MyBatis④日志 & 分页 & 缓存
1、日志
通过日志,可方便地对数据库操作进行调试。
开启日志功能:在 MyBatis 核心配置文件的 settings 中,设置日志工厂的实现类。
-
name:
logImpl,区分大小写。 -
value:日志工厂实现类,不区分大小写。
<settings> <setting name="logImpl" value="具体实现类"/> </settings>
常用日志工厂
- MyBatis 内置日志:无需编写配置文件。
- STDOUT_LOGGING:标准输出日志。
- NO_LOGGING:最小化日志产生的数量(并不是关闭日志)。
- 其它日志:如 LOG4J,需要编写配置文件。
1.1、STDOUT_LOGGING
无需编写配置文件。
-
MyBatis 核心配置文件设置
<settings> <setting name="logImpl" value="STDOUT_LOGGING"/> </settings> -
测试:查询全部用户
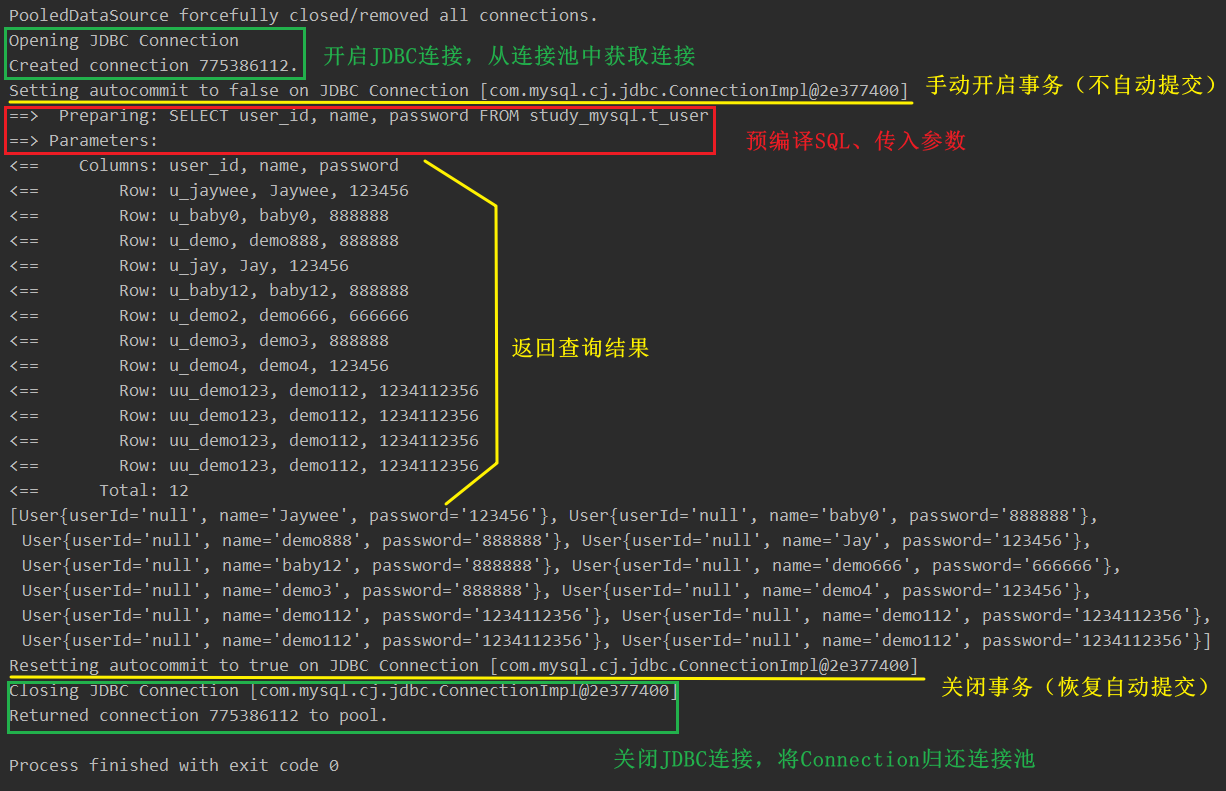
1.2、LOG4J(❗)
Apache 开源项目。通过配置文件来修改日志功能,无需修改应用代码。
相比 MyBatis 内置标准日志工厂,可以自定义日志配置。
- 输出位置:控制台、文件、GUI 组件等。
- 输出格式
- 日志级别:更加细致地控制日志的生成过程。
1.2.1、环境搭建
-
导入依赖
<!-- https://mvnrepository.com/artifact/log4j/log4j --> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> -
MyBatis 核心配置文件
<settings> <setting name="logImpl" value="LOG4J"/> </settings>
1.2.2、LOG4J 配置文件(❗)
使用 LOG4J 必须编写配置文件,否则报错。
① 文件基本格式
-
根配置
- 语法:
log4j.rootLogger = [ level ] , appenderName, … - 将指定级别以上的日志信息,输出到指定位置,低于指定级别的日志信息不会被输出。
- 语法:
-
日志输出位置的相关配置
- appender 及相关选项
- 布局(输出格式)及相关选项
-
日志级别:官方建议实用的 4 个日志级别(优先级从高到低)
-
ERROR:严重错误。
-
WARN:警告,如 session 丢失。
-
INFO:要显示的信息。
-
DEBUG:调试信息。
# 根配置 log4j.rootLogger = [ level ] , appenderName, ... # 日志输出位置的相关配置 log4j.appender.appenderName = log4j.appender.appenderName.选项 = appender.appenderName.layout = appender.appenderName.layout.选项 = # 自定义日志级别 xxx = DEBUG xxx = INFO
-
② 常用符号含义
| 英文 | 含义 | 备注 | |
|---|---|---|---|
| %p | priority | 日志级别 | DEBUG、INFO、WARN、ERROR、FATAL |
| %d | date | 日期 | 默认格式 ISO8601,可指定格式 |
| %c | class | 日志信息所属的类目 | 通常是所在类的全限类名 |
| %t | thread | 输出该日志信息的线程名 | |
| %L | line | 代码中的行号 | |
| %m | message | 代码中指定的消息 | 即输出的日志内容 |
| %n | newline | 回车换行符 | Windows 为\r\n,Unix 为 \n |
1.2.3、示例
log4j.properties
-
根配置:输出 DEBUG 以上的日志信息,输出位置为 console 和 file(控制台、文件)
-
日志输出位置的相关配置:控制台、文件
- appender 及相关选项
- 输出格式(布局 layout)及相关选项
log4j.rootLogger=DEBUG,console,file # 输出到控制台的相关配置 log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.Target=System.out log4j.appender.console.Threshold=DEBUG log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=[%p] %d{HH:mm:ss:SSS} - %m%n # 输出到文件的相关配置 log4j.appender.file=org.apache.log4j.RollingFileAppender log4j.appender.file.File=./log/userLog.log log4j.appender.file.MaxFileSize=10mb log4j.appender.file.Threshold=DEBUG log4j.appender.file.layout=org.apache.log4j.PatternLayout log4j.appender.file.layout.ConversionPattern=[%p] %d{yyyy-MM-dd HH:mm:ss:SSS} - %m%n
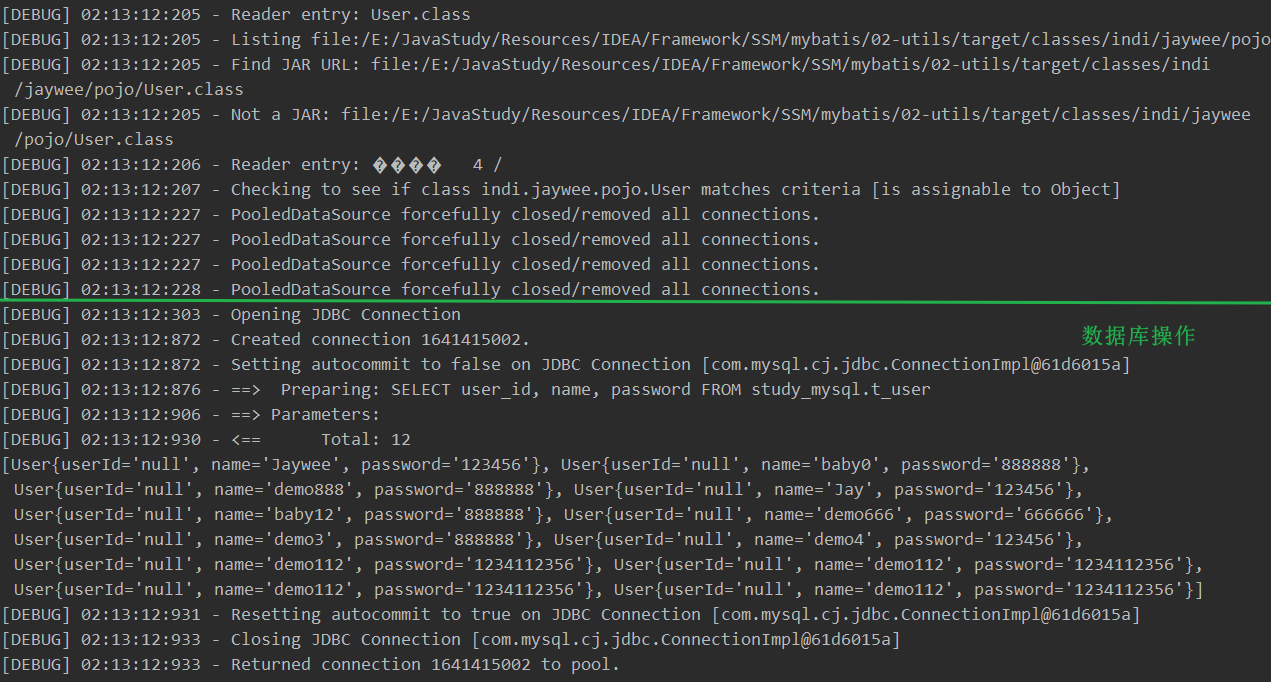
测试:查询所有用户
-
控制台
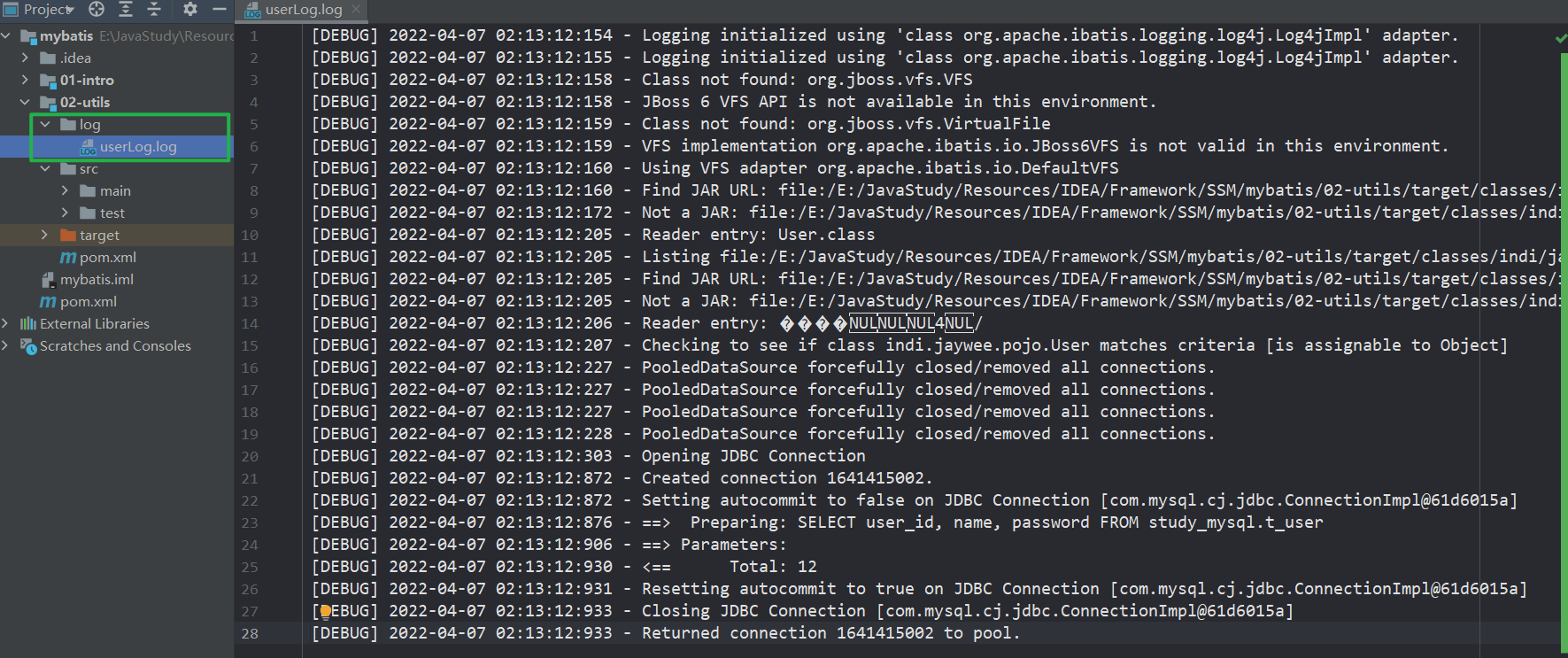
-
文件
1.3、Java 使用 LOG4J
1.3.1、使用
位于
org.apache.log4j.LoggerLOG4J 的核心类,处理大部分日志操作。
- 编写 log4j 配置文件
- 获取 Logger
Logger.getLogger(String name):获取指定 name 的 logger,没有则新建名为 name 的 logger。Logger.getLogger(Class clazz):即 getLogger(clazz.getName)
- 常用方法:对应日志级别(DEBUG、INFO、WARN、ERROR)
示例
-
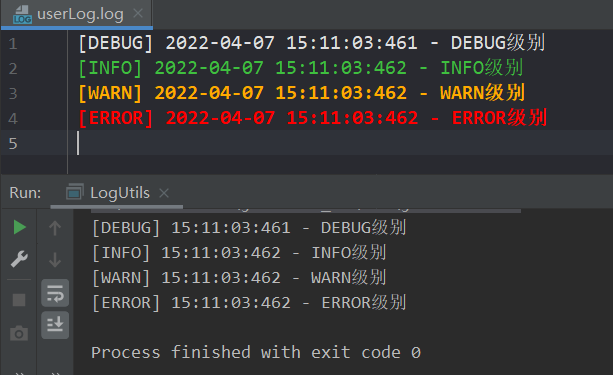
测试代码
public static void main(String[] args) { log(); } public static void log(){ Logger myLog = Logger.getLogger("myLog"); myLog.debug("123"); myLog.info("123"); myLog.warn("123"); myLog.error("123"); } -
日志输出
1.3.2、工具类
可将 Logger 封装为工具类,以便项目使用。
示例
public class LogUtils {
public static final Logger LOGGER;
static {
LOGGER = Logger.getLogger("myLog");
}
public static void debug(Object message) {
LOGGER.debug(message);
}
public static void info(Object message) {
LOGGER.info(message);
}
}
2、分页
分页:减少数据处理量,提高查询效率,提高性能。
常见分页方式
- 数据库层面
- 使用 LIMIT 关键字
- 分页插件:PageHelper
- Java 层面:RowsBounds 分页(了解,不建议使用)
2.1、LIMIT
LIMIT 语法
-
startIndex:起始索引,下标从 0 开始。
-
pageSize:页面大小
SELECT 列名 FROM 表名 LIMIT startIndex, pageSize
2.1.1、Mapper
-
Mapper 接口:方法参数列表为起始页、页面大小
List<User> listUsersLimit(@Param("startIndex") int startIndex, @Param("pageSize") int pageSize); -
Mapper.xml:按分页语法编写 SQL。
<select id="listUsersLimit" resultType="user"> SELECT user_id, name, password FROM study_mysql.t_user LIMIT #{startIndex}, #{pageSize} </select>
2.1.2、测试
-
代码
@Test public void testListUsersLimit() { int startIndex = 10; int pageSize = 20; SqlSession sqlSession = MyBatisUtils.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); List<User> userList = mapper.listUsersLimit(startIndex, pageSize); for (User user : userList) { System.out.println(user); } sqlSession.close(); } -
结果
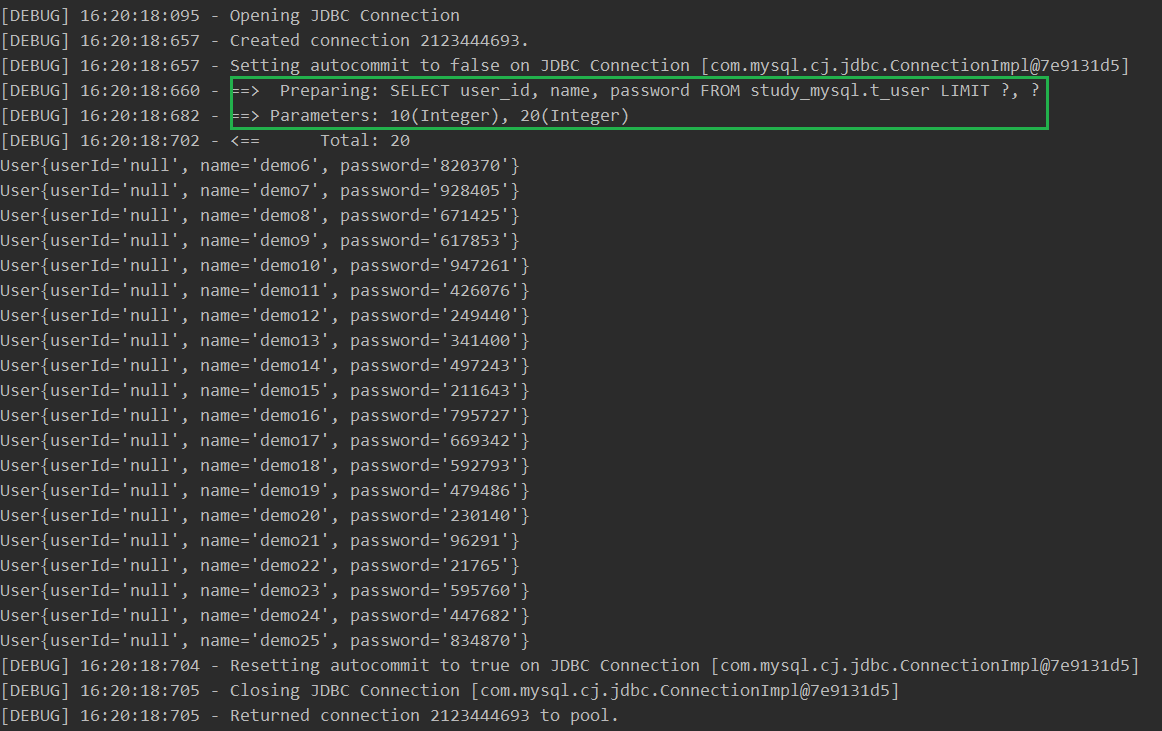
2.2、PageHelper(❗)
PageHelper:底层封装 LIMIT 语法,简化开发。
导入依赖:PageHelper、Java SQL 解析器
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.3.0</version>
</dependency>
<dependency>
<groupId>com.github.jsqlparser</groupId>
<artifactId>jsqlparser</artifactId>
<version>4.3</version>
</dependency>
2.2.1、插件配置
MyBatis 核心配置文件:
plugins
-
旧版 PageHelper:注册 PageHelper,配置方言。
<plugins> <plugin interceptor="com.github.pagehelper.PageHelper"> <property name="dialect" value="mysql"/> </plugin> </plugins> -
新版 PageHelper:注册 PageInterceptor,MyBatis 自动识别方言。
<plugin interceptor="com.github.pagehelper.PageInterceptor"/>
2.2.2、使用
以普通查询所有用户为例
-
Mapper 接口
List<User> listUsers(); -
Mapper.xml
<select id="listUsers" resultType="user"> SELECT user_id, name, password FROM study_mysql.t_user </select>
步骤
-
设置分页参数(在接口方法调用之前)
-
调用接口方法。
// 分页参数 int startPage = 2; int pageSize = 20; PageHelper.startPage(startPage, pageSize); SqlSession sqlSession = MyBatisUtils.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); // 接口方法 List<User> userList = mapper.listUsers(); for (User user : userList) { System.out.println(user); } sqlSession.close(); -
结果:SQL 语句带有 LIMIT 语法,说明 PageHelper 自动进行分页。
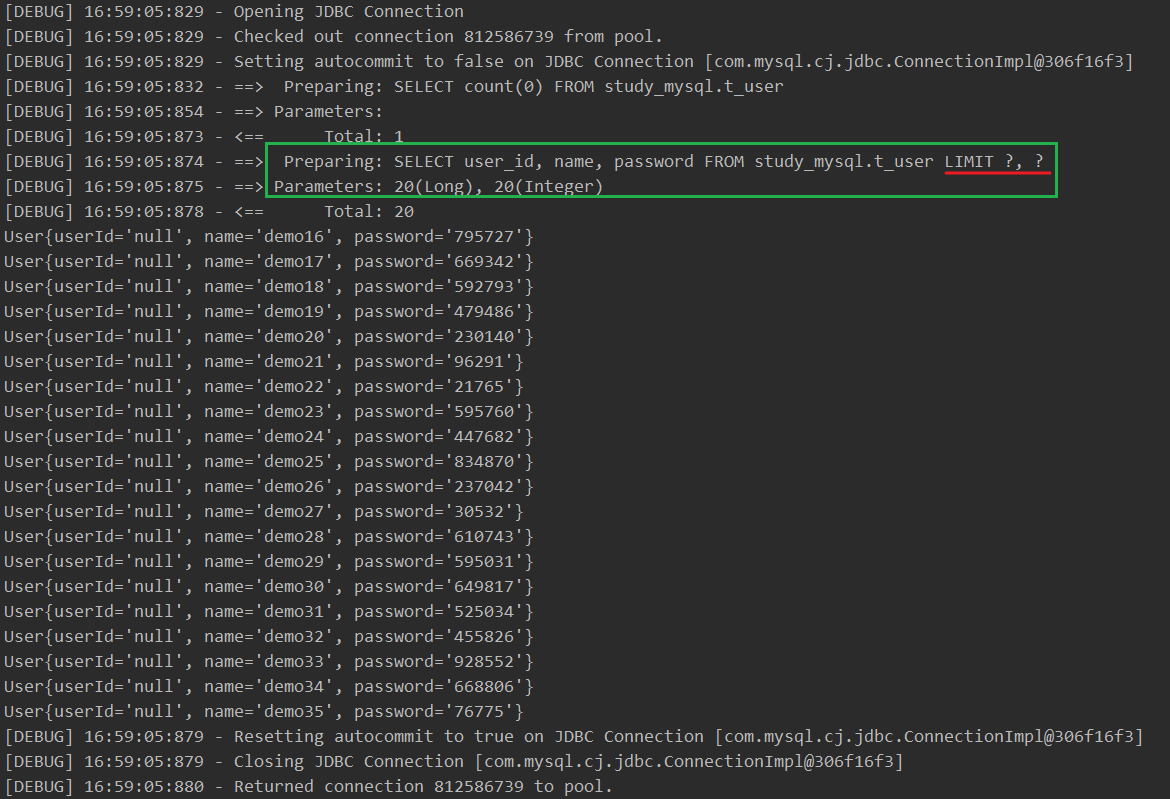
2.3、*RowBounds
仅作了解,不建议使用
| LIMIT | RowBounds | |
|---|---|---|
| 分页层面 | 物理分页,在数据库层面实现 | 逻辑分页,在 Java 层面实现 |
| 本质 | 根据分页参数,查询分页范围内的指定记录 | 先查询所有记录,再根据参数范围来过滤(skip)数据 |
2.2.1、使用
以普通查询所有用户为例
-
Mapper 接口
List<User> listUsers(); -
Mapper.xml
<select id="listUsers" resultType="user"> SELECT user_id, name, password FROM study_mysql.t_user </select>
步骤
-
实例化 RowBounds,参数为起始索引和页面大小。
-
通过 sqlSession 执行方法,参数依次为:
-
statement:即 Mapper.xml 中的标签。
-
parameter:传递给 statement 的参数。
-
rowBounds 对象
RowBounds rowBounds = new RowBounds(0, 10); SqlSession sqlSession = MyBatisUtils.getSqlSession(); List<User> userList = sqlSession.selectList("listUsers", null, rowBounds); for (User user : userList) { System.out.println(user); } sqlSession.close();
-
-
结果:SQL 语句没有 LIMIT 语法,说明 RowBounds 是查询所有记录,并进行过滤。
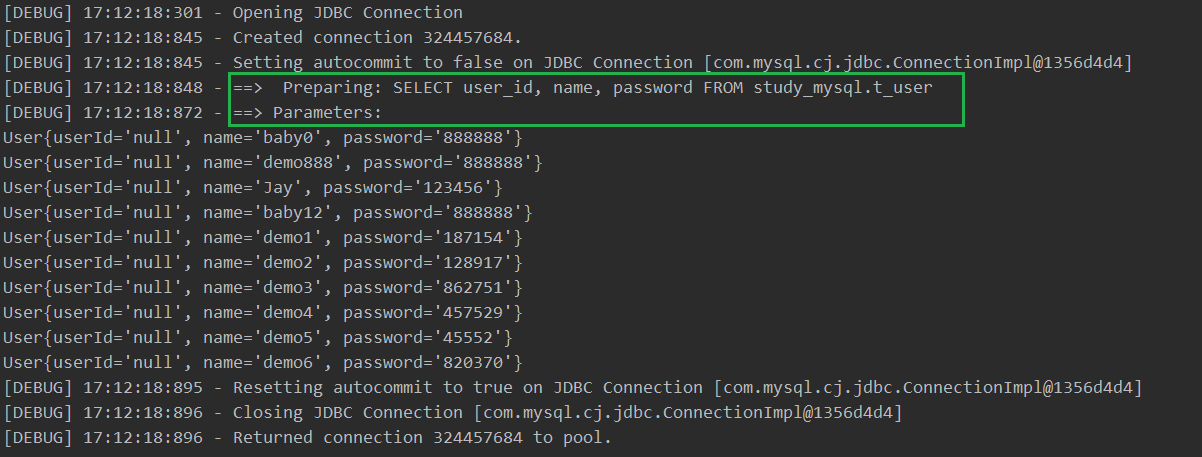
3、缓存
3.1、说明
3.1.1、缓存的使用
缓存(Cache):存储于内存中的临时数据。
- 若没有使用缓存:用户每次查询数据时都直接读取磁盘,浪费大量磁盘 IO,系统开销大,效率低。
- 使用缓存:将查询数据缓存在内存中,提高查询效率,提高并发性能。
缓存的使用
- 建议使用:频繁查询,且不频繁修改的数据。
- 不适用:不经常查询,或经常修改的数据。
3.1.2、MyBatis 缓存机制(❗)
-
查询操作会进行缓存,增删改操作会刷新缓存。
-
一次会话中
- 查询结果,存放于一级缓存。
- 会话关闭时,一级缓存失效,其中的数据保存到二级缓存中。
-
开启一个会话:先读取二级缓存,再读取一级缓存,再访问数据库。
-
不同 namespace(Mapper)具有不同的二级缓存。
3.2、一级缓存
会话缓存
- 默认情况下,MyBatis 开启一级缓存。
- 有效范围:一次会话,即缓存在一个 SqlSession 从获取到关闭这个区间。
3.2.1、示例代码
根据用户名查询用户
-
Mapper 接口
List<User> listUsersByName(String name); -
Mapper.xml
<select id="listUsersByName" resultType="user"> SELECT user_id, name, password FROM study_mysql.t_user WHERE name = #{name} </select>
3.2.2、测试
- 同一会话,查询相同数据。
- 同一会话,查询不同数据。
- 不同会话,查询相同数据。
① 同一会话,查询相同数据
-
获取 sqlSession,获取 Mapper。
-
执行相同查询。
-
关闭会话。
SqlSession sqlSession = MyBatisUtils.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); List<User> userList1 = mapper.listUsersByName("u_demo"); System.out.println("第1次执行结束"); List<User> userList2 = mapper.listUsersByName("u_demo"); System.out.println("第2次执行结束"); System.out.println(userList1 == userList2); sqlSession.close(); -
结果
-
第 1 次查询时编译并执行了 SQL,第 2 次查询时直接返回缓存数据。
-
两次查询结果是同一个对象引用。
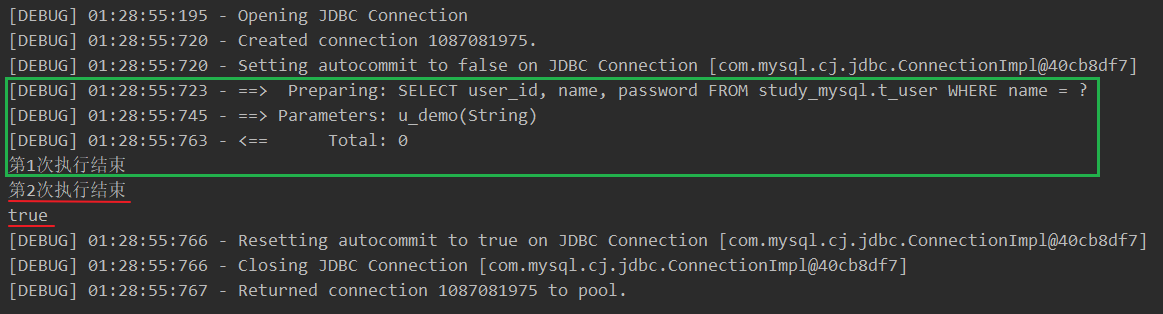
-
② 同一会话,查询不同数据
-
代码
SqlSession sqlSession = MyBatisUtils.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); List<User> userList1 = mapper.listUsersByName("u_demo1"); System.out.println("第1次执行结束"); List<User> userList2 = mapper.listUsersByName("u_demo2"); System.out.println("第2次执行结束"); System.out.println(userList1 == userList2); sqlSession.close(); -
结果:两次查询都编译并执行了 SQL。
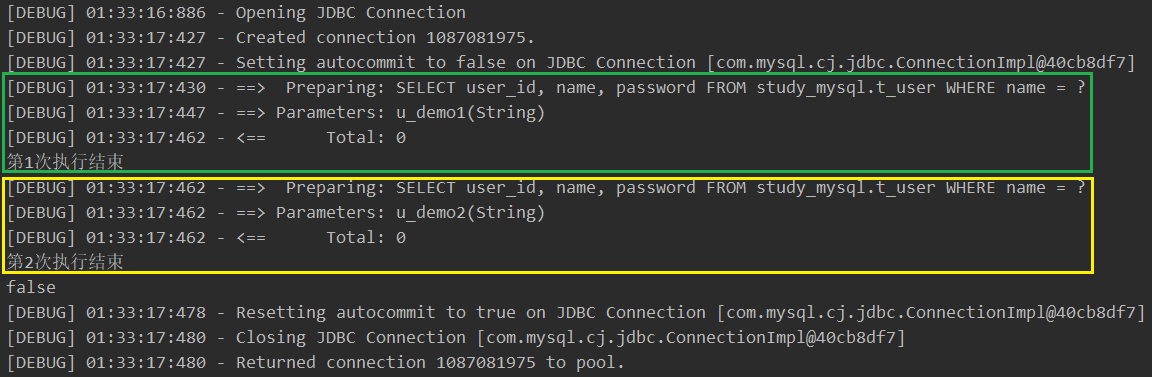
③ 不同会话,查询相同数据
-
代码
// 获取会话对象 SqlSession sqlSession1 = MyBatisUtils.getSqlSession(); UserMapper mapper1 = sqlSession1.getMapper(UserMapper.class); List<User> userList1 = mapper1.listUsersByName("u_demo"); System.out.println("第1次执行结束"); // 获取另一个会话对象 SqlSession sqlSession2 = MyBatisUtils.getSqlSession(); UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class); List<User> userList2 = mapper2.listUsersByName("u_demo"); System.out.println("第2次执行结束"); // 打印结果 System.out.println(userList1 == userList2); sqlSession1.close(); sqlSession2.close(); -
结果
-
开启了 2 个会话对象,分别编译并执行了 SQL。
-
两次查询结果是不同的对象引用。
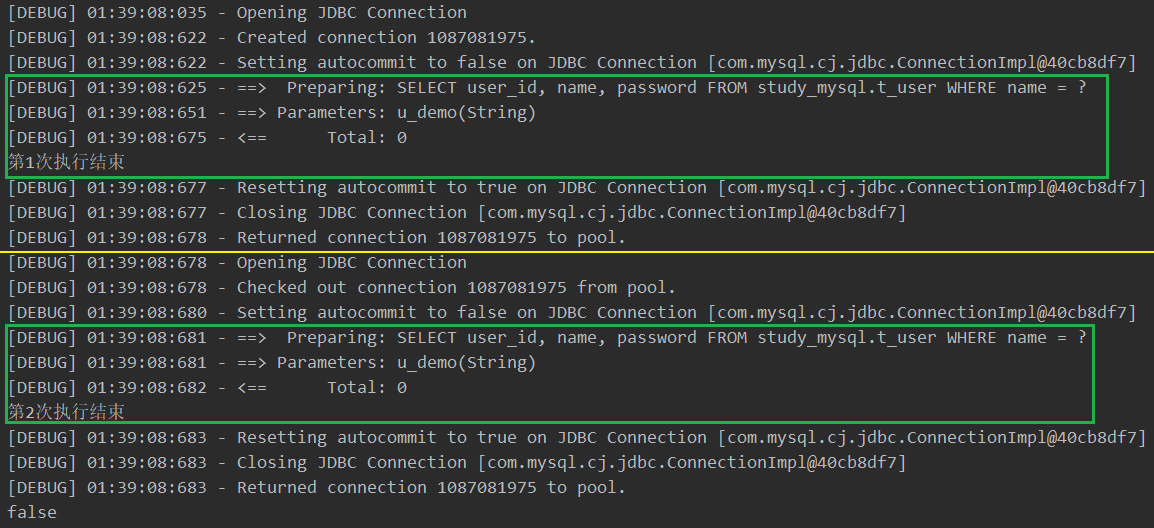
-
3.2.3、缓存刷新
-
MyBatis 会缓存查询语句的结果。
-
增删改语句会刷新缓存,此前所有已缓存的结果失效。
-
手动刷新缓存
sqlSession.clearCache();
3.3、二级缓存
全局缓存
-
有效范围:基于
namespace,即缓存在一个 Mapper 中。 -
注意:涉及的 POJO 需实现 Serializable 接口。
-
默认配置:
- 基于 LRU 算法,清除不需要的缓存。
- 不会定时进行刷新缓存。
- 保存最多 1024 个列表或对象的引用 。
- 分为读/写缓存
- 获取的对象不是线程共享资源,一个线程的写操作不影响其它线程。
- 保证线程安全问题
-
自定义缓存配置:在 Mapper.xml 中开启二级缓存时,进行显式配置。
3.3.1、开启二级缓存
-
MyBatis 核心配置文件:
settings-
cacheEnabled:默认 true,为提高可读性而进行显式配置。
<settings> <setting name="cacheEnabled" value="true"/> </settings>
-
-
Mapper.xml:
<cache/>-
默认实现
<cache/> -
自定义缓存配置
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
-
3.3.2、测试
-
未开启二级缓存:一级缓存的测试③中,不同会话的缓存无法共享。
-
开启二级缓存
-
第 1 个会话
- 开启会话,二级缓存和一级缓存中都没有相应数据。
- 预编译并执行 SQL,缓存查询结果。
- 关闭会话,一级缓存数据保存到二级缓存。
-
第 2 个会话
-
开启会话,从二级缓存中读取到缓存数据(Cache Hit)
-
注意:虽然读取到二级缓存,但不属于同一个对象引用。
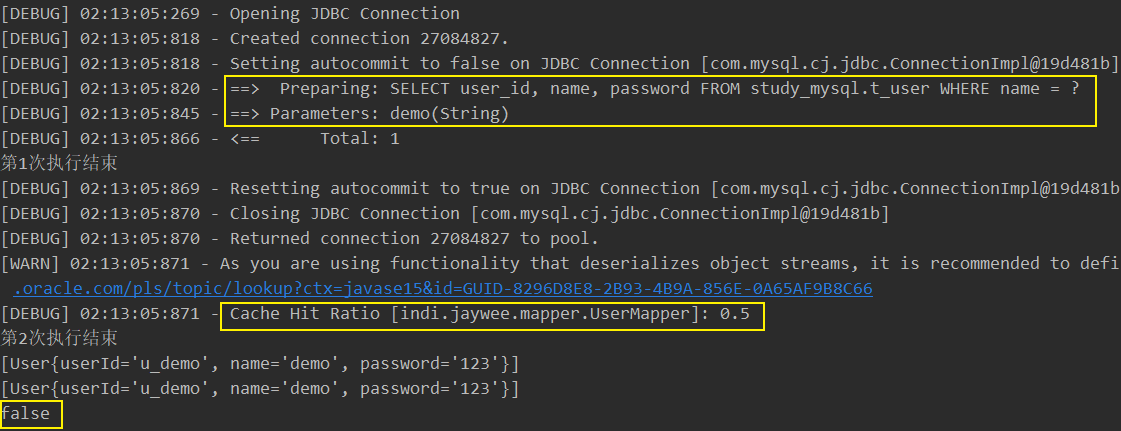
-
-
3.4、Ehcache
- 更完善地自定义缓存配置。
- Redis 的雏形。
使用步骤
-
导入依赖:
mybatis-ehcache<!-- https://mvnrepository.com/artifact/org.mybatis.caches/mybatis-ehcache --> <dependency> <groupId>org.mybatis.caches</groupId> <artifactId>mybatis-ehcache</artifactId> <version>1.2.2</version> </dependency> -
编写 ehcache 配置文件:
ehcache.xml<?xml version="1.0" encoding="UTF-8" ?> <ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd" updateCheck="false"> <diskStore path="./tmpdir/Tmp_EhCache"/> <defaultCache eternal="false" maxElementsInMemory="10000" overflowToDisk="false" diskPersistent="false" timeToIdleSeconds="1800" timeToLiveSeconds="259200" memoryStoreEvictionPolicy="LRU"/> <cache name="cloud_user" eternal="false" maxElementsInMemory="5000" overflowToDisk="false" diskPersistent="false" timeToIdleSeconds="1800" timeToLiveSeconds="1800" memoryStoreEvictionPolicy="LRU"/> </ehcache> -
使用 Ehcache 缓存:
Mapper.xml<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律