python学习(25) BeautifulSoup介绍和实战
BeautifulSoup是python的html解析库,处理html非常方便
BeautifulSoup 安装
pip install beautifulsoup4
BeautifulSoup 配合的解析器
# python标准库 BeautifulSoup(html,'html.parser') #lxml HTML 解析器 BeautifulSoup(html,'lxml) #html5lib BeautifulSoup(html,'html5lib')
python 标准库解析器不需要第三方库,处理效率一般,lxml比较快,需要C语言库支持,html5lib不依赖第三方库,但是效率比较低,容错好。
导入BeautifulSoup并使用
from bs4 import BeautifulSoup html = '''div id="sslct_menu" class="cl p_pop" style="display: none;"> <span class="sslct_btn" onClick="extstyle('')" title="默认"><i></i></span></div> <ul id="myitem_menu" class="p_pop" style="display: none;"> <li><a href="https://www.aisinei.org/forum.php?mod=guide&view=my">帖子</a></li> <li><a href="https://www.aisinei.org/home.php?mod=space&do=favorite&view=me">收藏</a></li>''' bs = BeautifulSoup(html) print(bs.prettify())
bs.prettify为格式化输出,效果如下

同样可以用本地的html文本创建,也可以添加解析器lxml
s =BeautifulSoup('test.html','lxml') print(s.prettify())
效果是一样的
BeautifulSoup属性选择和处理
处理节点tag
html2 = ''' <li class="bus_postbd item masonry_brick"> <div class="bus_vtem"> <a href="https://www.aisinei.org/thread-17846-1-1.html" title="XIUREN秀人网 2018.11.13 NO.1228 猫宝 [50+1P]" class="preview" target="_blank"> "hello world" <img src="https://i.asnpic.win/block/a4/a42e6c63ef1ae20a914699f183d5204b.jpg" width="250" height="375" alt="XIUREN秀人网 2018.11.13 NO.1228 猫宝 [50+1P]"/> <span class="bus_listag">XIUREN秀人网</span> </a> <a href="https://www.aisinei.org/thread-17846-1-1.html" title="XIUREN秀人网 2018.11.13 NO.1228 猫宝 [50+1P]" target="_blank"> <div class="lv-face"><img src="https://www.aisinei.org/uc_server/avatar.php?uid=2&size=small" alt="发布组小乐"/></div> <div class="t">XIUREN秀人网 2018.11.13 NO.1228 猫宝 [50</div> <div class="i"><span><i class="bus_showicon bus_showicon_v"></i>6402</span><span><i class="bus_showicon bus_showicon_r"></i>1</span></div> </a> </div> </li> ''' s2 = BeautifulSoup(html2,'lxml') print(s2.a) print(s2.a.name) print(s2.a.attrs)
节点tag 就是li,a,div这类,可以看出通过属性访问,选择出第一个匹配的结果。节点Tag也有名字,通过.name访问。通过.attrs获取节点的属性。

获取节点文本通过.string即可,获取节点的子孙节点的文本可以通过text
print(s2.a.string) print(s2.a.text)
节点的子孙节点
获取节点的子节点,可以用.contents,也可以用.children, .contents返回列表形式的直接子节点, .contents返回的是一个可迭代对象。
print(s2.div.contents) print(s2.div.children) print(s2.div.contents[0]) for i in s2.div.children: print(i)
前两个输出一样,后边的分别取第一个节点,以及遍历每一个节点。同样的道理,子孙节点,父节点,祖父节点,兄弟节点都采用这种方式获取
#孙子节点 print(s2.div.descendants) #祖先节点 print(s2.div.parents) #直接父节点 print(s2.div.parent) #下一个兄弟节点 print(s2.a.next_sibling) #前一个兄弟节点 print(s2.a.previous_sibling)
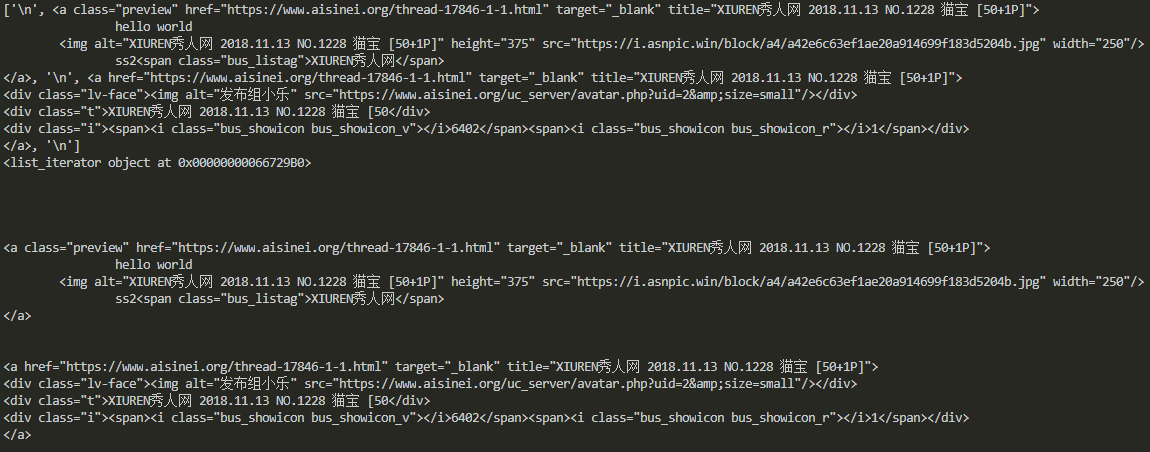
节点的属性获取
print(s2.a["href"]) print(s2.a.get("href"))
如上两种方式都能获取属性

方法选择
常用的筛选函数有find_all和find,findall返回所有匹配的结果,find返回匹配结果的
print(s2.find('a')) print(s2.find_all('a')) print(s2.find_all(re.compile("^div"))) print(s2.find_all(["div","li"]))
可以看出findall传递参数可以是字符串,正则表达式,列表等等,其他的方法类似属性访问一样,有find_parents(),find_next_siblings()等等,用的时候再查吧。
BeautifulSoup 支持CSS选择器
如果你熟悉css选择器的语法,BeautifulSoup同样支持,而且非常便利。
#查找节点为div的数据 print(s2.select('a')) #查找class为bus_vtem的节点 print(s2.select('.bus_vtem')) #查找id为ps的节点 print(s2.select('#ps'))
到目前为止基本的BeautifulSoup已经介绍完,下面实战抓取一段html,并用BeautifulSoup解析提取我们需要的数据,这里解析一段美女图更新首页,提取其中的资源地址。
#-*-coding:utf-8-*- import requests import re import time from lxml import etree from bs4 import BeautifulSoup USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0' COOKIES = '__cfduid=d78f862232687ba4aae00f617c0fd1ca81537854419; bg5D_2132_saltkey=jh7xllgK; bg5D_2132_lastvisit=1540536781; bg5D_2132_auth=479fTpQgthFjwwD6V1Xq8ky8wI2dzxJkPeJHEZyv3eqJqdTQOQWE74ttW1HchIUZpgsyN5Y9r1jtby9AwfRN1R89; bg5D_2132_lastcheckfeed=7469%7C1541145866; bg5D_2132_ulastactivity=2bbfoTOtWWimnqaXyLbTv%2Buq4ens5zcXIiEAhobA%2FsWLyvpXVM9d; bg5D_2132_sid=wF3g17; Hm_lvt_b8d70b1e8d60fba1e9c8bd5d6b035f4c=1540540375,1540955353,1541145834,1541562930; Hm_lpvt_b8d70b1e8d60fba1e9c8bd5d6b035f4c=1541562973; bg5D_2132_lastact=1541562986%09home.php%09spacecp' class AsScrapy(object): def __init__(self,pages=1): try: self.m_session = requests.Session() self.m_headers = {'User-Agent':USER_AGENT, #'referer':'https://www.aisinei.org/', } self.m_cookiejar = requests.cookies.RequestsCookieJar() for cookie in COOKIES.split(';'): key,value = cookie.split('=',1) self.m_cookiejar.set(key,value) except: print('init error!!!') def getOverView(self): try: req = self.m_session.get('https://www.aisinei.org/portal.php',headers=self.m_headers, cookies=self.m_cookiejar, timeout=5) classattrs={'class':'bus_vtem'} soup = BeautifulSoup(req.content.decode('utf-8'),'lxml') buslist = soup.find_all(attrs=classattrs) #print(len(buslist)) for item in buslist: if(item.a.attrs['title'] == "紧急通知!紧急通知!紧急通知!"): continue print(item.a.attrs['title']) print(item.a.attrs['href']) time.sleep(1) pass except: print('get over view error') if __name__ == "__main__": asscrapy = AsScrapy() asscrapy.getOverView()
抓取并分析出地址如下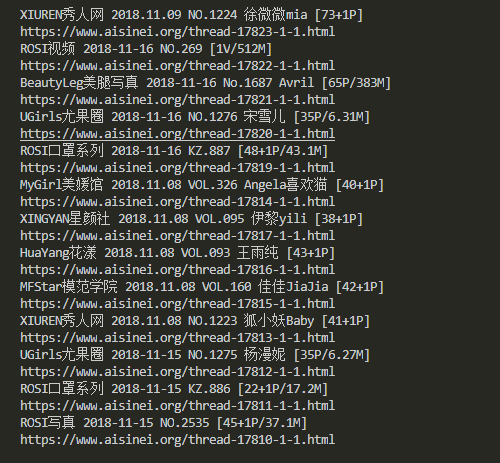
下一篇讲如何利用ajax分析动态网址,实战抓取今日头条的cosplay图片
谢谢关注我的公众号

 浙公网安备 33010602011771号
浙公网安备 33010602011771号