值 | 可有多个 | FULLTEXT |
2.2、InnoDB 索引形式
2.2.1、分类
在 InnoDB 中,根据索引的存储形式分为两类。
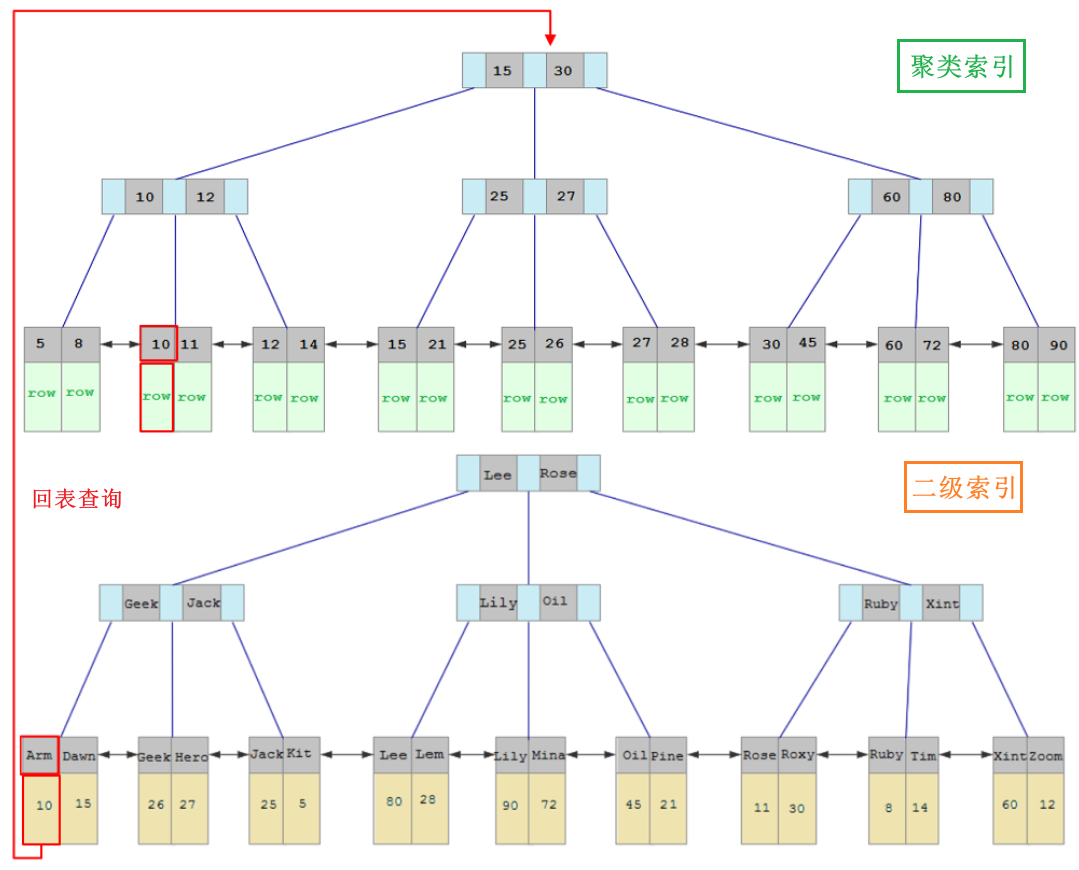
| 聚集索引(Clustered) | 二级索引(Secondary) | |
|---|---|---|
| 结构 | 数据与索引一起存储 | 数据与索引分开存储 |
| 叶节点特点 | 保存数据 | 关联主键 |
| 数量 | 有且唯一 | 0 或多 |
2.2.2、聚集索引的选取
根据数据库表的情况,决定聚集索引
- 存在主键:使用主键索引。
- 不存在主键:使用首个唯一索引。
- 不存在主键和唯一索引:自动生成隐藏的 rowid 作为聚集索引。
case:数据查找过程
Hint:查询条件不是主键,因此先查二级索引,再查聚集索引。
SELECT * FROM user WHERE name = 'Arm';
-
先根据 name 字段的二级索引,查找到关联主键。
-
回表查询:根据二级索引查到的主键,到聚集索引中查找对应的行数据。
3、语法(❗)
3.1、索引
3.1.1、创建
通常命名为
idx_表名_列名
-
类型:
- 常规索引:无需指定
- 唯一索引:UNIQUE
- 全文索引:FULLTEXT
-
列数:
- 单列索引
- 联合索引:为多个列创建的索引。
-
前缀索引:为字符串的部分前缀建立的索引。
# 索引 CREATE [UNIQUE|FULLTEXT] INDEX 索引名 ON 表名 (列名, ... ) ; # 前缀索引 CREATE [UNIQUE|FULLTEXT] INDEX 索引名 ON 表名 (列名(前缀长度), ... ) ;
前缀索引
- 分析:针对字符串类型的字段(如 varchar, text)
- 建立常规索引时会占用很大内存。
- 浪费大量磁盘 I/O,影响查询效率。
- 对策(前缀索引):为字符串的部分前缀建立索引,前缀长度由索引的选择性决定。
- 选择性:表中不重复的索引值与记录总数的比值。
- 索引查询效率:与选择性成正比(唯一索引的选择性为 1,查询效率最高)。
3.1.2、查看 & 删除
-
查看索引:
SHOW INDEX FROM 表名; -
删除索引:
DROP INDEX 索引名 ON 表名;
case:建立索引
根据不同情况,为
t_user表创建索引。
-
name 姓名字段,可能重复。 👉 常规
CREATE INDEX idx_user_name ON t_user(name); -
phone 手机号字段,非空且唯一。👉 唯一
CREATE UNIQUE INDEX idx_user_phone ON t_user(phone); -
为 profession、age、status 字段创建索引。👉 联合
CREATE INDEX idx_user_pro_age_sta ON t_user(profession, age, status); -
为 email 创建索引。👉 前缀
# 计算前缀长度 SELECT COUNT(DISTINCT email) / COUNT(*) FROM tb_user; CREATE INDEX idx_user_email ON t_user(email(前缀长度));
3.2、SQL prompt
SQL 提示:在 DQL 语句中加入提示信息,提示 MySQL 做出相应动作。
USE INDEX:建议 MySQL 使用指定索引。FORCE IDNEX:强制 MySQL 使用指定索引。IGNORE INDEX:忽略指定索引。
示例
# 建议
EXPLAIN SELECT * FROM tb_user
USE INDEX(idx_user_pro)
WHERE profession = '软件工程';
# 强制
EXPLAIN SELECT * FROM tb_user
FORCE INDEX(idx_user_pro)
WHERE profession = '软件工程';
# 忽略
EXPLAIN SELECT * FROM tb_user
IGNORE INDEX(idx_user_pro)
WHERE profession = '软件工程';
4、索引使用(❗)
借助 SQL 性能分析,对比有无索引的执行效率。
4.1、最左前缀法则
说明
如果想要使用联合索引,需要遵守最左前缀法则。
(最左打头,中间不断)
- 最左前缀法则:针对查询条件,必须根据联合索引的最左侧开始包含字段。
- 部分失效:跳过某一列,则只能使用该列之前的索引,之后的索引失效。
case
联合索引:字段列表依次为 profession, age, status
CREATE INDEX idx_prof_age_status ON tb_user(profession, age, status);
-
正常使用:
EXPLAIN SELECT * FROM tb_user WHERE profession = '计算机科学'; EXPLAIN SELECT * FROM tb_user WHERE profession = '计算机科学' AND age = 17; EXPLAIN SELECT * FROM tb_user WHERE profession = '计算机科学' AND age = 17 AND status = '0'; -
失效情况:
-
完全失效:跳过了最左侧的字段。
EXPLAIN SELECT * FROM tb_user WHERE age = 17 AND status = '0'; -
部分失效:跳过了中间的字段 age,只有最左侧字段使用到索引。
EXPLAIN SELECT * FROM tb_user WHERE profession = '计算机科学' AND status = '0';
-
4.2、覆盖索引
说明
假如 DQL 查询使用到了索引,且该索引包含了所有要查询的列,
则无需进行回表查询。
- 通常是联合索引能达到覆盖索引的效果。
- 尽量使用覆盖索引,避免使用
SELECT *查询所有记录。
case
Hint:假设 name 有常规索引 idx_user_name(二级索引)
SELECT 字段列表,决定了该索引是否为覆盖索引。
| 回表查询 | 覆盖查询 | |
|---|---|---|
| SQL | SELECT *FROM tb_user WHERE name='Arm'; |
SELECT id, nameFROM tb_user WHERE name='Arm'; |
| WHERE 字段列 | 条件为 name,查二级索引找到关联主键 | 同左 |
| 说明 | 二级索引只包含了 id 和 name | 同左 |
| 覆盖索引? | ❌ 除了 id 和 name,SELECT 还需要查询其它字段,需回表查询 | ✔ SELECT 查询列表恰好是 id 和 name,无需回表查询 |
使用
EXPALIN解释 DQL 执行,观察extra列:
using index condition:说明使用索引 + 回表查询。using where; using index:说明使用索引 + 覆盖索引。
4.3、八大失效情况
-
索引本身失效
-
最左前缀法则
-
范围查询:联合索引中某个列使用范围查询(
>和<),该列右侧的列索引失效。-
解决方案:在业务允许的情况下,改用
>=和<= -
示例:age 右侧的 status 列索引失效。
# 联合索引 CREATE INDEX idx_prof_age_status ON tb_user(profession, age, status); # 范围查询:age SELECT * FROM tb_user WHERE profession = '计算机科学' AND age < 20 AND status='0';
-
-
索引列运算:在索引列上进行运算,如函数运算。
SELECT * FROM tb_user WHERE age + 3 = 18; # 优化:在程序中或等号右侧,提前计算数值 SELECT * FROM tb_user WHERE age = 18 - 3; -
索引列函数:在索引列上调用了 MySQL 函数。
# 索引 CREATE INDEX idx_phone ON tb_user(phone); # 导致idx_phone失效 SELECT * FROM tb_user WHERE SUBSTRING(phone,8,4) = '6333'; -
字符串不加引号:数据库会隐式类型转换(数字 → 字符串),但索引失效。
# 正常 SELECT * FROM tb_user WHERE phone = '15882288333'; # 索引失效 SELECT * FROM tb_user WHERE phone = 15882288333; -
头部模糊查询:即
LIKE %内容-
原因:B+tree 索引是按顺序排列的,如果头部模糊查询,则无法根据确定的字母是去寻找索引中的特定结点,因此会进行全文扫描。
# 正常 SELECT * FROM tb_user WHERE profession LIKE '计算%'; SELECT * FROM tb_user WHERE profession LIKE '计%程'; # 失效:头部模糊匹配 SELECT * FROM tb_user WHERE profession LIKE '%工程'; SELECT * FROM tb_user WHERE profession LIKE '%工%'; -
解决方案:建立倒序索引,翻转查询条件。
CREATE INDEX idx_user_profession_reverse ON tb_user (REVERSE(profession)); SELECT * FROM tb_user WHERE REVERSE(profession) LIKE REVERSE('%工程');
-
-
OR 连接条件:OR 连接的条件,左右两侧的字段都有索引才生效。
-
数据分布影响:当查询记录数是表的大部分数据,MySQL 评估使用全表查询效率更高,索引失效。
4.4、五大设计原则
- 何时建立索引:
- 数据量大,且查询频繁的表。
- 常作为查询条件(WHERE)、排序(ORDER BY)、分组(GROUP BY)操作的字段。
- 尽量选择区分度高的列建立索引。
- 尽量建立唯一索引。
- 前缀索引:字符串类型的字段,且字段内容较长。
- 联合索引:尽量减少使用单列索引,联合索引往往可以覆盖索引,节省存储空间,避免回表查询,提高查询效率。
- 索引数量:要控制索引的数量。索引越多,维护开销越大,影响增删改的效率。
- NULL 值:如果索引列不能存储 NULL 值,需使用 NOT NULL 约束。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通