JVM5️⃣优化:编译期、运行期
1、编译期优化
Java 编译器,在编译期会自动生成和转换一些代码。
也称语法糖(syntactic sugar)
1.1、默认构造
public class Demo1 {
}
编译后相当于
public class Demo1 {
// 默认构造
public Candy1() {
super(); // 调用父类 Object 的无参构造
<init>":()V
}
}
1.2、自动拆装箱
JDK 5 引入自动拆装箱
// 源代码1
public class Demo2 {
public static void main(String[] args) {
Integer x = 1;
int y = x;
}
}
-
< JDK 5:无法通过编译,必须修改为以下代码。
-
>= JDK 5:编译期自动转换
// 源代码2 public class Demo2 { public static void main(String[] args){ Integer x = Integer.valueOf(1); int y = x.intValue(); } }
1.3、泛型
1.3.1、泛型擦除
JDK 5 引入泛型,编译为字节码后会将泛型擦除。
泛型信息在编译为字节码后就丢失了,实际的类型都会当作 Object 类型来处理。
public class Demo3 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
// 实际调用 List.add(Object e)
list.add(10);
// 实际调用 Object obj = List.get(int index);
Integer x = list.get(0);
}
}
-
在取值时,编译器会在字节码中做一个类型转换的操作。
// 将 Object转为Integer Integer x = (Integer)list.get(0); -
若变量 x 是基本类型,则相当于如下操作:
// 先将Object转为Integer,再拆箱 int x = ((Integer)list.get(0)).intValue();
1.3.2、本地变量类型表
泛型擦除,将字节码上的泛型信息擦除了。
但是本地变量类型表仍保留了方法参数泛型的信息,可以通过反射获取。
stack=2, locals=3, args_size=1
0: new #2 // class java/util/ArrayList
3: dup
4: invokespecial #3 // Method java/util/ArrayList."<init>":()V
7: astore_1
8: aload_1
9: bipush 10
11: invokestatic #4 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
14: invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z
19: pop
20: aload_1
21: iconst_0
22: invokeinterface #6, 2 // InterfaceMethod java/util/List.get:(I)Ljava/lang/Object;
27: checkcast #7 // class java/lang/Integer
30: astore_2
31: return
LineNumberTable:
line 8: 0
line 9: 8
line 10: 20
line 11: 31
LocalVariableTable:
Start Length Slot Name Signature
0 32 0 args [Ljava/lang/String;
8 24 1 list Ljava/util/List;
LocalVariableTypeTable:
Start Length Slot Name Signature
8 24 1 list Ljava/util/List<Ljava/lang/Integer;>;
反射获取
定义一个方法:方法返回值、参数列表都是泛型集合。
public Set<Integer> test(List<String> list, Map<Integer, Object> map) {
}
反射代码
// 获取指定参数类型的方法
Method test = Demo3.class.getMethod("test", List.class, Map.class);
// 获取方法的泛型参数
Type[] types = test.getGenericParameterTypes();
for (Type type : types) {
// 参数化类型(即泛型)
if (type instanceof ParameterizedType) {
// 打印
ParameterizedType parameterizedType = (ParameterizedType) type;
System.out.println("原始类型 - " + parameterizedType.getRawType());
Type[] arguments = parameterizedType.getActualTypeArguments();
for (int i = 0; i < arguments.length; i++) {
System.out.printf("泛型参数[%d] - %s\n", i, arguments[i]);
}
}
}
输出结果
原始类型 - interface java.util.List
泛型参数[0] - class java.lang.String
原始类型 - interface java.util.Map
泛型参数[0] - class java.lang.Integer
泛型参数[1] - class java.lang.Object
1.4、可变参数
JDK 5 引入。
public class Demo4 {
public static void foo(String... args) {
String[] array = args;
System.out.println(array);
}
public static void main(String[] args) {
foo("hello", "world");
}
}
可变参数...,实际上就是一维数组。
编译后相当于
public class Demo4 {
public static void foo(String[] args) {
String[] array = args; // 直接赋值
System.out.println(array);
}
public static void main(String[] args) {
foo(new String[]{"hello", "world"});
}
}
注:如果调用方法时没有传入任何参数,则相当于创建并传递了一个空数组,而不是传 null
// 源代码
public static void main(String[] args) {
foo();
}
// 编译后相当于
public static void main(String[] args) {
foo(new String[]{});
}
1.5、foreach 循环
- 数组:转换为 for。
- 集合:转换为迭代器。
1.5.1、数组
JDK 5 引入。
public class Demo5 {
public static void main(String[] args) {
// 数组赋初值的简化写法,也是编译期优化!
int[] array = {1, 2, 3, 4, 5};
for (int e : array) {
System.out.println(e);
}
}
}
数组 foreach 被转换为 for 循环。
public class Demo5 {
public Demo5() {
}
public static void main(String[] args) {
int[] array = new int[]{1, 2, 3, 4, 5
for(int i = 0; i < array.length; ++i) {
int e = array[i];
System.out.println(e);
}
}
1.5.2、集合
public class Demo5 {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1,2,3,4,5);
for (Integer i : list) {
System.out.println(i);
}
}
}
集合 foreach 被转换为迭代器循环
public class Demo5 {
public Demo5() {
}
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Iterator iter = list.iterator();
while(iter.hasNext()) {
Integer e = (Integer)iter.next();
System.out.println(e);
}
}
}
1.6、枚举类
JDK 5 引入了枚举类。
enum Gender {
MALE, FEMALE
}
枚举类被转换为一个继承了 Enum 的最终类。(单例 + 工厂)
-
name:枚举常量名称
-
ordinary:序号,从 0 开始
public final class Gender extends Enum<Sex> { public static final Gender MALE; public static final Gender FEMALE; private static final Gender[] $VALUES; static { MALE = new Gender("MALE", 0); FEMALE = new Gender("FEMALE", 1); $VALUES = new Gender[]{MALE, FEMALE}; } private Gender(String name, int ordinal) { super(name, ordinal); } public static Gender[] values() { return $VALUES.clone(); } public static Gender valueOf(String name) { return Enum.valueOf(Gender.class, name); } }
1.7、switch
JDK 7 开始,switch 可以搭配字符串和枚举类
1.7.1、switch 字符串
public class Demo6 {
public static void choose(String str) {
switch (str) {
case "hello": {
System.out.println("h");
break;
}
case "world": {
System.out.println("w");
break;
}
}
}
}
switch 字符串,被转换为两个搭配整数的 switch-case。
-
获取字符串的 hashCode,比较 hashCode 和 equals()。
-
根据第一个 switch-case 的结果,执行 case 块中的代码。
public class Candy6_1 { public Candy6_1() { } public static void choose(String str) { byte x = -1; switch(str.hashCode()) { case 99162322: // hello 的 hashCode if (str.equals("hello")) { x = 0; } break; case 113318802: // world 的 hashCode if (str.equals("world")) { x = 1; } } switch(x) { case 0: System.out.println("h"); break; case 1: System.out.println("w"); } } }
1.7.2、switch 枚举
enum Gender {
MALE, FEMALE
}
public class Demo7 {
public static void foo(Gender gender) {
switch (gender) {
case MALE:
System.out.println("男"); break;
case FEMALE:
System.out.println("女"); break;
}
}
}
编译后相当于:
- 创建一个合成类,映射枚举的 ordinary 与 数组元素。
- switch 字符串,被转换为 switch ordinary。
public class Candy7 {
static class $MAP {
// 数组大小即为枚举元素个数,里面存储case用来对比的数字
static int[] map = new int[2];
static {
// 枚举的 ordinal 从 0 开始
map[Sex.MALE.ordinal()] = 1;
map[Sex.FEMALE.ordinal()] = 2;
}
}
public static void foo(Sex sex) {
int x = $MAP.map[sex.ordinal()];
switch (x) {
case 1:
System.out.println("男");
break;
case 2:
System.out.println("女");
break;
}
}
}
1.8、try-with-resources
JDK 7 新增,资源对象需实现 AutoCloseable 接口。
-
可以不用写 finally 块,编译器会自动释放资源的代码。
-
常见的有 InputStream、OutputStream、Connection、Statement、ResultSet 等接口。
try(资源变量 = 创建资源对象){ } catch( ) { }
示例
public class Demo9 {
public static void main(String[] args) {
try(InputStream is = new FileInputStream("d:\\1.txt")) {
System.out.println(is);
} catch (IOException e) {
e.printStackTrace();
}
}
}
编译后相当于:在 try 块中创建资源对象,并再次使用 try-catch 语句释放资源。
分析 try 块
-
创建资源对象
-
在 try 内部再使用 try-catch 语句执行外部 try 块代码,若捕获异常则抛出。
-
若无异常,在 finally 中判断资源是否为空,非空则需要释放。
-
判断内部 try 块中是否发生异常
-
没有则直接关闭资源。
-
有,则再使用一次 try-catch 语句执行资源释放操作。
-
若在资源释放过程中,再次发生异常,则作为压制异常添加。
-
目的:不覆盖掉 try 块中的异常,保留所有可能出现的异常。
public class Demo9 { public Demo9() { } public static void main(String[] args) { try { InputStream is = new FileInputStream("d:\\1.txt"); // 可能出现的异常 Throwable t = null; try { System.out.println(is); } catch (Throwable e1) { t = e1; throw e1; } finally { // 资源非空,需要释放 if (is != null) { // 内部try块发生异常 if (t != null) { try { is.close(); } catch (Throwable e2) { // 资源释放出现异常,作为被压制异常添加 t.addSuppressed(e2); } } else { is.close(); } } } } catch (IOException e) { e.printStackTrace(); } } }
-
-
1.9、方法重写桥接
子类可以重写父类的方法。
重写方法的返回值,必须是与父类返回值类型相同,或父类返回值的子类型。
class A {
public Number m() {
return 1;
}
}
class B extends A {
@Override
public Integer m() {
return 2;
}
}
Class B 编译后相当于:生成一个桥接方法,作为真正的重写方法。
桥接方法调用子类中声明的方法。
class B extends A {
public Integer m() {
return 2;
}
// 真正重写了父类 public Number m() 方法
public synthetic bridge Number m() {
return m();
}
}
1.10、匿名内部类
定义匿名内部类
public class Demo11 {
public static void main(String[] args) {
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("ok");
}
};
}
}
编译后相当于:生成一个额外类,通过构造器创建。
public class Demo11 {
public static void main(String[] args) {
Runnable runnable = new Candy11$1();
}
}
// 额外类
final class Demo11$1 implements Runnable {
Candy11$1() {
}
public void run() {
System.out.println("ok");
}
}
定义匿名内部类,且引用局部变量
内部类引用了方法参数 x。
public class Candy11 {
public static void test(final int x) {
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("ok:" + x);
}
};
}
}
编译后相当于:生成一个额外类,将局部变量作为构造器参数传入。
public class Candy11 {
public static void test(final int x) {
Runnable runnable = new Candy11$1(x);
}
}
// 额外类
final class Candy11$1 implements Runnable {
int val$x;
Candy11$1(int x) {
this.val$x = x;
}
public void run() {
System.out.println("ok:" + this.val$x);
}
}
在 Java SE 中,当匿名内部类引用局部变量时,局部变量必须是 final 的。
原因:局部变量作为构造器参数传入额外类,并且额外类生成后就不会再改变,因此局部变量也不允许改变。
2、运行期优化
2.1、说明
早期优化: 编译期优化
晚期优化:运行期优化
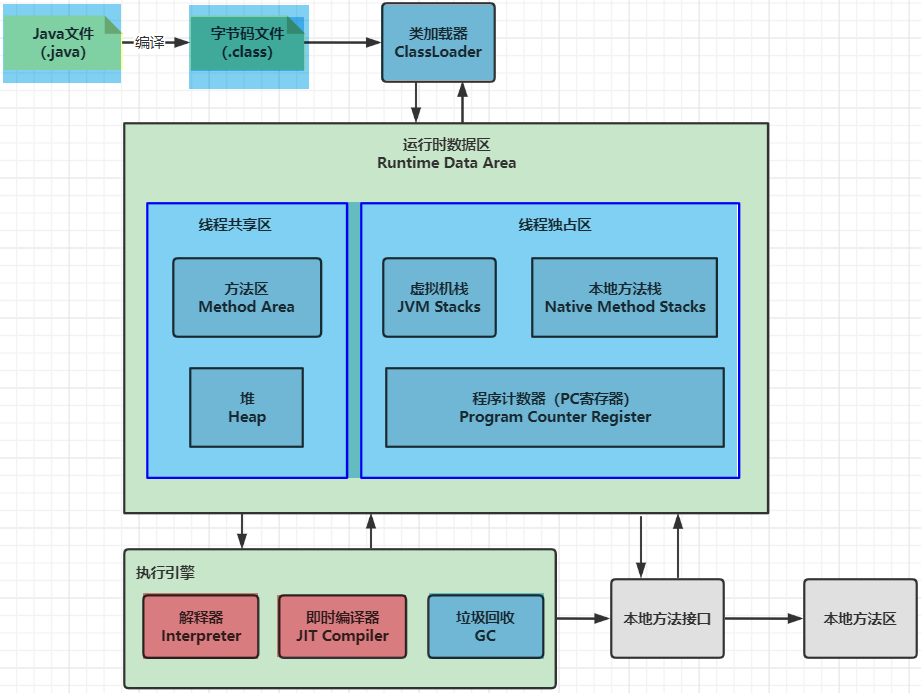
2.1.1、JVM 结构
两个结构,一个概念
- 解释器(Interpreter):对 Java 程序进行解释执行(平台无关性)
- 即时编译器(Just In Time Compiler):为提高热点代码的执行效率,将热点代码编译成与本地相关的机器码,并进行各层次的优化(平台有关性)
- Client Compiler:也叫 C1 编译器
- Server Compiler:也叫 C2 编译器
- 热点代码(Hot Spot Code):当 JVM 发现某个方法或代码块的运行特别频繁,就认定是热点代码。
2.1.2、工作机制
注:JIT 编译器对于代码的优化建立在字节码或机器码之上,而不是修改 Java 源码。
- 当程序启动时:解释器可以首先发挥作用,省去编译的时间,直接将代码解释执行。
- 随着代码执行次数越来越多:JIT 编译器开始发挥作用,将代码编译成本地机器码,提高执行效率。
2.1.3、分层编译
Tiered Compilation
了解一个概念:Profiling:性能监控功能。
- 部分开启:方法调用次数、回边次数统计等;
- 完全开启:除了部分开启的统计信息外,还包括分支跳转、虚方法调用版本等全部的统计信息。
根据编译器编译、优化的规模与耗时,划分出不同的编译层次。
| 使用 | 执行方式 | 开启 Profiling | |
|---|---|---|---|
| 第 0 层 | 解释器 | 解释 | 不开启 |
| 第 1 层 | C1 编译器 | 编译 | 不开启 |
| 第 2 层 | C1 编译器 | 编译 | 部分开启 |
| 第 3 层 | C1 编译器 | 编译 | 完全开启 |
| 第 4 层 | C2 编译器 | 编译 | 开启,并进行激进优化 |
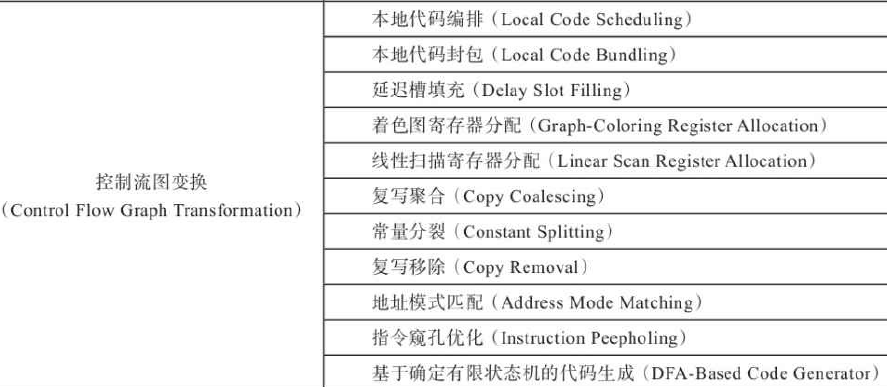
2.2、优化技术
编译器的优化技术有多种,如下所示。


2.2.1、实例
通过示例,展示其中的几种优化技术。
假设 foo() 是热点代码
static Class A {
int value;
final int getValue() {
return value;
}
}
public void foo () {
// a是A的对象实例
x = a.getValue();
y = a.getValue();
sum = x + y;
}
-
方法内联(Inlining)
-
去除方法调用成本:如查找方法版本、建立栈帧
-
为其他优化建立良好的基础,因此通常作为优化序列的前面
public void foo () { x = a.value; y = a.value; sum = x + y; }
-
-
冗余访问消除(Redundant Loads Elimination)
-
由于 x 和 y 访问同一个变量(假设变量值没有被修改),可以保证 x 和 y 的值相同。
-
因此对 y 赋值时,不用去访问 value 变量,直接将局部变量 x 的值赋给 y 即可。
-
若
a.value是一项表达式,此项优化可以视为公共子表达式消除(Common SubexpressionElimination)public void foo () { x = a.value; y = x; sum = x + y; }
-
-
复写传播(Copy Propagation)
-
在程序的逻辑中,x 和 y 完全相等,没有必要用一个额外的变量 y。
-
因此用 x 来代替 y。
public void foo() { x = A.value; x = x; sum = x + x; }
-
-
无用代码消除(Dead Code Elimination)
-
永远不会被执行的代码
-
完全没有意义的代码。
public void foo() { x = A.value; sum = x + x; }
-
经过四次优化后,代码效果完全一致,但是代码省略了许多语句。
2.2.2、代表性技术
方法内联(重要技术)
- 去除方法调用成本:如查找方法版本、建立栈帧
- 为其他优化建立良好的基础,因此通常作为优化序列的前面
逃逸分析(前沿技术)
逃逸:在方法内部定义的局部变量,被外部方法所引用。
- 方法逃逸:如作为调用参数传递到其他方法
- 线程逃逸:如赋值给可以在其他线程中访问的实例变量
- 不逃逸、方法逃逸、线程逃逸,是对象从低祷告的不同逃逸程度。
公共子表达式消除(语言无关)
-
公共子表达式:如果表达式 E 在之前已经被计算过了,并且 E 中所有变量的值都没有发生变化,称 E 称公共子表达式。
-
对于公共子表达式,没必要花时间重新计算,直接用前面计算过的表达式结果代替 E
// 举个例子 int x = (a * b) + c + (b * a) // 消除后 int x = E + 12 + c * E
数组边界检查消除(语言有关)
数组边界检查:
Java 中访问数据元素时,系统会自动进行上下界的范围检查。
超出范围则抛出数组下标越界异常。
为了安全,必须进行数组边界检查,但是没有必要在每次访问的时候都进行。
示例:
- 数组下标是常量:如 foo[3],只要在编译期分析确定 foo.length 并判断下标 3 没有越界,执行的时候就无需判断。
- 循环访问数组:如 for 循环,只要在编译期分析确定循环变量的范围永远在 [0, foo.length) 之间,那么在循环中就可以把整个数组数组边界检查消除了。

